f5 tts mlx
0.2.3
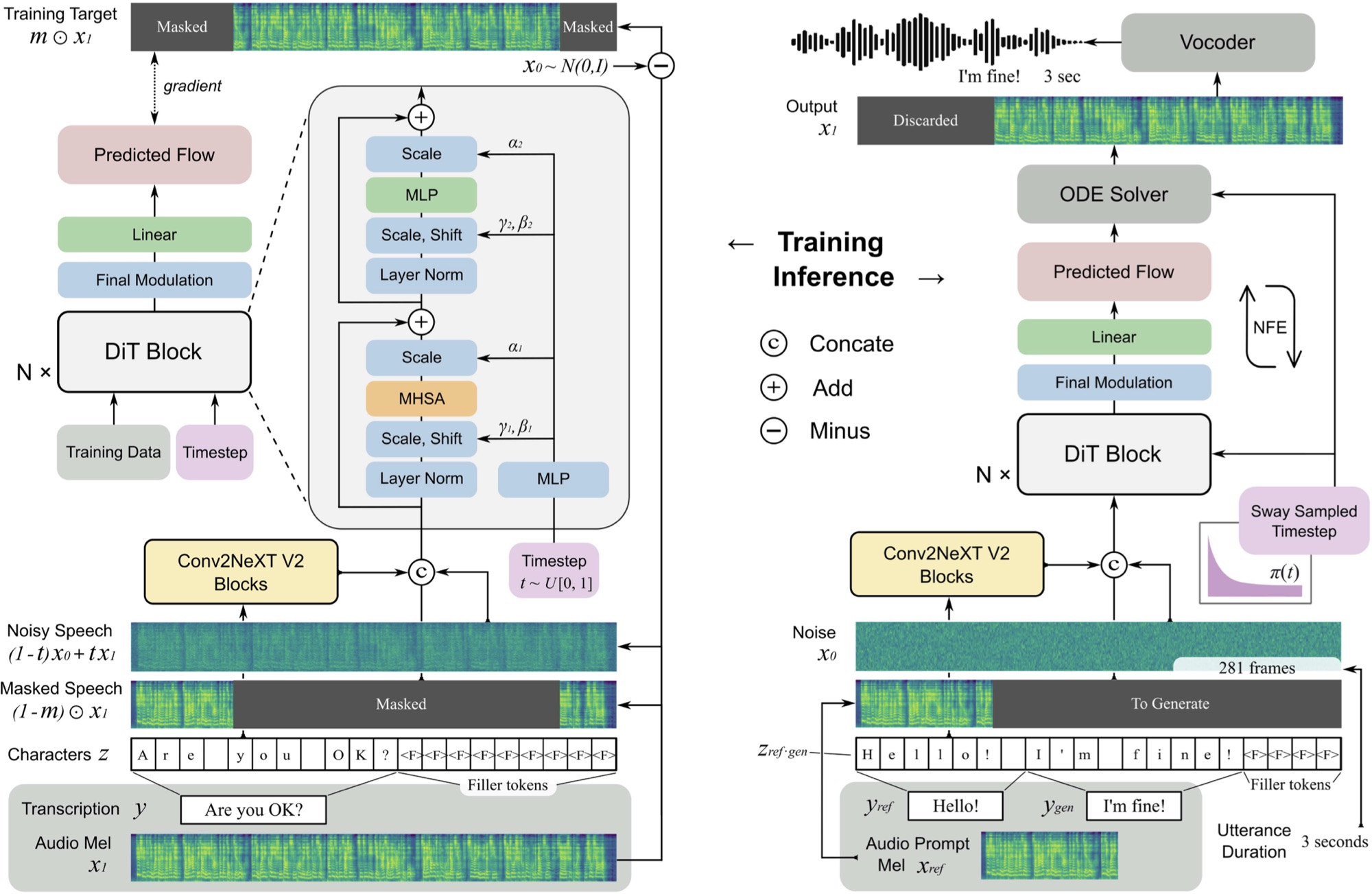
Implementasi F5-TTS, dengan kerangka kerja MLX.
F5 TTS adalah sistem teks-ke-speech non-autoregresif, nol-shot menggunakan generator spektrogram Mel-pencocokan aliran dengan transformator difusi (DIT).
Anda dapat mendengarkan sampel di sini yang dihasilkan dalam ~ 11 detik pada M3 Max MacBook Pro.
F5 adalah evolusi E2 TTS dan meningkatkan kinerja dengan blok ConvNext V2 untuk penyelarasan teks yang dipelajari. Repositori ini didasarkan pada implementasi Pytorch asli yang tersedia di sini.
pip install f5-tts-mlxpython -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. "Anda juga dapat menggunakan pipa untuk menghasilkan ucapan dari output dari proses lain, misalnya dari model bahasa:
mlx_lm.generate --model mlx-community/Llama-3.2-1B-Instruct-4bit --verbose false
--temp 0 --max-tokens 512 --prompt " Write a concise paragraph explaning wavelets. "
| python -m f5_tts_mlx.generateJika Anda ingin menggunakan sampel audio referensi Anda sendiri, pastikan itu adalah file mono, 24kHz WAV sekitar 5-10 detik:
python -m f5_tts_mlx.generate
--text " The quick brown fox jumped over the lazy dog. "
--ref-audio /path/to/audio.wav
--ref-text " This is the caption for the reference audio. "Anda dapat mengonversi file audio ke format yang benar dengan FFMPEG seperti ini:
ffmpeg -i /path/to/audio.wav -ac 1 -ar 24000 -sample_fmt s16 -t 10 /path/to/output_audio.wavLihat di sini untuk lebih banyak opsi untuk menyesuaikan pembuatan.
Jika Anda berada di lingkungan bandwidth atau terbatas memori, Anda dapat menggunakan opsi --q untuk memuat versi kuantisasi model. Varian 4-bit dan 8-bit didukung.
python -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. " --q 4Anda dapat memuat model pretrain dari Python:
from f5_tts_mlx . generate import generate
audio = generate ( text = "Hello world." , ...)Bobot model pretrained juga tersedia untuk memeluk wajah.
Yushen Chen untuk implementasi Pytorch asli F5 TTS dan model pretrained.
Phil Wang untuk implementasi E2 TTS yang menjadi dasar model ini.
@article { chen-etal-2024-f5tts ,
title = { F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching } ,
author = { Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen } ,
journal = { arXiv preprint arXiv:2410.06885 } ,
year = { 2024 } ,
} @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
}Kode dalam repositori ini dirilis di bawah lisensi MIT seperti yang ditemukan dalam file lisensi.


