ParallelWaveGAN
Version 0.6.1
ที่เก็บนี้ให้การใช้งาน pytorch อย่างไม่เป็นทางการ ของรุ่นต่อไปนี้:
คุณสามารถรวมโมเดลที่ไม่ล้ำสมัยเหล่านี้เพื่อสร้างคำสั่งที่ยอดเยี่ยมของคุณเอง!
โปรดตรวจสอบตัวอย่างของเราในการสาธิต HP ของเรา
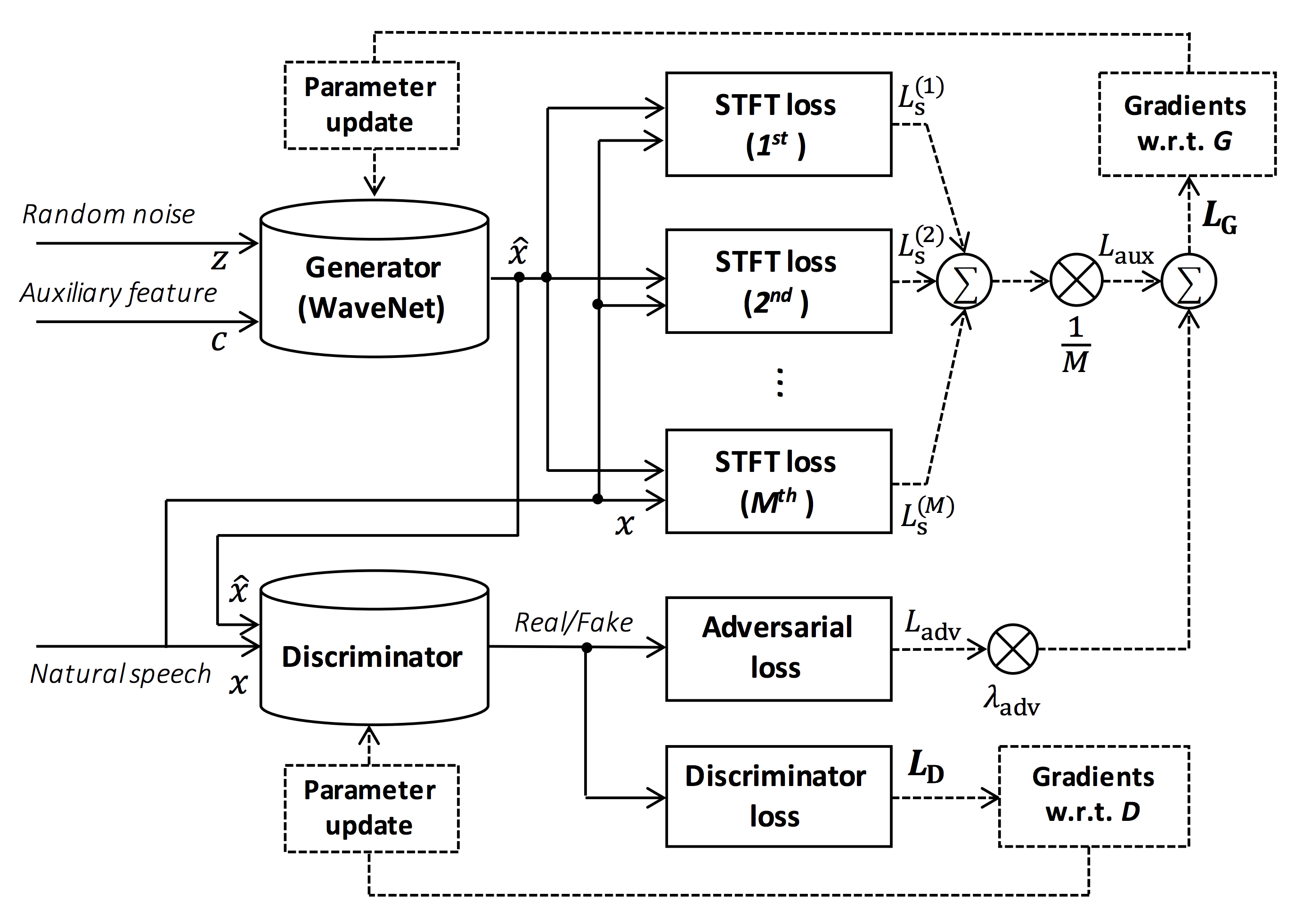
แหล่งที่มาของรูป: https://arxiv.org/pdf/1910.11480.pdf
เป้าหมายของพื้นที่เก็บข้อมูลนี้คือการจัดหานักร้องประสาทแบบเรียลไทม์ซึ่งเข้ากันได้กับ ESPNET-TTS
นอกจากนี้พื้นที่เก็บข้อมูลนี้สามารถรวมกับการใช้งานที่ใช้ NVIDIA/TACOTRON2 (ดูความคิดเห็นนี้)
คุณสามารถลองใช้การสาธิตการสังเคราะห์การพูดคุยด้วยเสียงแบบ end-to-to-to-to-to-to-end และร้องเพลงใน Google Colab!
