ParallelWaveGAN
Version 0.6.1
このリポジトリは、次のモデルの非公式のPytorch実装を提供します。
これらの最先端の非自動性モデルを組み合わせて、独自の優れたボコーダーを構築できます!
デモHPでサンプルを確認してください。
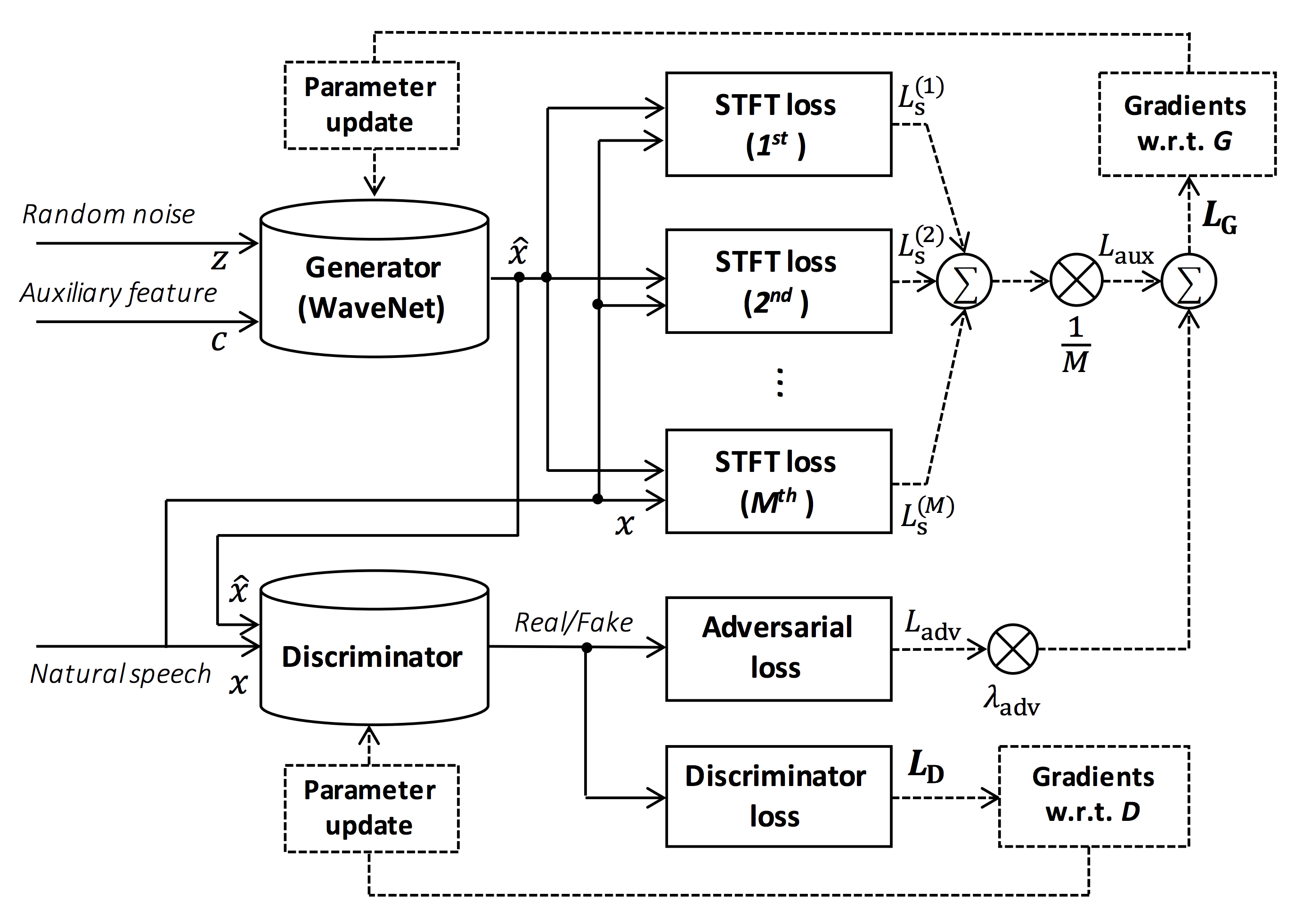
図のソース:https://arxiv.org/pdf/1910.11480.pdf
このリポジトリの目標は、ESPNET-TTSと互換性のあるリアルタイムのニューラルボコーダーを提供することです。
また、このリポジトリは、NVIDIA/Tacotron2ベースの実装と組み合わせることができます(このコメントを参照)。
Google Colabでリアルタイムのエンドツーエンドのテキストからスピーチと歌の音声合成デモを試すことができます!
