ParallelWaveGAN
Version 0.6.1
Dieses Repository bietet inoffizielle Pytorch -Implementierungen der folgenden Modelle:
Sie können diese hochmodernen nicht autoregressiven Modelle kombinieren, um Ihren eigenen großartigen Vocoder zu bauen!
Bitte überprüfen Sie unsere Beispiele in unserer Demo HP.
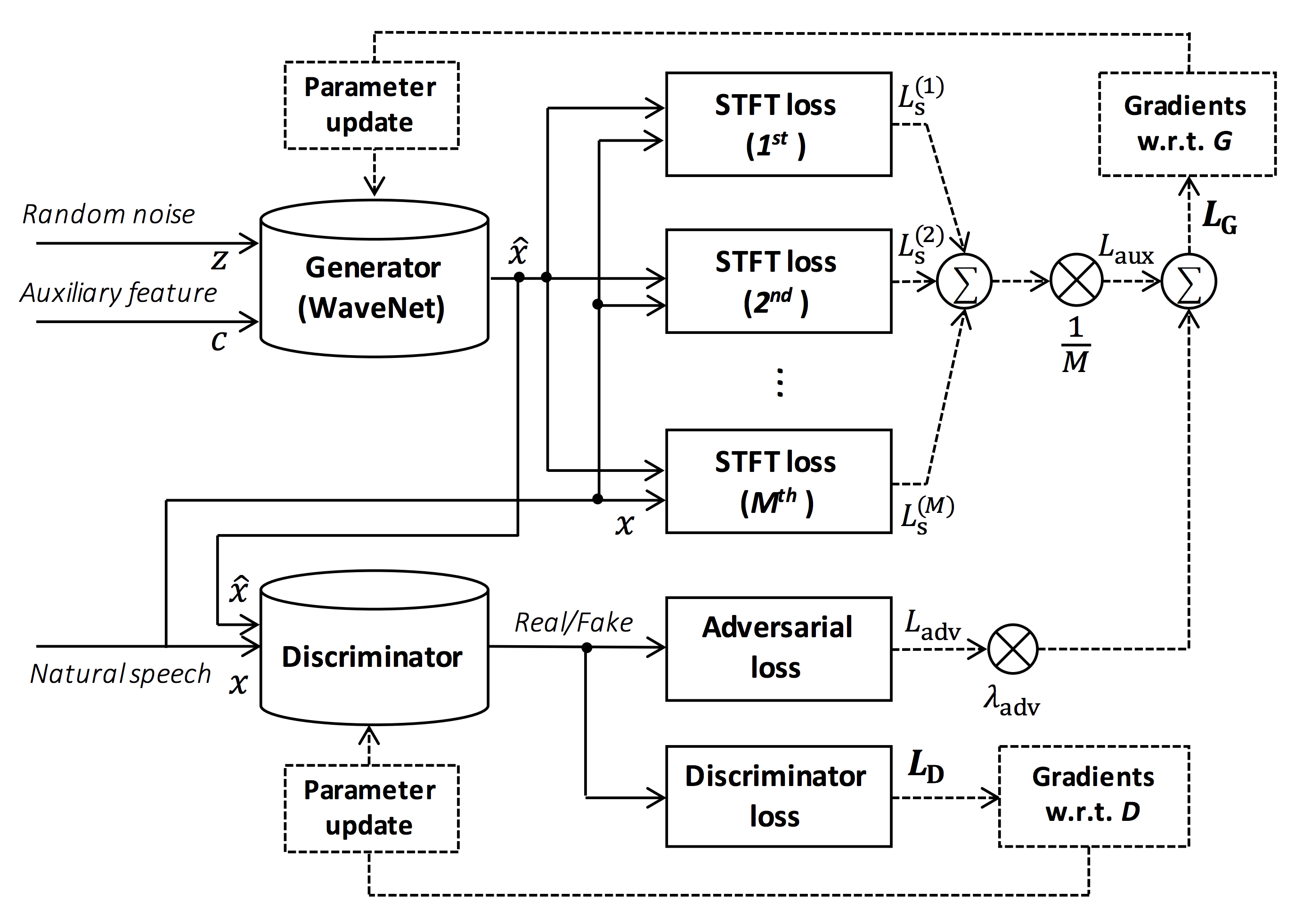
Quelle der Abbildung: https://arxiv.org/pdf/1910.11480.pdf
Das Ziel dieses Repositorys ist es, einen Echtzeit-Vocoder für Nerven zu liefern, der mit ESPNET-TTS kompatibel ist.
Außerdem kann dieses Repository mit NVIDIA/TACOTRON2-basierter Implementierung kombiniert werden (siehe diesen Kommentar).
