ParallelWaveGAN
Version 0.6.1
Ce référentiel fournit des implémentations Pytorch non officielles des modèles suivants:
Vous pouvez combiner ces modèles non autorégressifs de pointe pour construire votre propre grand vocodeur!
Veuillez vérifier nos échantillons dans notre démo HP.
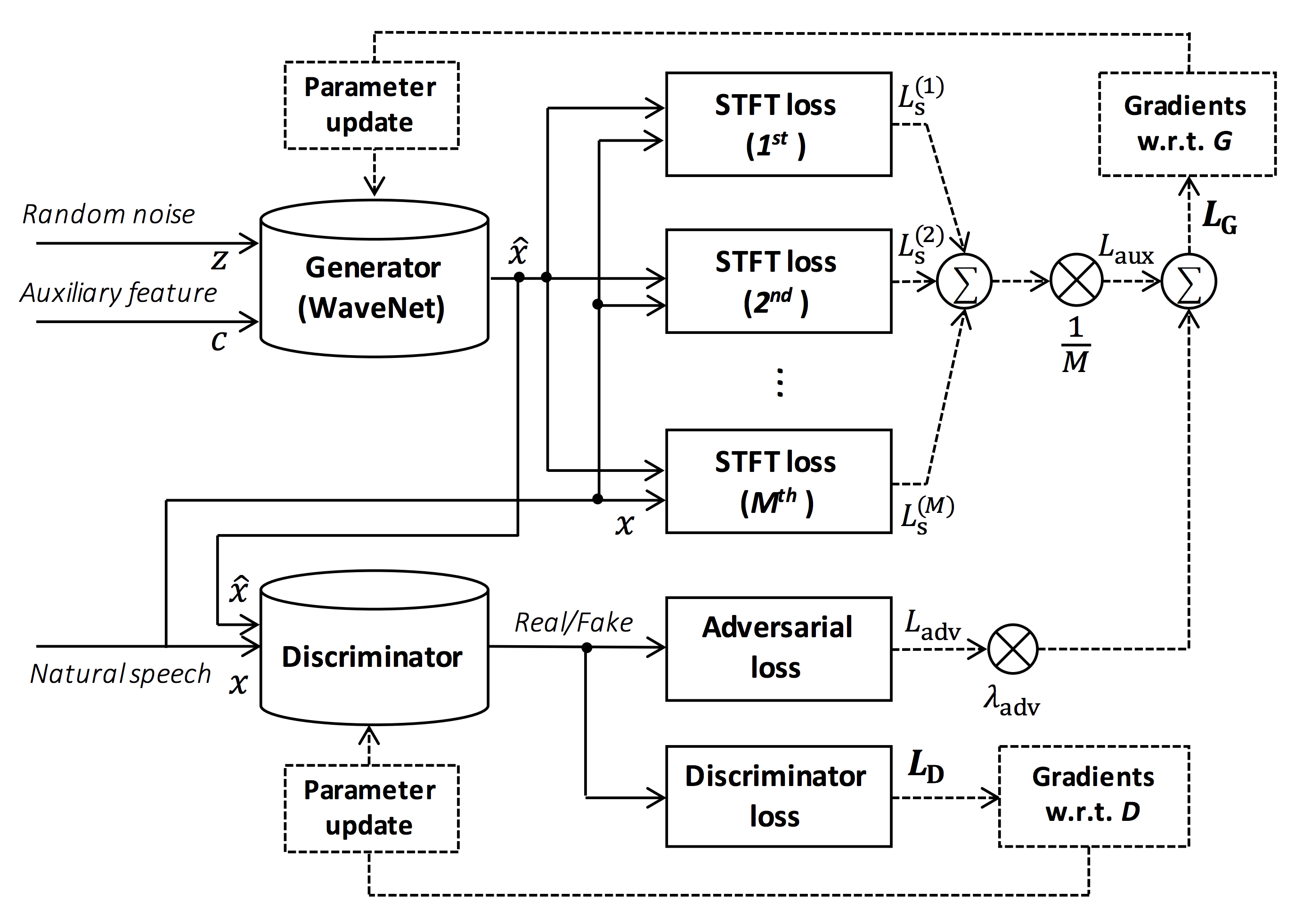
Source de la figure: https://arxiv.org/pdf/1910.11480.pdf
L'objectif de ce référentiel est de fournir un vocodeur neuronal en temps réel, qui est compatible avec ESPNET-TTS.
De plus, ce référentiel peut être combiné avec l'implémentation basée sur NVIDIA / TACOTRON2 (voir ce commentaire).
Vous pouvez essayer la démonstration de synthèse de la synthèse vocale de bout en bout en temps réel dans Google Colab!
