ParallelWaveGAN
Version 0.6.1
يوفر هذا المستودع تطبيقات Pytorch غير رسمية للنماذج التالية:
يمكنك الجمع بين هذه النماذج غير الحكومية غير المقلدة لبناء Vocoder الرائع الخاص بك!
يرجى التحقق من عيناتنا في العرض التجريبي HP.
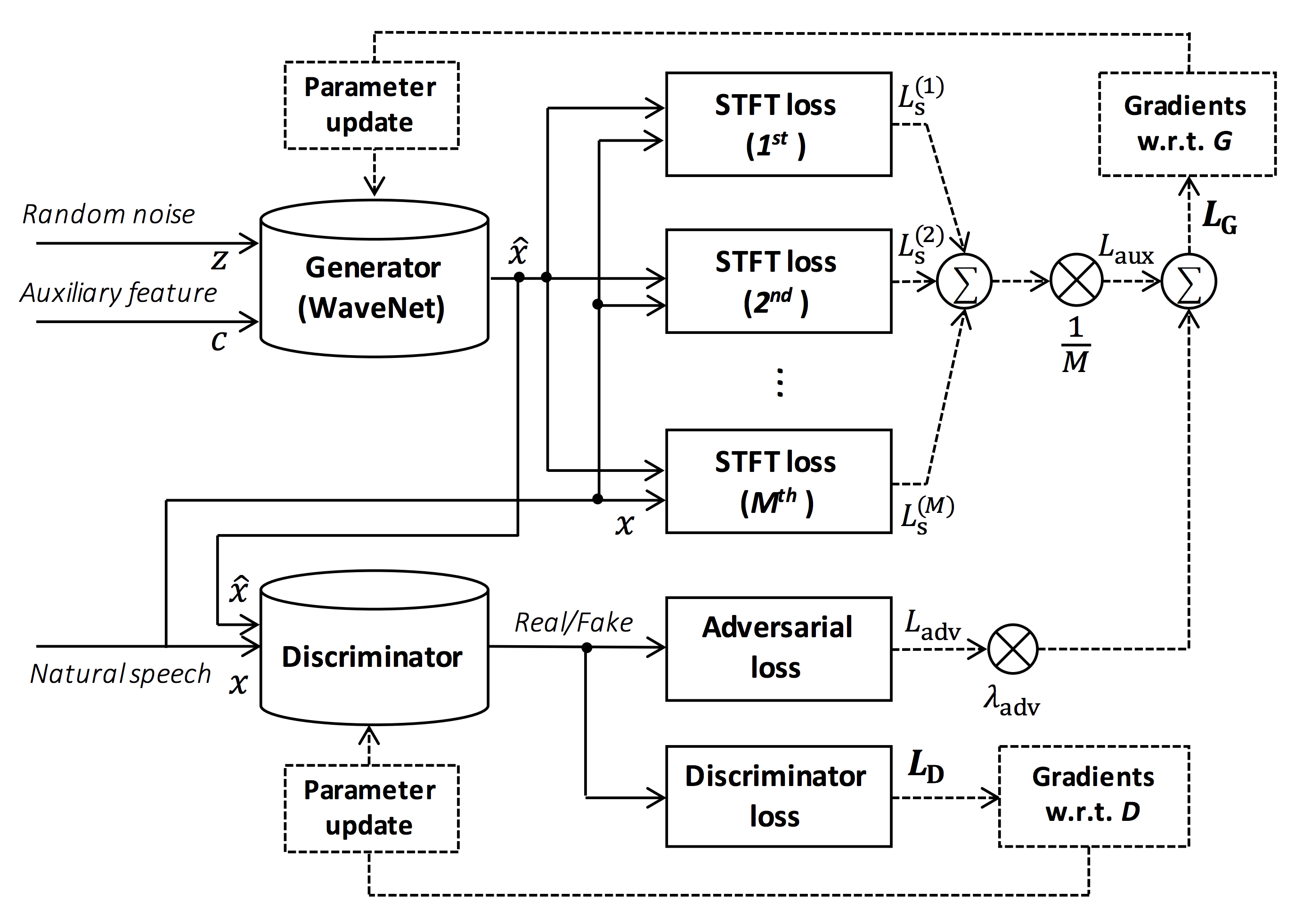
مصدر الشكل: https://arxiv.org/pdf/1910.11480.pdf
الهدف من هذا المستودع هو توفير Vocoder العصبي في الوقت الفعلي ، وهو متوافق مع ESPNET-TTS.
أيضًا ، يمكن دمج هذا المستودع مع التنفيذ المستند إلى NVIDIA/TACOTRON2 (انظر هذا التعليق).
يمكنك تجربة العرض التوضيحي الصوتي في الوقت الفعلي في الوقت الفعلي والغناء في Google Colab!