Sie können die Echtzeit-End-to-End-Text-to-Sprach- und Sang-Sprachsynthese-Demonstration in Google Colab ausprobieren!
Dieses Repository wird auf Ubuntu 20.04 mit einem GPU Titan V getestet.
sudo apt install libsndfile-dev in ubuntu)sudo apt install jq in Ubuntu)sudo apt install sox in Ubuntu) Eine andere CUDA -Version sollte funktionieren, aber nicht explizit getestet.
Alle Codes werden auf Pytorch 1.8.1, 1.9, 1.10.2, 1.11.0, 1.12.1, 1.13.1, 2.0.1 und 2.1.0 getestet.
Sie können die Installationsmethode aus zwei Alternativen auswählen.
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN
$ pip install -e .
# If you want to use distributed training, please install
# apex manually by following https://github.com/NVIDIA/apex
$ ... Beachten Sie, dass Ihre CUDA -Version genau mit der Version übereinstimmt werden muss, die für den Pytorch -Binary zur Installation von Apex verwendet wird.
So installieren Sie Pytorch, die mit einer anderen CUDA -Version kompiliert wurden, tools/Makefile .
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN/tools
$ make
# If you want to use distributed training, please run following
# command to install apex.
$ make apex Beachten Sie, dass wir die CUDA -Version angeben, die zum Kompilieren von Pytorch -Rad verwendet wird.
Wenn Sie verschiedene CUDA -Versionen verwenden möchten, überprüfen Sie bitte tools/Makefile um das zu installierende Pytorch -Rad zu ändern.
Dieses Repository bietet Rezepte im Kaldi-Stil, das gleich wie ESPNET.
Derzeit werden die folgenden Rezepte unterstützt.
Um das Rezept auszuführen, befolgen Sie bitte die folgende Anweisung.
# Let us move on the recipe directory
$ cd egs/ljspeech/voc1
# Run the recipe from scratch
$ ./run.sh
# You can change config via command line
$ ./run.sh --conf < your_customized_yaml_config >
# You can select the stage to start and stop
$ ./run.sh --stage 2 --stop_stage 2
# If you want to specify the gpu
$ CUDA_VISIBLE_DEVICES=1 ./run.sh --stage 2
# If you want to resume training from 10000 steps checkpoint
$ ./run.sh --stage 2 --resume < path > / < to > /checkpoint-10000steps.pklWeitere Informationen zu den Rezepten in diesem Readme finden Sie in diesem Readme.
Die Dekodierungsgeschwindigkeit beträgt RTF = 0,016 mit Titan V, viel schneller als die Echtzeit.
[decode]: 100% | ██████████ | 250/250 [00: 30< 00:00, 8.31it/s, RTF = 0.0156]
2019-11-03 09:07:40,480 (decode:127) INFO: finished generation of 250 utterances (RTF = 0.016).Selbst auf der CPU (Intel (R) Xeon (R) Gold 6154 CPU @ 3,00 GHz 16 Threads) kann es weniger als die Echtzeit erzeugen.
[decode]: 100% | ██████████ | 250/250 [22: 16< 00:00, 5.35s/it, RTF = 0.841]
2019-11-06 09:04:56,697 (decode:129) INFO: finished generation of 250 utterances (RTF = 0.734).Wenn Sie Melgans Generator verwenden, ist die Dekodierungsgeschwindigkeit weiter schneller.
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [04: 00< 00:00, 1.04it/s, RTF = 0.0882]
2020-02-08 10:45:14,111 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.137).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 06< 00:00, 36.38it/s, RTF = 0.00189]
2020-02-08 05:44:42,231 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.002).Wenn Sie den Generator von Multi-Band Melgan verwenden, wird die Dekodierungsgeschwindigkeit viel schneller.
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [01: 47< 00:00, 2.95it/s, RTF = 0.048]
2020-05-22 15:37:19,771 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.059).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 05< 00:00, 43.67it/s, RTF = 0.000928]
2020-05-22 15:35:13,302 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.001). Wenn Sie die Inferenz mehr beschleunigen möchten, lohnt es sich, die Konvertierung von Pytorch in den TensorFlow auszuprobieren.
Das Beispiel für die Konvertierung ist im Notizbuch verfügbar (bereitgestellt von @Dathudeptrai).
Hier sind die Ergebnisse in der Tabelle zusammengefasst.