このリポジトリは、GPUタイタンVでUbuntu 20.04でテストされています。
sudo apt install libsndfile-devインストールできます)sudo apt install jqをubuntuにインストールできます)sudo apt install soxを介してインストールできます)さまざまなCUDAバージョンが機能するはずですが、明示的にテストされていません。
すべてのコードは、Pytorch 1.8.1、1.9、1.10.2、1.11.0、1.12.1、1.13.1、2.0.1、および2.1.0でテストされています。
2つの代替案からインストール方法を選択できます。
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN
$ pip install -e .
# If you want to use distributed training, please install
# apex manually by following https://github.com/NVIDIA/apex
$ ... CUDAバージョンは、ApexをインストールするためにPytorchバイナリに使用されるバージョンと正確に一致する必要があることに注意してください。
さまざまなCUDAバージョンにコンパイルされたPytorchをインストールするには、 tools/Makefile参照してください。
$ git clone https://github.com/kan-bayashi/ParallelWaveGAN.git
$ cd ParallelWaveGAN/tools
$ make
# If you want to use distributed training, please run following
# command to install apex.
$ make apex Pytorchホイールのコンパイルに使用されるCUDAバージョンを指定することに注意してください。
別のCUDAバージョンを使用する場合は、 tools/Makefileをチェックして、インストールするPytorchホイールを変更してください。
このリポジトリは、ESPNETと同じKaldiスタイルのレシピを提供します。
現在、次のレシピがサポートされています。
レシピを実行するには、以下の指示に従ってください。
# Let us move on the recipe directory
$ cd egs/ljspeech/voc1
# Run the recipe from scratch
$ ./run.sh
# You can change config via command line
$ ./run.sh --conf < your_customized_yaml_config >
# You can select the stage to start and stop
$ ./run.sh --stage 2 --stop_stage 2
# If you want to specify the gpu
$ CUDA_VISIBLE_DEVICES=1 ./run.sh --stage 2
# If you want to resume training from 10000 steps checkpoint
$ ./run.sh --stage 2 --resume < path > / < to > /checkpoint-10000steps.pklこのReadmeのレシピの詳細については、詳細をご覧ください。
デコード速度は、Titan Vを使用したRTF = 0.016で、リアルタイムよりもはるかに高速です。
[decode]: 100% | ██████████ | 250/250 [00: 30< 00:00, 8.31it/s, RTF = 0.0156]
2019-11-03 09:07:40,480 (decode:127) INFO: finished generation of 250 utterances (RTF = 0.016).CPU(Intel(R)Xeon(R)Gold 6154 CPU @ 3.00GHz 16スレッド)でさえ、リアルタイムよりも少ない生成を可能にします。
[decode]: 100% | ██████████ | 250/250 [22: 16< 00:00, 5.35s/it, RTF = 0.841]
2019-11-06 09:04:56,697 (decode:129) INFO: finished generation of 250 utterances (RTF = 0.734).Melganの発電機を使用すると、デコード速度がさらに高速になります。
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [04: 00< 00:00, 1.04it/s, RTF = 0.0882]
2020-02-08 10:45:14,111 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.137).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 06< 00:00, 36.38it/s, RTF = 0.00189]
2020-02-08 05:44:42,231 (decode:142) INFO: Finished generation of 250 utterances (RTF = 0.002).マルチバンドメルガンの発電機を使用すると、デコード速度がさらに高速になります。
# On CPU (Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz 16 threads)
[decode]: 100% | ██████████ | 250/250 [01: 47< 00:00, 2.95it/s, RTF = 0.048]
2020-05-22 15:37:19,771 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.059).