يتم اختبار هذا المستودع على Ubuntu 20.04 مع GPU Titan V.
sudo apt install libsndfile-dev في ubuntu)sudo apt install jq في Ubuntu)sudo apt install sox في Ubuntu) يجب أن يكون إصدار CUDA مختلفًا يعمل ولكن لم يتم اختباره بشكل صريح.
يتم اختبار جميع الرموز على Pytorch 1.8.1 ، 1.9 ، 1.10.2 ، 1.11.0 ، 1.12.1 ، 1.13.1 ، 2.0.1 و 2.1.0.
يمكنك تحديد طريقة التثبيت من بديلين.
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN
$ pip install -e .
# If you want to use distributed training, please install
# apex manually by following https://github.com/NVIDIA/apex
$ ... لاحظ أنه يجب مطابقة إصدار CUDA الخاص بك تمامًا مع الإصدار المستخدم لـ Pytorch Binary لتثبيت Apex.
لتثبيت Pytorch المترجمة مع إصدار CUDA مختلف ، انظر tools/Makefile .
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN/tools
$ make
# If you want to use distributed training, please run following
# command to install apex.
$ make apex لاحظ أننا نحدد إصدار CUDA المستخدم لتجميع عجلة Pytorch.
إذا كنت ترغب في استخدام إصدار CUDA مختلف ، فيرجى التحقق من tools/Makefile لتغيير عجلة Pytorch المراد تثبيتها.
يوفر هذا المستودع وصفات Kaldi-Style ، مثل ESPNET.
حاليًا ، يتم دعم الوصفات التالية.
لتشغيل الوصفة ، يرجى اتباع التعليمات أدناه.
# Let us move on the recipe directory
$ cd egs/ljspeech/voc1
# Run the recipe from scratch
$ ./run.sh
# You can change config via command line
$ ./run.sh --conf < your_customized_yaml_config >
# You can select the stage to start and stop
$ ./run.sh --stage 2 --stop_stage 2
# If you want to specify the gpu
$ CUDA_VISIBLE_DEVICES=1 ./run.sh --stage 2
# If you want to resume training from 10000 steps checkpoint
$ ./run.sh --stage 2 --resume < path > / < to > /checkpoint-10000steps.pklشاهد المزيد من المعلومات حول الوصفات في هذه القراءة.
سرعة فك التشفير هي RTF = 0.016 مع Titan V ، أسرع بكثير من الوقت الفعلي.
[decode]: 100% | ██████████ | 250/250 [00: 30< 00:00, 8.31it/s, RTF = 0.0156]
2019-11-03 09:07:40,480 (decode:127) INFO: finished generation of 250 utterances (RTF = 0.016).حتى في وحدة المعالجة المركزية (Intel (R) Xeon (R) Gold 6154 CPU @ 3.00GHz 16) ، يمكن أن يولد أقل من الوقت الفعلي.
[decode]: 100% | ██████████ | 250/250 [22: 16< 00:00, 5.35s/it, RTF = 0.841]
2019-11-06 09:04:56,697 (decode:129) INFO: finished generation of 250 utterances (RTF = 0.734).إذا كنت تستخدم مولد Melgan ، فستكون سرعة فك التشفير بشكل أسرع.
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [04: 00< 00:00, 1.04it/s, RTF = 0.0882]
2020-02-08 10:45:14,111 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.137).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 06< 00:00, 36.38it/s, RTF = 0.00189]
2020-02-08 05:44:42,231 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.002).إذا كنت تستخدم مولد Multi Band Melgan ، فستكون سرعة فك التشفير بشكل أسرع بكثير.
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [01: 47< 00:00, 2.95it/s, RTF = 0.048]
2020-05-22 15:37:19,771 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.059).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 05< 00:00, 43.67it/s, RTF = 0.000928]
2020-05-22 15:35:13,302 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.001). إذا كنت ترغب في تسريع الاستدلال أكثر ، فمن المفيد تجربة التحويل من Pytorch إلى TensorFlow.
يتوفر مثال التحويل في دفتر الملاحظات (المقدم من dathudeptrai).
هنا يتم تلخيص النتائج في الجدول.