Sie können sich die Beispiele anhören und vorgezogene Modelle vom Link zu unserem Google Drive herunterladen.
| Modell | Conf | Lang | FS [Hz] | Mel Range [Hz] | FFT / Hop / Win [PT] | # ITERS |
|---|---|---|---|---|---|---|
| ljspeech_parallel_wavegan.v1 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 400k |
| ljspeech_parallel_wavegan.v1.long | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 1m |
| ljspeech_parallel_wavegan.v1.no_limit | Link | En | 22.05k | Keiner | 1024 /256 / keine | 400k |
| ljspeech_parallel_wavegan.v3 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 3m |
| ljspeech_melgan.v1 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 400k |
| ljspeech_melgan.v1.long | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 1m |
| ljspeech_Melgan_large.v1 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 400k |
| ljspeech_Melgan_large.v1.long | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 1m |
| ljspeech_melgan.v3 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 2m |
| ljspeech_melgan.v3.long | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 4m |
| ljspeech_full_band_melgan.v1 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 1m |
| ljspeech_full_band_melgan.v2 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 1m |
| ljspeech_multi_band_melgan.v1 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 1m |
| ljspeech_multi_band_melgan.v2 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 1m |
| ljspeech_hifigan.v1 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 2,5 m |
| ljspeech_style_melgan.v1 | Link | En | 22.05k | 80-7600 | 1024 /256 / keine | 1,5 m |
| JSUT_PARALLEL_WAVEGAN.V1 | Link | JP | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| jsut_multi_band_melgan.v2 | Link | JP | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| Just_hifigan.v1 | Link | JP | 24k | 80-7600 | 2048 /300 /1200 | 2,5 m |
| Just_Style_Melgan.v1 | Link | JP | 24k | 80-7600 | 2048 /300 /1200 | 1,5 m |
| csmsc_parallel_wavegan.v1 | Link | Zh | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| csmsc_multi_band_melgan.v2 | Link | Zh | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| CSMSC_HIFIGAN.V1 | Link | Zh | 24k | 80-7600 | 2048 /300 /1200 | 2,5 m |
| csmsc_style_melgan.v1 | Link | Zh | 24k | 80-7600 | 2048 /300 /1200 | 1,5 m |
| ARCTIC_SLT_PARALLEL_WAVEGAN.V1 | Link | En | 16k | 80-7600 | 1024 /256 / keine | 400k |
| jnas_parallel_wavegan.v1 | Link | JP | 16k | 80-7600 | 1024 /256 / keine | 400k |
| vctk_parallel_wavegan.v1 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| vctk_parallel_wavegan.v1.long | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| vctk_multi_band_melgan.v2 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| vctk_hifigan.v1 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 2,5 m |
| vctk_style_melgan.v1 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 1,5 m |
| libritts_parallel_wavegan.v1 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| libritts_parallel_wavegan.v1.long | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| libritts_multi_band_melgan.v2 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| libritts_hifigan.v1 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 2,5 m |
| libritts_style_melgan.v1 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 1,5 m |
| KSS_PARALLEL_WAVEGAN.V1 | Link | Ko | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| HUI_ACG_HOKUSPOKUS_PARALLEL_WAVEGAN.V1 | Link | De | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| RUSLAN_PARALLEL_WAVEGAN.V1 | Link | Ru | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| oniku_hifigan.v1 | Link | JP | 24k | 80-7600 | 2048 /300 /1200 | 250k |
| kiritan_hifigan.v1 | Link | JP | 24k | 80-7600 | 2048 /300 /1200 | 300k |
| Ofuton_hifigan.v1 | Link | JP | 24k | 80-7600 | 2048 /300 /1200 | 300k |
| openCpop_hifigan.v1 | Link | Zh | 24k | 80-7600 | 2048 /300 /1200 | 250k |
| csd_english_hifigan.v1 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 300k |
| CSD_KOREAN_HIFIGAN.V1 | Link | En | 24k | 80-7600 | 2048 /300 /1200 | 250k |
| kising_hifigan.v1 | Link | Zh | 24k | 80-7600 | 2048 /300 /1200 | 300k |
| m4singer_hifigan.v1 | Link | Zh | 24k | 80-7600 | 2048 /300 /1200 | 1m |
Bitte greifen Sie auf unserem Google -Laufwerk auf, um weitere Ergebnisse zu überprüfen.
Bitte überprüfen Sie die Lizenz der Datenbank (z. B. eg, unabhängig davon, ob sie für die kommerzielle Nutzung ordnungsgemäß ist), bevor Sie das vorgebildete Modell verwenden.
Die Autoren sind aufgrund der Verwendung des Modells und der rechtlichen Streitigkeiten in Bezug auf die Verwendung des Datensatzes nicht für Verluste verantwortlich.
Hier wird gezeigt, dass der minimale Code die Analyse-Synthese unter Verwendung des vorbereiteten Modells durchführt.