Ce référentiel est testé sur Ubuntu 20.04 avec un GPU Titan V.
sudo apt install libsndfile-dev in ubuntu)sudo apt install jq in ubuntu)sudo apt install sox dans Ubuntu) Différentes version CUDA devraient fonctionner mais pas explicitement testées.
Tous les codes sont testés sur Pytorch 1.8.1, 1.9, 1.10.2, 1.11.0, 1.12.1, 1.13.1, 2.0.1 et 2.1.0.
Vous pouvez sélectionner la méthode d'installation à partir de deux alternatives.
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN
$ pip install -e .
# If you want to use distributed training, please install
# apex manually by following https://github.com/NVIDIA/apex
$ ... Notez que votre version CUDA doit être exactement adaptée à la version utilisée pour le binaire Pytorch pour installer Apex.
Pour installer Pytorch compilé avec différentes version CUDA, voir tools/Makefile .
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN/tools
$ make
# If you want to use distributed training, please run following
# command to install apex.
$ make apex Notez que nous spécifions la version CUDA utilisée pour compiler la roue Pytorch.
Si vous souhaitez utiliser différentes version CUDA, veuillez vérifier tools/Makefile pour modifier la roue Pytorch à installer.
Ce référentiel fournit des recettes de style Kaldi, comme le même que ESPNET.
Actuellement, les recettes suivantes sont prises en charge.
Pour exécuter la recette, veuillez suivre l'instruction ci-dessous.
# Let us move on the recipe directory
$ cd egs/ljspeech/voc1
# Run the recipe from scratch
$ ./run.sh
# You can change config via command line
$ ./run.sh --conf < your_customized_yaml_config >
# You can select the stage to start and stop
$ ./run.sh --stage 2 --stop_stage 2
# If you want to specify the gpu
$ CUDA_VISIBLE_DEVICES=1 ./run.sh --stage 2
# If you want to resume training from 10000 steps checkpoint
$ ./run.sh --stage 2 --resume < path > / < to > /checkpoint-10000steps.pklVoir plus d'informations sur les recettes de cette lecture.
La vitesse de décodage est RTF = 0,016 avec Titan V, beaucoup plus rapide que le temps réel.
[decode]: 100% | ██████████ | 250/250 [00: 30< 00:00, 8.31it/s, RTF = 0.0156]
2019-11-03 09:07:40,480 (decode:127) INFO: finished generation of 250 utterances (RTF = 0.016).Même sur le CPU (Intel (R) Xeon (R) Gold 6154 CPU @ 3,00 GHz 16 Threads), il peut générer moins que le temps réel.
[decode]: 100% | ██████████ | 250/250 [22: 16< 00:00, 5.35s/it, RTF = 0.841]
2019-11-06 09:04:56,697 (decode:129) INFO: finished generation of 250 utterances (RTF = 0.734).Si vous utilisez le générateur de Melgan, la vitesse de décodage sera plus rapide.
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [04: 00< 00:00, 1.04it/s, RTF = 0.0882]
2020-02-08 10:45:14,111 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.137).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 06< 00:00, 36.38it/s, RTF = 0.00189]
2020-02-08 05:44:42,231 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.002).Si vous utilisez le générateur de Multi-Band Melgan, la vitesse de décodage sera beaucoup plus rapide.
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [01: 47< 00:00, 2.95it/s, RTF = 0.048]
2020-05-22 15:37:19,771 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.059).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 05< 00:00, 43.67it/s, RTF = 0.000928]
2020-05-22 15:35:13,302 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.001). Si vous souhaitez accélérer davantage l'inférence, il vaut la peine d'essayer la conversion de Pytorch à TensorFlow.
L'exemple de la conversion est disponible dans le cahier (fourni par @dathudeptrai).
Ici, les résultats sont résumés dans le tableau.
Vous pouvez écouter les échantillons et télécharger des modèles pré-entraînés à partir du lien vers notre Google Drive.