ที่เก็บนี้ได้รับการทดสอบใน Ubuntu 20.04 ด้วย GPU Titan V.
sudo apt install libsndfile-dev ใน Ubuntu)sudo apt install jq ใน Ubuntu)sudo apt install sox ใน Ubuntu) รุ่น CUDA ที่แตกต่างกันควรใช้งานได้ แต่ไม่ได้ทดสอบอย่างชัดเจน
รหัสทั้งหมดได้รับการทดสอบใน Pytorch 1.8.1, 1.9, 1.10.2, 1.11.0, 1.12.1, 1.13.1, 2.0.1 และ 2.1.0
คุณสามารถเลือกวิธีการติดตั้งจากสองทางเลือก
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN
$ pip install -e .
# If you want to use distributed training, please install
# apex manually by following https://github.com/NVIDIA/apex
$ ... โปรดทราบว่าเวอร์ชัน CUDA ของคุณจะต้องตรงกับเวอร์ชันที่ใช้สำหรับ Pytorch Binary เพื่อติดตั้ง Apex
ในการติดตั้ง Pytorch ที่รวบรวมด้วย CUDA รุ่นที่แตกต่างกันให้ดู tools/Makefile
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN/tools
$ make
# If you want to use distributed training, please run following
# command to install apex.
$ make apex โปรดทราบว่าเราระบุรุ่น CUDA ที่ใช้ในการรวบรวมล้อ Pytorch
หากคุณต้องการใช้รุ่น CUDA ที่แตกต่างกันโปรดตรวจสอบ tools/Makefile เพื่อเปลี่ยนล้อ Pytorch ที่จะติดตั้ง
ที่เก็บนี้ให้สูตรสไตล์ Kaldi เช่นเดียวกับ ESPNET
ปัจจุบันสูตรต่อไปนี้ได้รับการสนับสนุน
ในการเรียกใช้สูตรโปรดทำตามคำแนะนำด้านล่าง
# Let us move on the recipe directory
$ cd egs/ljspeech/voc1
# Run the recipe from scratch
$ ./run.sh
# You can change config via command line
$ ./run.sh --conf < your_customized_yaml_config >
# You can select the stage to start and stop
$ ./run.sh --stage 2 --stop_stage 2
# If you want to specify the gpu
$ CUDA_VISIBLE_DEVICES=1 ./run.sh --stage 2
# If you want to resume training from 10000 steps checkpoint
$ ./run.sh --stage 2 --resume < path > / < to > /checkpoint-10000steps.pklดูข้อมูลเพิ่มเติมเกี่ยวกับสูตรอาหารใน readme นี้
ความเร็วในการถอดรหัสคือ RTF = 0.016 ด้วย Titan V เร็วกว่าแบบเรียลไทม์มาก
[decode]: 100% | ██████████ | 250/250 [00: 30< 00:00, 8.31it/s, RTF = 0.0156]
2019-11-03 09:07:40,480 (decode:127) INFO: finished generation of 250 utterances (RTF = 0.016).แม้ใน CPU (Intel (R) Xeon (R) Gold 6154 CPU @ 3.00GHz 16 เธรด) มันสามารถสร้างน้อยกว่าแบบเรียลไทม์
[decode]: 100% | ██████████ | 250/250 [22: 16< 00:00, 5.35s/it, RTF = 0.841]
2019-11-06 09:04:56,697 (decode:129) INFO: finished generation of 250 utterances (RTF = 0.734).หากคุณใช้เครื่องกำเนิดไฟฟ้าของ Melgan ความเร็วในการถอดรหัสจะเร็วขึ้น
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [04: 00< 00:00, 1.04it/s, RTF = 0.0882]
2020-02-08 10:45:14,111 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.137).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 06< 00:00, 36.38it/s, RTF = 0.00189]
2020-02-08 05:44:42,231 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.002).หากคุณใช้เครื่องกำเนิดไฟฟ้าของ Multi-Band Melgan ความเร็วในการถอดรหัสจะเร็วขึ้นอีกมาก
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [01: 47< 00:00, 2.95it/s, RTF = 0.048]