يمكنك الاستماع إلى العينات وتنزيل النماذج المسبقة من الرابط إلى Google Drive.
| نموذج | كونك | لانغ | FS [هرتز] | MEL Range [HZ] | FFT / HOP / WIN [PT] | # iters |
|---|---|---|---|---|---|---|
| ljspeech_paralled_wavegan.v1 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 400 كيلو |
| ljspeech_paralled_wavegan.v1.long | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 1M |
| ljspeech_paralled_wavegan.v1.no_limit | وصلة | en | 22.05k | لا أحد | 1024 /256 / لا شيء | 400 كيلو |
| LJSPEEDE_PARALL_WAVEGAN.V3 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 3M |
| ljspeech_melgan.v1 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 400 كيلو |
| ljspeech_melgan.v1.long | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 1M |
| ljspeech_melgan_large.v1 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 400 كيلو |
| ljspeech_melgan_large.v1.long | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 1M |
| ljspeech_melgan.v3 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 2 م |
| ljspeech_melgan.v3.long | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 4M |
| ljspeech_full_band_melgan.v1 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 1M |
| ljspeech_full_band_melgan.v2 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 1M |
| ljspeech_multi_band_melgan.v1 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 1M |
| ljspeech_multi_band_melgan.v2 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 1M |
| ljspeech_hifigan.v1 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 2.5m |
| ljspeech_style_melgan.v1 | وصلة | en | 22.05k | 80-7600 | 1024 /256 / لا شيء | 1.5m |
| jsut_paralled_wavegan.v1 | وصلة | JP | 24k | 80-7600 | 2048 / 300/1200 | 400 كيلو |
| jsut_multi_band_melgan.v2 | وصلة | JP | 24k | 80-7600 | 2048 / 300/1200 | 1M |
| Just_Hifigan.v1 | وصلة | JP | 24k | 80-7600 | 2048 / 300/1200 | 2.5m |
| just_style_melgan.v1 | وصلة | JP | 24k | 80-7600 | 2048 / 300/1200 | 1.5m |
| CSMSC_PARALL_WAVEGAN.V1 | وصلة | ZH | 24k | 80-7600 | 2048 / 300/1200 | 400 كيلو |
| CSMSC_MULTI_BAND_MELGAN.V2 | وصلة | ZH | 24k | 80-7600 | 2048 / 300/1200 | 1M |
| CSMSC_HIFIGAN.V1 | وصلة | ZH | 24k | 80-7600 | 2048 / 300/1200 | 2.5m |
| CSMSC_STYLE_MELGAN.V1 | وصلة | ZH | 24k | 80-7600 | 2048 / 300/1200 | 1.5m |
| ARCTIC_SLT_PARALL_WAVEGAN.V1 | وصلة | en | 16 كيلو | 80-7600 | 1024 /256 / لا شيء | 400 كيلو |
| jnas_paralled_wavegan.v1 | وصلة | JP | 16 كيلو | 80-7600 | 1024 /256 / لا شيء | 400 كيلو |
| vctk_paralled_wavegan.v1 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 400 كيلو |
| vctk_paralled_wavegan.v1.long | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 1M |
| vctk_multi_band_melgan.v2 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 1M |
| VCTK_HIFIGAN.V1 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 2.5m |
| vctk_style_melgan.v1 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 1.5m |
| libritts_paralled_wavegan.v1 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 400 كيلو |
| libritts_paralled_wavegan.v1.long | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 1M |
| libritts_multi_band_melgan.v2 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 1M |
| libritts_hifigan.v1 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 2.5m |
| libritts_style_melgan.v1 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 1.5m |
| kss_paralled_wavegan.v1 | وصلة | كو | 24k | 80-7600 | 2048 / 300/1200 | 400 كيلو |
| hui_acg_hokuspokus_paralled_wavegan.v1 | وصلة | دي | 24k | 80-7600 | 2048 / 300/1200 | 400 كيلو |
| ruslan_paralled_wavegan.v1 | وصلة | رو | 24k | 80-7600 | 2048 / 300/1200 | 400 كيلو |
| oniku_hifigan.v1 | وصلة | JP | 24k | 80-7600 | 2048 / 300/1200 | 250k |
| Kiritan_Hifigan.v1 | وصلة | JP | 24k | 80-7600 | 2048 / 300/1200 | 300K |
| ofuton_Hifigan.v1 | وصلة | JP | 24k | 80-7600 | 2048 / 300/1200 | 300K |
| opencpop_hifigan.v1 | وصلة | ZH | 24k | 80-7600 | 2048 / 300/1200 | 250k |
| csd_english_hifigan.v1 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 300K |
| CSD_KOREAN_HIFIGAN.V1 | وصلة | en | 24k | 80-7600 | 2048 / 300/1200 | 250k |
| kising_hifigan.v1 | وصلة | ZH | 24k | 80-7600 | 2048 / 300/1200 | 300K |
| m4singer_hifigan.v1 | وصلة | ZH | 24k | 80-7600 | 2048 / 300/1200 | 1M |
يرجى الوصول إلى Google Drive الخاص بنا للتحقق من المزيد من النتائج.
يرجى التحقق من ترخيص قاعدة البيانات (على سبيل المثال ، سواء كان من المناسب الاستخدام التجاري) قبل استخدام النموذج الذي تم تدريبه مسبقًا.
لن يكون المؤلفون مسؤولين عن أي خسارة بسبب استخدام النموذج والنزاعات القانونية المتعلقة باستخدام مجموعة البيانات.
