f5 tts mlx
0.2.3
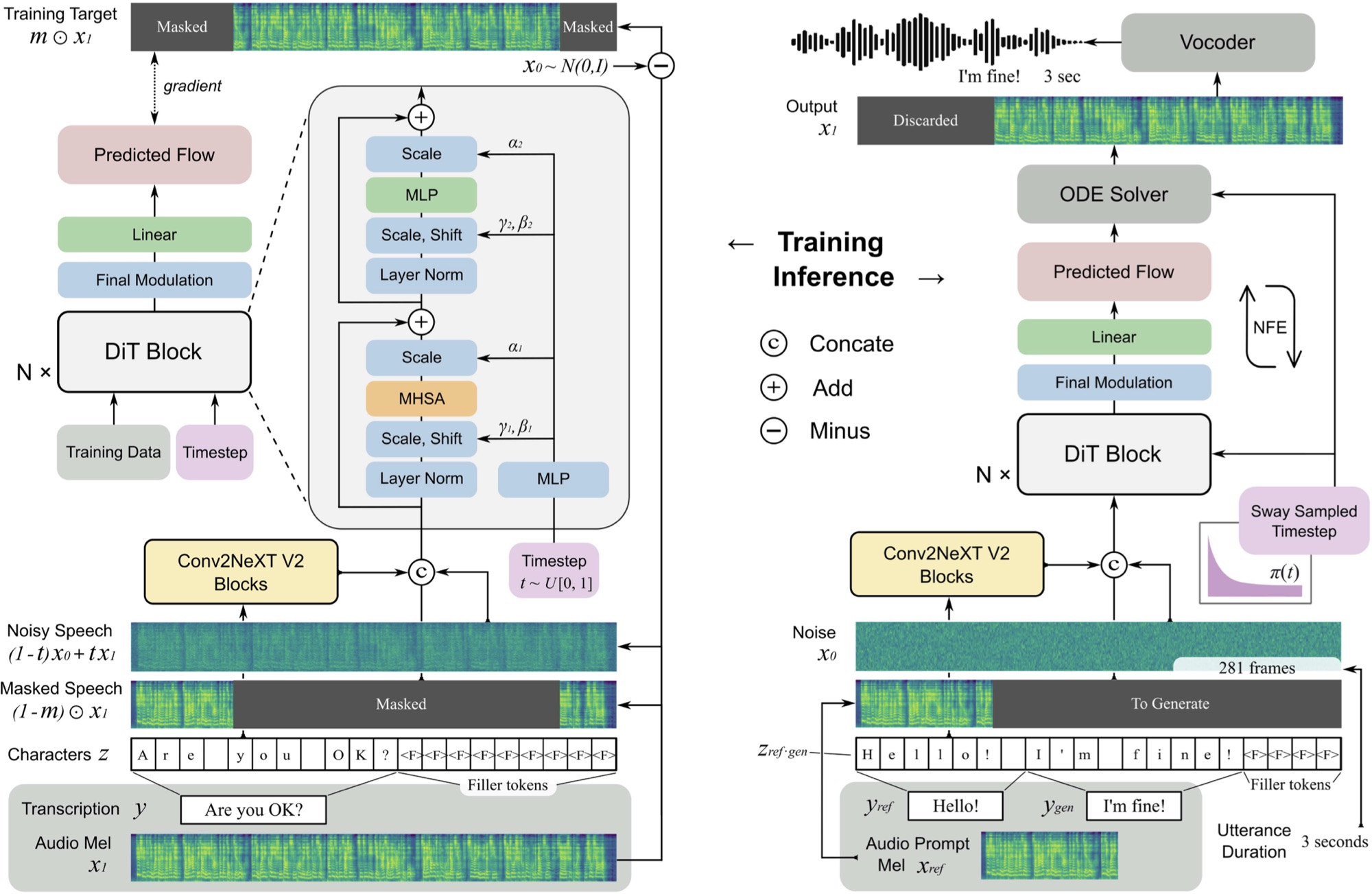
Implementación de F5-TTS, con el marco MLX.
F5 TTS es un sistema de texto a voz no autorregresivo y de disparo cero que utiliza un generador de espectrograma MEL de combinación de flujo con un transformador de difusión (DIT).
Puede escuchar una muestra aquí que se generó en ~ 11 segundos en un M3 Max MacBook Pro.
F5 es una evolución de E2 TTS y mejora el rendimiento con los bloques ConvNext V2 para la alineación de texto aprendido. Este repositorio se basa en la implementación original de Pytorch disponible aquí.
pip install f5-tts-mlxpython -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. "También puede usar una tubería para generar discurso a partir de la salida de otro proceso, por ejemplo, desde un modelo de idioma:
mlx_lm.generate --model mlx-community/Llama-3.2-1B-Instruct-4bit --verbose false
--temp 0 --max-tokens 512 --prompt " Write a concise paragraph explaning wavelets. "
| python -m f5_tts_mlx.generateSi desea utilizar su propia muestra de audio de referencia, asegúrese de que sea un archivo wav mono de 24 kHz de alrededor de 5-10 segundos:
python -m f5_tts_mlx.generate
--text " The quick brown fox jumped over the lazy dog. "
--ref-audio /path/to/audio.wav
--ref-text " This is the caption for the reference audio. "Puede convertir un archivo de audio al formato correcto con FFMPEG como este:
ffmpeg -i /path/to/audio.wav -ac 1 -ar 24000 -sample_fmt s16 -t 10 /path/to/output_audio.wavVea aquí para obtener más opciones para personalizar la generación.
Si se encuentra en un ancho de banda o un entorno limitado por la memoria, puede usar la opción --q para cargar una versión cuantificada del modelo. Se admiten variantes de 4 bits y 8 bits.
python -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. " --q 4Puede cargar un modelo previamente practicante de Python:
from f5_tts_mlx . generate import generate
audio = generate ( text = "Hello world." , ...)Los pesos del modelo previo a la aparición también están disponibles en la cara abrazada.
Yushen Chen para la implementación original de Pytorch de F5 TTS y el modelo de petróleo.
Phil Wang para la implementación E2 TTS en la que se basa este modelo.
@article { chen-etal-2024-f5tts ,
title = { F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching } ,
author = { Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen } ,
journal = { arXiv preprint arXiv:2410.06885 } ,
year = { 2024 } ,
} @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
}El código en este repositorio se publica bajo la licencia MIT como se encuentra en el archivo de licencia.