2020-05-22 15:37:19,771 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.059).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 05< 00:00, 43.67it/s, RTF = 0.000928]
2020-05-22 15:35:13,302 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.001). หากคุณต้องการเร่งการอนุมานมากขึ้นมันก็คุ้มค่าที่จะลองแปลงจาก Pytorch เป็น Tensorflow
ตัวอย่างของการแปลงมีอยู่ในสมุดบันทึก (จัดทำโดย @dathudeptrai)
ที่นี่ผลลัพธ์จะสรุปไว้ในตาราง
คุณสามารถฟังตัวอย่างและดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมจากลิงค์ไปยัง Google Drive ของเรา
| แบบอย่าง | คร่ำครวญ | หรั่ง | FS [Hz] | Mel Range [Hz] | fft / hop / win [pt] | # iters |
|---|---|---|---|---|---|---|
| ljspeech_parallel_wavegan.v1 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 400K |
| ljspeech_parallel_wavegan.v1.long | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 1m |
| ljspeech_parallel_wavegan.v1.no_limit | การเชื่อมโยง | en | 22.05K | ไม่มี | 1024/256 / NONE | 400K |
| ljspeech_parallel_wavegan.v3 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 3m |
| ljspeech_melgan.v1 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 400K |
| ljspeech_melgan.v1.long | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 1m |
| ljspeech_melgan_large.v1 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 400K |
| ljspeech_melgan_large.v1.long | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 1m |
| ljspeech_melgan.v3 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 2m |
| ljspeech_melgan.v3.long | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 4m |
| ljspeech_full_band_melgan.v1 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 1m |
| ljspeech_full_band_melgan.v2 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 1m |
| ljspeech_multi_band_melgan.v1 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 1m |
| ljspeech_multi_band_melgan.v2 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 1m |
| ljspeech_hifigan.v1 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 2.5m |
| ljspeech_style_melgan.v1 | การเชื่อมโยง | en | 22.05K | 80-7600 | 1024/256 / NONE | 1.5m |
| jsut_parallel_wavegan.v1 | การเชื่อมโยง | JP | 24K | 80-7600 | 2048/300/200 | 400K |
| jsut_multi_band_melgan.v2 | การเชื่อมโยง | JP | 24K | 80-7600 | 2048/300/200 | 1m |
| just_hifigan.v1 | การเชื่อมโยง | JP | 24K | 80-7600 | 2048/300/200 | 2.5m |
| just_style_melgan.v1 | การเชื่อมโยง | JP | 24K | 80-7600 | 2048/300/200 | 1.5m |
| csmsc_parallel_wavegan.v1 | การเชื่อมโยง | zh | 24K | 80-7600 | 2048/300/200 | 400K |
| csmsc_multi_band_melgan.v2 | การเชื่อมโยง | zh | 24K | 80-7600 | 2048/300/200 | 1m |
| csmsc_hifigan.v1 | การเชื่อมโยง | zh | 24K | 80-7600 | 2048/300/200 | 2.5m |
| csmsc_style_melgan.v1 | การเชื่อมโยง | zh | 24K | 80-7600 | 2048/300/200 | 1.5m |
| Arctic_slt_parallel_wavegan.v1 | การเชื่อมโยง | en | 16k | 80-7600 | 1024/256 / NONE | 400K |
| jnas_parallel_wavegan.v1 | การเชื่อมโยง | JP | 16k | 80-7600 | 1024/256 / NONE | 400K |