هنا يظهر رمز الحد الأدنى لإجراء عملية تكوين التحليل باستخدام النموذج المسبق.
# Please make sure you installed `parallel_wavegan`
# If not, please install via pip
$ pip install parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# Now you can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above results
# Please put an audio file in `sample` directory to perform analysis-synthesis
$ ls sample/
sample.wav
# Then perform feature extraction -> feature normalization -> synthesis
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-normalize
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir dump/sample/raw
--dumpdir dump/sample/norm
--stats pretrain_model/ < pretrain_model_tag > /stats.h5
2019-11-13 13:44:29,574 (normalize:87) INFO: the number of files = 1.
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 513.13it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/norm
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# You can skip normalization step (on-the-fly normalization, feature extraction -> synthesis)
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/raw
--normalize-before
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# you can find the generated speech in `sample` directory
$ ls sample
sample.wav sample_gen.wavهنا ، أعرض الإجراء لإنشاء أشكال موجية مع ميزات تم إنشاؤها بواسطة نماذج ESPNET-TTS.
# Make sure you already finished running the recipe of ESPnet-TTS.
# You must use the same feature settings for both Text2Mel and Mel2Wav models.
# Let us move on "ESPnet" recipe directory
$ cd /path/to/espnet/egs/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs/ < recipe_name > /tts1
# If you use ESPnet2, move on `egs2/`
$ cd /path/to/espnet/egs2/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs2/ < recipe_name > /tts1
# Please install this repository in ESPnet conda (or virtualenv) environment
$ . ./path.sh && pip install -U parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# You can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above resultsالحالة 1 : إذا كنت تستخدم نفس مجموعة البيانات لكل من text2mel و mel2wav
# In this case, you can directly use generated features for decoding.
# Please specify `feats.scp` path for `--feats-scp`, which is located in
# exp/<your_model_dir>/outputs_*_decode/<set_name>/feats.scp.
# Note that do not use outputs_*decode_denorm/<set_name>/feats.scp since
# it is de-normalized features (the input for PWG is normalized features).
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode/ < set_name > /feats.scp
--outdir < path_to_outdir >
# In the case of ESPnet2, the generated feature can be found in
# exp/<your_model_dir>/decode_*/<set_name>/norm/feats.scp.
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /norm/feats.scp
--outdir < path_to_outdir >
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavالحالة 2 : إذا كنت تستخدم مجموعات بيانات مختلفة لنماذج Text2mel و Mel2wav
# In this case, you must provide `--normalize-before` option additionally.
# And use `feats.scp` of de-normalized generated features.
# ESPnet1 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode_denorm/ < set_name > /feats.scp
--outdir < path_to_outdir >
--normalize-before
# ESPnet2 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /denorm/feats.scp
--outdir < path_to_outdir >
--normalize-before
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavإذا كنت ترغب في الجمع بين هذه النماذج في Python ، فيمكنك تجربة العرض التوضيحي في الوقت الفعلي في Google Colab!
في بعض الأحيان ، نريد فك تشفير ملفات NPY مغمورة ، والتي يتم إنشاؤها بواسطة نماذج TTS. يرجى التأكد من استخدام إعدادات استخراج الميزات نفسها للمتفرج المسبق ( fs و fft_size و hop_size و win_length و fmin و fmax ).
يمكن تغيير اختلاف log_base فقط مع بعض عمليات ما بعد المعالجة (نستخدم log 10 بدلاً من السجل الطبيعي باعتباره افتراضيًا). انظر التفاصيل في التعليق.
# Generate dummy npy file of mel-spectrogram
$ ipython
[ins] In [1]: import numpy as np
[ins] In [2]: x = np.random.randn(512, 80) # (#frames, #mels)
[ins] In [3]: np.save( " dummy_1.npy " , x)
[ins] In [4]: y = np.random.randn(256, 80) # (#frames, #mels)
[ins] In [5]: np.save( " dummy_2.npy " , y)
[ins] In [6]: exit
# Make scp file (key-path format)
$ find -name " *.npy " | awk ' {print "dummy_" NR " " $1} ' > feats.scp
# Check (<utt_id> <path>)
$ cat feats.scp
dummy_1 ./dummy_1.npy
dummy_2 ./dummy_2.npy
# Decode without feature normalization
# This case assumes that the input mel-spectrogram is normalized with the same statistics of the pretrained model.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).
# Decode with feature normalization
# This case assumes that the input mel-spectrogram is not normalized.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--normalize-before
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).يود المؤلف أن يشكر Ryuichi Yamamoto (@R9Y9) على مستودعه العظيم والورق والمناقشات القيمة.
توموكي هاياشي (@kan-bayashi)
البريد الإلكتروني: hayashi.tomoki<at>g.sp.m.is.nagoya-u.ac.jp