# Please make sure you installed `parallel_wavegan`
# If not, please install via pip
$ pip install parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# Now you can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above results
# Please put an audio file in `sample` directory to perform analysis-synthesis
$ ls sample/
sample.wav
# Then perform feature extraction -> feature normalization -> synthesis
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-normalize
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir dump/sample/raw
--dumpdir dump/sample/norm
--stats pretrain_model/ < pretrain_model_tag > /stats.h5
2019-11-13 13:44:29,574 (normalize:87) INFO: the number of files = 1.
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 513.13it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/norm
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# You can skip normalization step (on-the-fly normalization, feature extraction -> synthesis)
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/raw
--normalize-before
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# you can find the generated speech in `sample` directory
$ ls sample
sample.wav sample_gen.wavHier zeige ich das Verfahren, um Wellenformen mit Funktionen zu erzeugen, die von ESPNET-TTS-Modellen erzeugt werden.
# Make sure you already finished running the recipe of ESPnet-TTS.
# You must use the same feature settings for both Text2Mel and Mel2Wav models.
# Let us move on "ESPnet" recipe directory
$ cd /path/to/espnet/egs/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs/ < recipe_name > /tts1
# If you use ESPnet2, move on `egs2/`
$ cd /path/to/espnet/egs2/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs2/ < recipe_name > /tts1
# Please install this repository in ESPnet conda (or virtualenv) environment
$ . ./path.sh && pip install -U parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# You can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above resultsFall 1 : Wenn Sie denselben Datensatz sowohl für Text2Mel als auch für Mel2WAV verwenden
# In this case, you can directly use generated features for decoding.
# Please specify `feats.scp` path for `--feats-scp`, which is located in
# exp/<your_model_dir>/outputs_*_decode/<set_name>/feats.scp.
# Note that do not use outputs_*decode_denorm/<set_name>/feats.scp since
# it is de-normalized features (the input for PWG is normalized features).
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode/ < set_name > /feats.scp
--outdir < path_to_outdir >
# In the case of ESPnet2, the generated feature can be found in
# exp/<your_model_dir>/decode_*/<set_name>/norm/feats.scp.
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /norm/feats.scp
--outdir < path_to_outdir >
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavFall 2 : Wenn Sie verschiedene Datensätze für Text2Mel- und Mel2WAV -Modelle verwenden
# In this case, you must provide `--normalize-before` option additionally.
# And use `feats.scp` of de-normalized generated features.
# ESPnet1 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode_denorm/ < set_name > /feats.scp
--outdir < path_to_outdir >
--normalize-before
# ESPnet2 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /denorm/feats.scp
--outdir < path_to_outdir >
--normalize-before
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavWenn Sie diese Modelle in Python kombinieren möchten, können Sie die Echtzeitdemonstration in Google Colab ausprobieren!
Manchmal möchten wir mit abgefüllten NPY-Dateien dekodieren, die von TTS-Modellen melspektrogramm erzeugt werden. Bitte stellen Sie sicher, dass Sie dieselben Feature -Extraktionseinstellungen des vorgenannten Vocoders ( fs , fft_size , hop_size , win_length , fmin und fmax ) verwendet haben.
Nur die Differenz von log_base kann mit einigen Nachbearbeitung geändert werden (wir verwenden Log 10 anstelle von natürlichen Protokollen als Standard). Siehe Detail im Kommentar.
# Generate dummy npy file of mel-spectrogram
$ ipython
[ins] In [1]: import numpy as np
[ins] In [2]: x = np.random.randn(512, 80) # (#frames, #mels)
[ins] In [3]: np.save( " dummy_1.npy " , x)
[ins] In [4]: y = np.random.randn(256, 80) # (#frames, #mels)
[ins] In [5]: np.save( " dummy_2.npy " , y)
[ins] In [6]: exit
# Make scp file (key-path format)
$ find -name " *.npy " | awk ' {print "dummy_" NR " " $1} ' > feats.scp
# Check (<utt_id> <path>)
$ cat feats.scp
dummy_1 ./dummy_1.npy
dummy_2 ./dummy_2.npy
# Decode without feature normalization
# This case assumes that the input mel-spectrogram is normalized with the same statistics of the pretrained model.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).
# Decode with feature normalization
# This case assumes that the input mel-spectrogram is not normalized.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--normalize-before
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).Der Autor bedankt sich bei Ryuichi Yamamoto (@R9Y9) für sein großes Repository, sein Papier und seine wertvollen Diskussionen.
Tomoki Hayashi (@kan-bayashi)
E-Mail: hayashi.tomoki<at>g.sp.m.is.nagoya-u.ac.jp