| Modèle | Confli | Égouter | FS [Hz] | Mel Range [Hz] | Fft / hop / win [pt] | # iters |
|---|---|---|---|---|---|---|
| ljspeech_parallel_wavegan.v1 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 400k |
| ljspeech_parallel_wavegan.v1.long | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 1m |
| ljspeech_parallel_wavegan.v1.no_limit | lien | En | 22.05K | Aucun | 1024/256 / Aucun | 400k |
| ljspeech_parallel_wavegan.v3 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 3m |
| ljSpeech_melgan.v1 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 400k |
| ljspeech_melgan.v1.long | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 1m |
| ljspeech_melgan_large.v1 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 400k |
| ljspeech_melgan_large.v1.long | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 1m |
| ljSpeech_melgan.v3 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 2m |
| ljSpeech_melgan.v3.long | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 4m |
| ljspeech_full_band_melgan.v1 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 1m |
| ljspeech_full_band_melgan.v2 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 1m |
| ljspeech_multi_band_melgan.v1 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 1m |
| ljspeech_multi_band_melgan.v2 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 1m |
| ljspeech_hifigan.v1 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 2,5 m |
| ljspeech_style_melgan.v1 | lien | En | 22.05K | 80-7600 | 1024/256 / Aucun | 1,5 m |
| JSUT_PARALLLE_WAVEGAN.v1 | lien | JP | 24k | 80-7600 | 2048/300/1200 | 400k |
| jsut_multi_band_melgan.v2 | lien | JP | 24k | 80-7600 | 2048/300/1200 | 1m |
| Just_hifigan.v1 | lien | JP | 24k | 80-7600 | 2048/300/1200 | 2,5 m |
| Just_style_melgan.v1 | lien | JP | 24k | 80-7600 | 2048/300/1200 | 1,5 m |
| CSMSC_PARALLALL_WAVEGAN.v1 | lien | Zh | 24k | 80-7600 | 2048/300/1200 | 400k |
| csmsc_multi_band_melgan.v2 | lien | Zh | 24k | 80-7600 | 2048/300/1200 | 1m |
| csmsc_hifigan.v1 | lien | Zh | 24k | 80-7600 | 2048/300/1200 | 2,5 m |
| csmsc_style_melgan.v1 | lien | Zh | 24k | 80-7600 | 2048/300/1200 | 1,5 m |
| arctic_slt_parallel_wavegan.v1 | lien | En | 16K | 80-7600 | 1024/256 / Aucun | 400k |
| JNAS_PARALLLE_WAVEGAN.v1 | lien | JP | 16K | 80-7600 | 1024/256 / Aucun | 400k |
| vctk_parallel_wavegan.v1 | lien | En | 24k | 80-7600 | 2048/300/1200 | 400k |
| vctk_parallel_wavegan.v1.long | lien | En | 24k | 80-7600 | 2048/300/1200 | 1m |
| vctk_multi_band_melgan.v2 | lien | En | 24k | 80-7600 | 2048/300/1200 | 1m |
| vctk_hifigan.v1 | lien | En | 24k | 80-7600 | 2048/300/1200 | 2,5 m |
| vctk_style_melgan.v1 | lien | En | 24k | 80-7600 | 2048/300/1200 | 1,5 m |
| Libritts_Parallel_Wavegan.v1 | lien | En | 24k | 80-7600 | 2048/300/1200 | 400k |
| libritts_parallel_wavegan.v1.long | lien | En | 24k | 80-7600 | 2048/300/1200 | 1m |
| libritts_multi_band_melgan.v2 | lien | En | 24k | 80-7600 | 2048/300/1200 | 1m |
| libritts_hifigan.v1 | lien | En | 24k | 80-7600 | 2048/300/1200 | 2,5 m |
| libritts_style_melgan.v1 | lien | En | 24k | 80-7600 | 2048/300/1200 | 1,5 m |
| KSS_PARALLEL_WAVEGAN.v1 | lien | Ko | 24k | 80-7600 | 2048/300/1200 | 400k |
| hui_acg_hokuspokus_parallel_wavegan.v1 | lien | De | 24k | 80-7600 | 2048/300/1200 | 400k |
| Ruslan_Parallel_Wavegan.v1 | lien | Ru | 24k | 80-7600 | 2048/300/1200 | 400k |
| Oniku_hifigan.v1 | lien | JP | 24k | 80-7600 | 2048/300/1200 | 250k |
| kiritan_hifigan.v1 | lien | JP | 24k | 80-7600 | 2048/300/1200 | 300k |
| OFUTON_HIFIGAN.v1 | lien | JP | 24k | 80-7600 | 2048/300/1200 | 300k |
| opencpop_hifigan.v1 | lien | Zh | 24k | 80-7600 | 2048/300/1200 | 250k |
| csd_english_hifigan.v1 | lien | En | 24k | 80-7600 | 2048/300/1200 | 300k |
| csd_korean_hifigan.v1 | lien | En | 24k | 80-7600 | 2048/300/1200 | 250k |
| kising_hifigan.v1 | lien | Zh | 24k | 80-7600 | 2048/300/1200 | 300k |
| m4singer_hifigan.v1 | lien | Zh | 24k | 80-7600 | 2048/300/1200 | 1m |
Veuillez accéder à notre Google Drive pour vérifier plus de résultats.
Veuillez vérifier la licence de la base de données (par exemple, si elle est appropriée pour l'utilisation commerciale) avant d'utiliser le modèle pré-formé.