# On GPU (TITAN V)
[decode]: 100% | ██████████ | 250/250 [00: 05< 00:00, 43.67it/s, RTF = 0.000928]
2020-05-22 15:35:13,302 (decode:151) INFO: Finished generation of 250 utterances (RTF = 0.001).推論をさらに加速したい場合は、PytorchからTensorflowへの変換を試す価値があります。
変換の例は、ノートブック(@dathudeptraiが提供)で入手できます。
ここでは、結果をテーブルにまとめます。
サンプルを聴き、Googleドライブへのリンクから事前に抑制されたモデルをダウンロードできます。
| モデル | conf | ラング | FS [Hz] | メルレンジ[Hz] | fft / hop / win [pt] | #iters |
|---|---|---|---|---|---|---|
| ljspeech_parallel_wavegan.v1 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 400k |
| ljspeech_parallel_wavegan.v1.long | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 1m |
| ljspeech_parallel_wavegan.v1.no_limit | リンク | en | 22.05K | なし | 1024 /256 /なし | 400k |
| ljspeech_parallel_wavegan.v3 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 3m |
| ljspeech_melgan.v1 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 400k |
| ljspeech_melgan.v1.long | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 1m |
| ljspeech_melgan_large.v1 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 400k |
| ljspeech_melgan_large.v1.long | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 1m |
| ljspeech_melgan.v3 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 2m |
| ljspeech_melgan.v3.Long | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 4m |
| ljspeech_full_band_melgan.v1 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 1m |
| ljspeech_full_band_melgan.v2 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 1m |
| ljspeech_multi_band_melgan.v1 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 1m |
| ljspeech_multi_band_melgan.v2 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 1m |
| ljspeech_hifigan.v1 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 2.5m |
| ljspeech_style_melgan.v1 | リンク | en | 22.05K | 80-7600 | 1024 /256 /なし | 1.5m |
| jsut_parallel_wavegan.v1 | リンク | JP | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| jsut_multi_band_melgan.v2 | リンク | JP | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| just_hifigan.v1 | リンク | JP | 24k | 80-7600 | 2048 /300 /1200 | 2.5m |
| Just_style_melgan.v1 | リンク | JP | 24k | 80-7600 | 2048 /300 /1200 | 1.5m |
| csmsc_parallel_wavegan.v1 | リンク | Zh | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| csmsc_multi_band_melgan.v2 | リンク | Zh | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| csmsc_hifigan.v1 | リンク | Zh | 24k | 80-7600 | 2048 /300 /1200 | 2.5m |
| csmsc_style_melgan.v1 | リンク | Zh | 24k | 80-7600 | 2048 /300 /1200 | 1.5m |
| arctic_slt_parallel_wavegan.v1 | リンク | en | 16K | 80-7600 | 1024 /256 /なし | 400k |
| jnas_parallel_wavegan.v1 | リンク | JP | 16K | 80-7600 | 1024 /256 /なし | 400k |
| vctk_parallel_wavegan.v1 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| vctk_parallel_wavegan.v1.long | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| vctk_multi_band_melgan.v2 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| vctk_hifigan.v1 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 2.5m |
| vctk_style_melgan.v1 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 1.5m |
| libritts_parallel_wavegan.v1 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| libritts_parallel_wavegan.v1.long | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| libritts_multi_band_melgan.v2 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 1m |
| libritts_hifigan.v1 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 2.5m |
| libritts_style_melgan.v1 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 1.5m |