| vctk_parallel_wavegan.v1 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 400K |
| vctk_parallel_wavegan.v1.long | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 1m |
| vctk_multi_band_melgan.v2 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 1m |
| vctk_hifigan.v1 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 2.5m |
| vctk_style_melgan.v1 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 1.5m |
| libritts_parallel_wavegan.v1 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 400K |
| libritts_parallel_wavegan.v1.long | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 1m |
| libritts_multi_band_melgan.v2 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 1m |
| Libritts_hifigan.v1 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 2.5m |
| Libritts_style_melgan.v1 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 1.5m |
| kss_parallel_wavegan.v1 | การเชื่อมโยง | โค | 24K | 80-7600 | 2048/300/200 | 400K |
| hui_acg_hokuspokus_parallel_wavegan.v1 | การเชื่อมโยง | เดอ | 24K | 80-7600 | 2048/300/200 | 400K |
| ruslan_parallel_wavegan.v1 | การเชื่อมโยง | ร. | 24K | 80-7600 | 2048/300/200 | 400K |
| oniku_hifigan.v1 | การเชื่อมโยง | JP | 24K | 80-7600 | 2048/300/200 | 250k |
| kiritan_hifigan.v1 | การเชื่อมโยง | JP | 24K | 80-7600 | 2048/300/200 | 300K |
| OFUTON_HIFIGAN.V1 | การเชื่อมโยง | JP | 24K | 80-7600 | 2048/300/200 | 300K |
| opencpop_hifigan.v1 | การเชื่อมโยง | zh | 24K | 80-7600 | 2048/300/200 | 250k |
| csd_english_hifigan.v1 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 300K |
| csd_korean_hifigan.v1 | การเชื่อมโยง | en | 24K | 80-7600 | 2048/300/200 | 250k |
| kising_hifigan.v1 | การเชื่อมโยง | zh | 24K | 80-7600 | 2048/300/200 | 300K |
| m4singer_hifigan.v1 | การเชื่อมโยง | zh | 24K | 80-7600 | 2048/300/200 | 1m |
โปรดเข้าถึงที่ Google Drive ของเราเพื่อตรวจสอบผลลัพธ์เพิ่มเติม
โปรดตรวจสอบใบอนุญาตของฐานข้อมูล (เช่นไม่ว่าจะเหมาะสมสำหรับการใช้งานเชิงพาณิชย์) ก่อนที่จะใช้โมเดลที่ผ่านการฝึกอบรมมาก่อน
ผู้เขียนจะไม่รับผิดชอบต่อการสูญเสียใด ๆ เนื่องจากการใช้แบบจำลองและข้อพิพาททางกฎหมายเกี่ยวกับการใช้ชุดข้อมูล
ที่นี่รหัสน้อยที่สุดจะแสดงเพื่อดำเนินการสังเคราะห์การวิเคราะห์โดยใช้แบบจำลองก่อนหน้า
# Please make sure you installed `parallel_wavegan`
# If not, please install via pip
$ pip install parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# Now you can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above results
# Please put an audio file in `sample` directory to perform analysis-synthesis
$ ls sample/
sample.wav
# Then perform feature extraction -> feature normalization -> synthesis
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-normalize
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir dump/sample/raw
--dumpdir dump/sample/norm
--stats pretrain_model/ < pretrain_model_tag > /stats.h5
2019-11-13 13:44:29,574 (normalize:87) INFO: the number of files = 1.
