f5 tts mlx
0.2.3
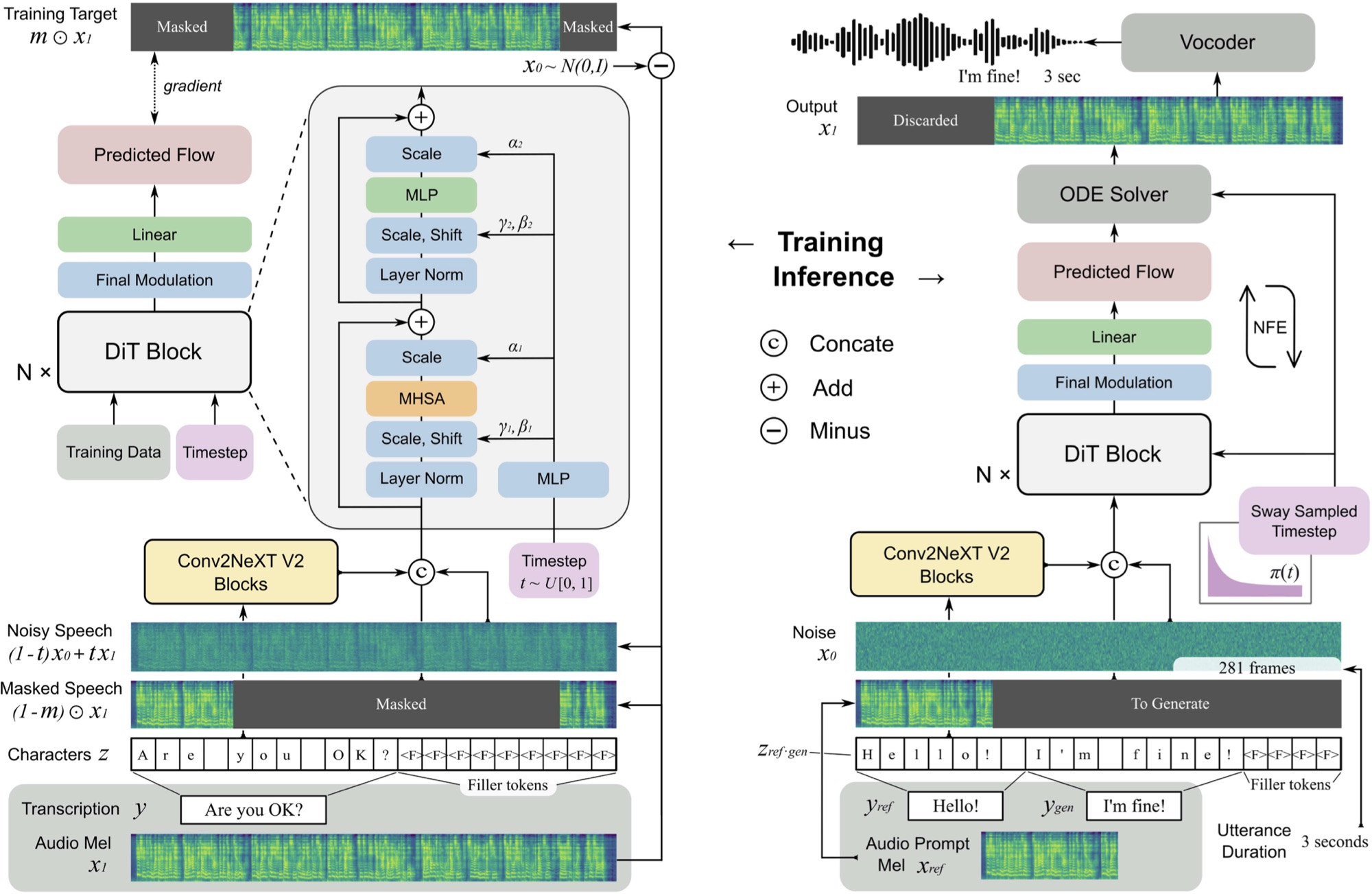
การใช้งาน F5-TTS ด้วยเฟรมเวิร์ก MLX
F5 TTS เป็นระบบที่ไม่ได้เป็นแบบไม่ได้เป็นศูนย์โดยใช้เครื่องกำเนิดไฟฟ้า Mel Spectrogram ที่จับคู่กับการไหลเวียนของตัวเองด้วยหม้อแปลงการแพร่กระจาย (DIT)
คุณสามารถฟังตัวอย่างที่นี่ที่สร้างขึ้นใน ~ 11 วินาทีบน M3 Max MacBook Pro
F5 เป็นวิวัฒนาการของ E2 TTS และปรับปรุงประสิทธิภาพด้วยบล็อก Convnext V2 สำหรับการจัดตำแหน่งข้อความที่เรียนรู้ ที่เก็บนี้ขึ้นอยู่กับการใช้งาน Pytorch ดั้งเดิมที่มีอยู่ที่นี่
pip install f5-tts-mlxpython -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. "นอกจากนี้คุณยังสามารถใช้ท่อเพื่อสร้างคำพูดจากผลลัพธ์ของกระบวนการอื่นเช่นจากรูปแบบภาษา:
mlx_lm.generate --model mlx-community/Llama-3.2-1B-Instruct-4bit --verbose false
--temp 0 --max-tokens 512 --prompt " Write a concise paragraph explaning wavelets. "
| python -m f5_tts_mlx.generateหากคุณต้องการใช้ตัวอย่างเสียงอ้างอิงของคุณเองตรวจสอบให้แน่ใจว่าเป็นไฟล์ Mono, 24KHz WAV ประมาณ 5-10 วินาที:
python -m f5_tts_mlx.generate
--text " The quick brown fox jumped over the lazy dog. "
--ref-audio /path/to/audio.wav
--ref-text " This is the caption for the reference audio. "คุณสามารถแปลงไฟล์เสียงเป็นรูปแบบที่ถูกต้องด้วย ffmpeg เช่นนี้:
ffmpeg -i /path/to/audio.wav -ac 1 -ar 24000 -sample_fmt s16 -t 10 /path/to/output_audio.wavดูที่นี่สำหรับตัวเลือกเพิ่มเติมในการปรับแต่งการสร้าง
หากคุณอยู่ในแบนด์วิดท์หรือสภาพแวดล้อมที่ จำกัด หน่วยความจำคุณสามารถใช้ตัวเลือก --q เพื่อโหลดรุ่นที่เป็นปริมาณของรุ่น รองรับตัวแปร 4 บิตและ 8 บิต
python -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. " --q 4คุณสามารถโหลดโมเดลที่ผ่านการฝึกอบรมจาก Python:
from f5_tts_mlx . generate import generate
audio = generate ( text = "Hello world." , ...)ตุ้มน้ำหนักรุ่นที่ผ่านการฝึกอบรมยังมีอยู่บนใบหน้ากอด
Yushen Chen สำหรับการใช้งาน Pytorch ดั้งเดิมของ F5 TTS และแบบจำลองที่ผ่านการฝึกอบรม
Phil Wang สำหรับการใช้งาน E2 TTS ว่าแบบจำลองนี้มีพื้นฐานมาจาก
@article { chen-etal-2024-f5tts ,
title = { F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching } ,
author = { Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen } ,
journal = { arXiv preprint arXiv:2410.06885 } ,
year = { 2024 } ,
} @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
}รหัสในที่เก็บนี้จะถูกเผยแพร่ภายใต้ใบอนุญาต MIT ตามที่พบในไฟล์ใบอนุญาต