| kss_parallel_wavegan.v1 | リンク | KO | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| hui_acg_hokuspokus_parallel_wavegan.v1 | リンク | de | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| ruslan_parallel_wavegan.v1 | リンク | ru | 24k | 80-7600 | 2048 /300 /1200 | 400k |
| oniku_hifigan.v1 | リンク | JP | 24k | 80-7600 | 2048 /300 /1200 | 250k |
| kiritan_hifigan.v1 | リンク | JP | 24k | 80-7600 | 2048 /300 /1200 | 300k |
| ofuton_hifigan.v1 | リンク | JP | 24k | 80-7600 | 2048 /300 /1200 | 300k |
| opencpop_hifigan.v1 | リンク | Zh | 24k | 80-7600 | 2048 /300 /1200 | 250k |
| csd_english_hifigan.v1 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 300k |
| csd_korean_hifigan.v1 | リンク | en | 24k | 80-7600 | 2048 /300 /1200 | 250k |
| kising_hifigan.v1 | リンク | Zh | 24k | 80-7600 | 2048 /300 /1200 | 300k |
| m4singer_hifigan.v1 | リンク | Zh | 24k | 80-7600 | 2048 /300 /1200 | 1m |
Googleドライブにアクセスして、より多くの結果を確認してください。
事前に訓練されたモデルを使用する前に、データベースのライセンス(たとえば、商用使用に適しているかどうか)を確認してください。
著者は、モデルの使用とデータセットの使用に関する法的紛争のために損失について責任を負いません。
ここでは、最小限のコードが、前処理されたモデルを使用して分析合成を実行するように表示されます。
# Please make sure you installed `parallel_wavegan`
# If not, please install via pip
$ pip install parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# Now you can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above results
# Please put an audio file in `sample` directory to perform analysis-synthesis
$ ls sample/
sample.wav
# Then perform feature extraction -> feature normalization -> synthesis
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-normalize
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir dump/sample/raw
--dumpdir dump/sample/norm
--stats pretrain_model/ < pretrain_model_tag > /stats.h5
2019-11-13 13:44:29,574 (normalize:87) INFO: the number of files = 1.
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 513.13it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/norm
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# You can skip normalization step (on-the-fly normalization, feature extraction -> synthesis)
$ parallel-wavegan-preprocess
--config pretrain_model/ < pretrain_model_tag > /config.yml
--rootdir sample
--dumpdir dump/sample/raw
100% | ████████████████████████████████████████ | 1/1 [00: 00< 00:00, 914.19it/s]
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--dumpdir dump/sample/raw
--normalize-before
--outdir sample
2019-11-13 13:44:31,229 (decode:91) INFO: the number of features to be decoded = 1.
[decode]: 100% | ███████████████████ | 1/1 [00: 00< 00:00, 18.33it/s, RTF = 0.0146]
2019-11-13 13:44:37,132 (decode:129) INFO: finished generation of 1 utterances (RTF = 0.015).
# you can find the generated speech in `sample` directory
$ ls sample
sample.wav sample_gen.wavここでは、ESPNET-TTSモデルによって生成された機能を備えた波形を生成する手順を示します。
# Make sure you already finished running the recipe of ESPnet-TTS.
# You must use the same feature settings for both Text2Mel and Mel2Wav models.
# Let us move on "ESPnet" recipe directory
$ cd /path/to/espnet/egs/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs/ < recipe_name > /tts1
# If you use ESPnet2, move on `egs2/`
$ cd /path/to/espnet/egs2/ < recipe_name > /tts1
$ pwd
/path/to/espnet/egs2/ < recipe_name > /tts1
# Please install this repository in ESPnet conda (or virtualenv) environment
$ . ./path.sh && pip install -U parallel_wavegan
# You can download the pretrained model from terminal
$ python << EOF
from parallel_wavegan.utils import download_pretrained_model
download_pretrained_model("<pretrained_model_tag>", "pretrained_model")
EOF
# You can get all of available pretrained models as follows:
$ python << EOF
from parallel_wavegan.utils import PRETRAINED_MODEL_LIST
print(PRETRAINED_MODEL_LIST.keys())