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 513.13it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/norm
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# You can skip normalization step (on-the-fly normalization, feature extraction -> synthesis)
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/raw
--normalize-before
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# you can find the generated speech in `sample` directory
$ ls sample
sample.wav sample_gen.wavที่นี่ฉันแสดงขั้นตอนในการสร้างรูปคลื่นด้วยคุณสมบัติที่สร้างโดยรุ่น ESPNET-TTS
# Make sure you already finished running the recipe of ESPnet-TTS.
# You must use the same feature settings for both Text2Mel and Mel2Wav models.
# Let us move on "ESPnet" recipe directory
$ cd /path/to/espnet/egs/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs/ < recipe_name > /tts1
# If you use ESPnet2, move on `egs2/`
$ cd /path/to/espnet/egs2/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs2/ < recipe_name > /tts1
# Please install this repository in ESPnet conda (or virtualenv) environment
$ . ./path.sh && pip install -U parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# You can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above resultsกรณีที่ 1 : หากคุณใช้ชุดข้อมูลเดียวกันสำหรับทั้ง text2mel และ mel2wav
# In this case, you can directly use generated features for decoding.
# Please specify `feats.scp` path for `--feats-scp`, which is located in
# exp/<your_model_dir>/outputs_*_decode/<set_name>/feats.scp.
# Note that do not use outputs_*decode_denorm/<set_name>/feats.scp since
# it is de-normalized features (the input for PWG is normalized features).
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode/ < set_name > /feats.scp
--outdir < path_to_outdir >
# In the case of ESPnet2, the generated feature can be found in
# exp/<your_model_dir>/decode_*/<set_name>/norm/feats.scp.
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /norm/feats.scp
--outdir < path_to_outdir >
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavกรณีที่ 2 : หากคุณใช้ชุดข้อมูลที่แตกต่างกันสำหรับรุ่น text2mel และ mel2wav
# In this case, you must provide `--normalize-before` option additionally.
# And use `feats.scp` of de-normalized generated features.
# ESPnet1 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode_denorm/ < set_name > /feats.scp
--outdir < path_to_outdir >
--normalize-before
# ESPnet2 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /denorm/feats.scp
--outdir < path_to_outdir >
--normalize-before
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavหากคุณต้องการรวมโมเดลเหล่านี้ใน Python คุณสามารถลองสาธิตการสาธิตแบบเรียลไทม์ใน Google Colab!
บางครั้งเราต้องการถอดรหัสด้วยไฟล์ NPY ที่ทิ้งซึ่งเป็น mel-spectrogram ที่สร้างขึ้นโดยรุ่น TTS โปรดตรวจสอบให้แน่ใจว่าคุณใช้การตั้งค่าการสกัดฟีเจอร์เดียวกันของ Vocoder ที่ผ่านการฝึกฝน ( fs , fft_size , hop_size , win_length , fmin และ fmax )
เฉพาะความแตกต่างของ log_base เท่านั้นที่สามารถเปลี่ยนแปลงได้ด้วยการโพสต์โพสต์บางอย่าง (เราใช้บันทึก 10 แทนบันทึกธรรมชาติเป็นค่าเริ่มต้น) ดูรายละเอียดในความคิดเห็น
# Generate dummy npy file of mel-spectrogram
$ ipython
[ins] In [1]: import numpy as np
[ins] In [2]: x = np.random.randn(512, 80) # (#frames, #mels)
[ins] In [3]: np.save( " dummy_1.npy " , x)
[ins] In [4]: y = np.random.randn(256, 80) # (#frames, #mels)
[ins] In [5]: np.save( " dummy_2.npy " , y)
[ins] In [6]: exit
# Make scp file (key-path format)
$ find -name " *.npy " | awk ' {print "dummy_" NR " " $1} ' > feats.scp
# Check (<utt_id> <path>)
$ cat feats.scp
dummy_1 ./dummy_1.npy
dummy_2 ./dummy_2.npy
# Decode without feature normalization
# This case assumes that the input mel-spectrogram is normalized with the same statistics of the pretrained model.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).
# Decode with feature normalization
# This case assumes that the input mel-spectrogram is not normalized.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--normalize-before
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).ผู้เขียนขอขอบคุณ Ryuichi Yamamoto (@R9Y9) สำหรับที่เก็บกระดาษและการอภิปรายที่มีค่าของเขา
Tomoki Hayashi (@kan-bayashi)
อีเมล: hayashi.tomoki<at>g.sp.m.is.nagoya-u.ac.jp