Les auteurs ne seront pas responsables de toute perte en raison de l'utilisation du modèle et des litiges juridiques concernant l'utilisation de l'ensemble de données.
Ici, le code minimal est illustré à une synthèse d'analyse en utilisant le modèle pré-entraîné.
# Please make sure you installed `parallel_wavegan`
# If not, please install via pip
$ pip install parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# Now you can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above results
# Please put an audio file in `sample` directory to perform analysis-synthesis
$ ls sample/
sample.wav
# Then perform feature extraction -> feature normalization -> synthesis
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-normalize
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir dump/sample/raw
--dumpdir dump/sample/norm
--stats pretrain_model/ < pretrain_model_tag > /stats.h5
2019-11-13 13:44:29,574 (normalize:87) INFO: the number of files = 1.
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 513.13it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/norm
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# You can skip normalization step (on-the-fly normalization, feature extraction -> synthesis)
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/raw
--normalize-before
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# you can find the generated speech in `sample` directory
$ ls sample
sample.wav sample_gen.wavIci, je montre la procédure pour générer des formes d'onde avec des fonctionnalités générées par les modèles ESPNET-TTS.
# Make sure you already finished running the recipe of ESPnet-TTS.
# You must use the same feature settings for both Text2Mel and Mel2Wav models.
# Let us move on "ESPnet" recipe directory
$ cd /path/to/espnet/egs/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs/ < recipe_name > /tts1
# If you use ESPnet2, move on `egs2/`
$ cd /path/to/espnet/egs2/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs2/ < recipe_name > /tts1
# Please install this repository in ESPnet conda (or virtualenv) environment
$ . ./path.sh && pip install -U parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# You can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above resultsCas 1 : Si vous utilisez le même ensemble de données pour Text2Mel et Mel2Wav
# In this case, you can directly use generated features for decoding.
# Please specify `feats.scp` path for `--feats-scp`, which is located in
# exp/<your_model_dir>/outputs_*_decode/<set_name>/feats.scp.
# Note that do not use outputs_*decode_denorm/<set_name>/feats.scp since
# it is de-normalized features (the input for PWG is normalized features).
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode/ < set_name > /feats.scp
--outdir < path_to_outdir >
# In the case of ESPnet2, the generated feature can be found in
# exp/<your_model_dir>/decode_*/<set_name>/norm/feats.scp.
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /norm/feats.scp
--outdir < path_to_outdir >
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavCas 2 : Si vous utilisez différents ensembles de données pour les modèles Text2Mel et Mel2Wav
# In this case, you must provide `--normalize-before` option additionally.
# And use `feats.scp` of de-normalized generated features.
# ESPnet1 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode_denorm/ < set_name > /feats.scp
--outdir < path_to_outdir >
--normalize-before
# ESPnet2 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /denorm/feats.scp
--outdir < path_to_outdir >
--normalize-before
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavSi vous souhaitez combiner ces modèles dans Python, vous pouvez essayer la démonstration en temps réel dans Google Colab!
Parfois, nous voulons décoder avec des fichiers NPY vidés, qui sont du spectrogramme de MEL généré par les modèles TTS. Veuillez vous assurer que vous avez utilisé les mêmes paramètres d'extraction de fonctionnalités du vocodeur pré-entraîné ( fs , fft_size , hop_size , win_length , fmin et fmax ).
Seule la différence de log_base peut être modifiée avec certains post-traitements (nous utilisons Log 10 au lieu du journal naturel par défaut). Voir détail dans le commentaire.
# Generate dummy npy file of mel-spectrogram
$ ipython
[ins] In [1]: import numpy as np
[ins] In [2]: x = np.random.randn(512, 80) # (#frames, #mels)
[ins] In [3]: np.save( " dummy_1.npy " , x)
[ins] In [4]: y = np.random.randn(256, 80) # (#frames, #mels)
[ins] In [5]: np.save( " dummy_2.npy " , y)
[ins] In [6]: exit
# Make scp file (key-path format)
$ find -name " *.npy " | awk ' {print "dummy_" NR " " $1} ' > feats.scp
# Check (<utt_id> <path>)
$ cat feats.scp
dummy_1 ./dummy_1.npy
dummy_2 ./dummy_2.npy
# Decode without feature normalization
# This case assumes that the input mel-spectrogram is normalized with the same statistics of the pretrained model.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).
# Decode with feature normalization
# This case assumes that the input mel-spectrogram is not normalized.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--normalize-before
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).L'auteur tient à remercier Ryuichi Yamamoto (@ R9Y9) pour son grand référentiel, son article et ses discussions précieuses.
Tomoki Hayashi (@ kan-bayashi)
Courriel: hayashi.tomoki<at>g.sp.m.is.nagoya-u.ac.jp