EOF
# You can find downloaded pretrained model in `pretrained_model/<pretrain_model_tag>/`
$ ls pretrain_model/ < pretrain_model_tag >
checkpoint-400000steps.pkl config.yml stats.h5
# These files can also be downloaded manually from the above resultsケース1 :text2melとmel2wavの両方に同じデータセットを使用する場合
# In this case, you can directly use generated features for decoding.
# Please specify `feats.scp` path for `--feats-scp`, which is located in
# exp/<your_model_dir>/outputs_*_decode/<set_name>/feats.scp.
# Note that do not use outputs_*decode_denorm/<set_name>/feats.scp since
# it is de-normalized features (the input for PWG is normalized features).
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode/ < set_name > /feats.scp
--outdir < path_to_outdir >
# In the case of ESPnet2, the generated feature can be found in
# exp/<your_model_dir>/decode_*/<set_name>/norm/feats.scp.
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /norm/feats.scp
--outdir < path_to_outdir >
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavケース2 :Text2MelおよびMEL2WAVモデルに異なるデータセットを使用する場合
# In this case, you must provide `--normalize-before` option additionally.
# And use `feats.scp` of de-normalized generated features.
# ESPnet1 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /outputs_ * _decode_denorm/ < set_name > /feats.scp
--outdir < path_to_outdir >
--normalize-before
# ESPnet2 case
$ parallel-wavegan-decode
--checkpoint pretrain_model/ < pretrain_model_tag > /checkpoint-400000steps.pkl
--feats-scp exp/ < your_model_dir > /decode_ * / < set_name > /denorm/feats.scp
--outdir < path_to_outdir >
--normalize-before
# You can find the generated waveforms in <path_to_outdir>/.
$ ls < path_to_outdir >
utt_id_1_gen.wav utt_id_2_gen.wav ... utt_id_N_gen.wavPythonでこれらのモデルを組み合わせたい場合は、Google Colabでリアルタイムのデモを試すことができます!
DUMPED NPYファイルでデコードしたい場合があります。これは、TTSモデルによって生成されるMELスペクトルグラムです。前処理されたボコーダー( fs 、 fft_size 、 hop_size 、 win_length 、 fmin 、およびfmax )の同じ機能抽出設定を使用していることを確認してください。
いくつかの後処理では、 log_baseの違いのみを変更できます(デフォルトとして自然ログの代わりにログ10を使用します)。コメントの詳細をご覧ください。
# Generate dummy npy file of mel-spectrogram
$ ipython
[ins] In [1]: import numpy as np
[ins] In [2]: x = np.random.randn(512, 80) # (#frames, #mels)
[ins] In [3]: np.save( " dummy_1.npy " , x)
[ins] In [4]: y = np.random.randn(256, 80) # (#frames, #mels)
[ins] In [5]: np.save( " dummy_2.npy " , y)
[ins] In [6]: exit
# Make scp file (key-path format)
$ find -name " *.npy " | awk ' {print "dummy_" NR " " $1} ' > feats.scp
# Check (<utt_id> <path>)
$ cat feats.scp
dummy_1 ./dummy_1.npy
dummy_2 ./dummy_2.npy
# Decode without feature normalization
# This case assumes that the input mel-spectrogram is normalized with the same statistics of the pretrained model.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).
# Decode with feature normalization
# This case assumes that the input mel-spectrogram is not normalized.
$ parallel-wavegan-decode
--checkpoint /path/to/checkpoint-400000steps.pkl
--feats-scp ./feats.scp
--normalize-before
--outdir wav
2021-08-10 09:13:07,624 (decode:140) INFO: The number of features to be decoded = 2.
[decode]: 100% | ████████████████████████████████████████ | 2/2 [00: 00< 00:00, 13.84it/s, RTF = 0.00264]
2021-08-10 09:13:29,660 (decode:174) INFO: Finished generation of 2 utterances (RTF = 0.005).著者は、彼の素晴らしいリポジトリ、紙、貴重な議論について、山本龍子(@r9y9)に感謝したいと思います。
林楽王子(@kan-bayashi)
電子メール: hayashi.tomoki<at>g.sp.m.is.nagoya-u.ac.jp


