f5 tts mlx
0.2.3
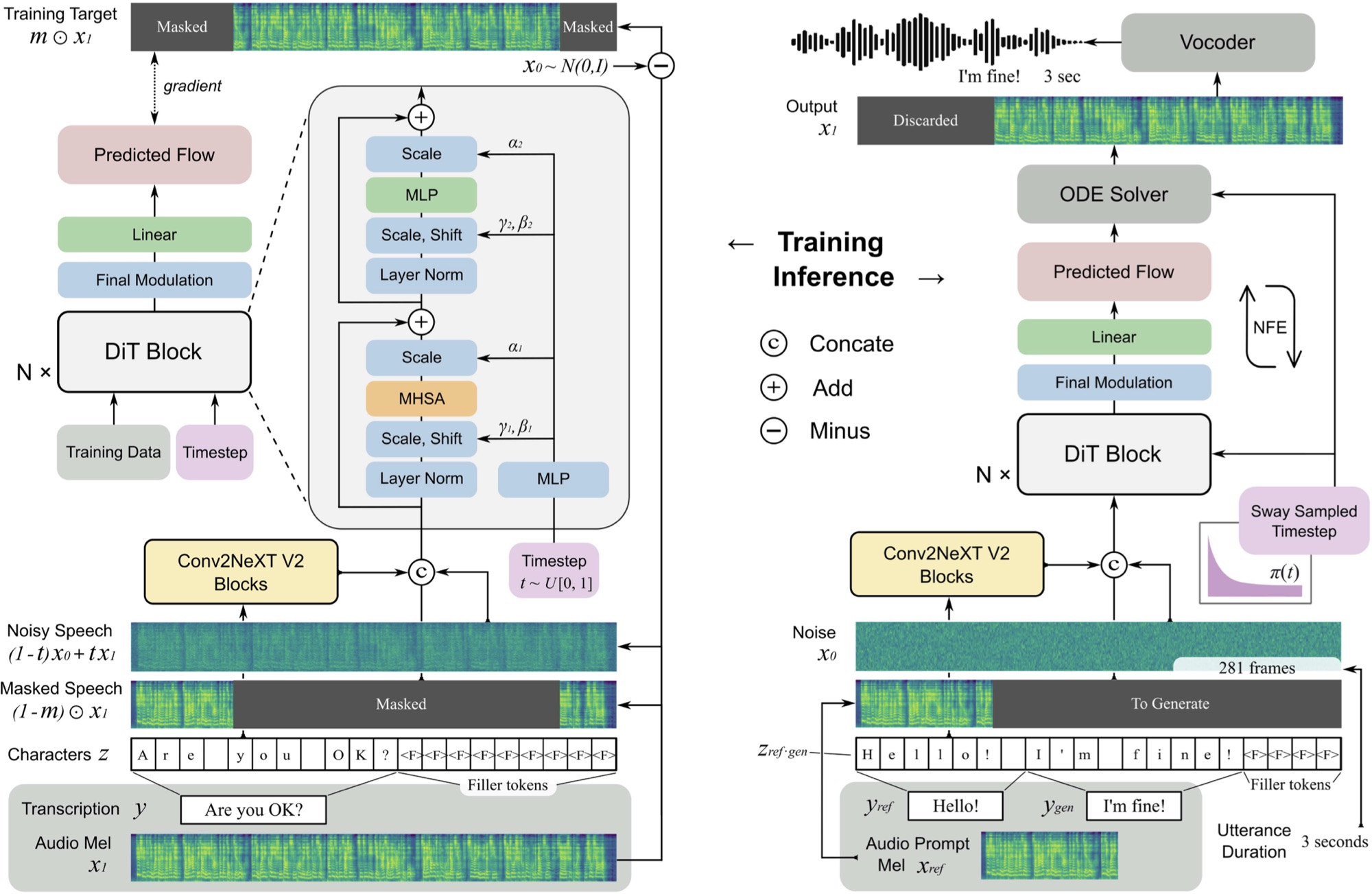
Implementação de F5-TTS, com a estrutura MLX.
O F5 TTS é um sistema de texto para fala zero e não autorregressivo usando um gerador de espectrograma MEL de correspondência de fluxo com um transformador de difusão (DIT).
Você pode ouvir uma amostra aqui que foi gerada em ~ 11 segundos em um M3 Max MacBook Pro.
F5 é uma evolução do E2 TTS e melhora o desempenho com os blocos ConvNext V2 para o alinhamento do texto aprendido. Este repositório é baseado na implementação original do Pytorch disponível aqui.
pip install f5-tts-mlxpython -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. "Você também pode usar um tubo para gerar fala a partir da saída de outro processo, por exemplo, de um modelo de idioma:
mlx_lm.generate --model mlx-community/Llama-3.2-1B-Instruct-4bit --verbose false
--temp 0 --max-tokens 512 --prompt " Write a concise paragraph explaning wavelets. "
| python -m f5_tts_mlx.generateSe você deseja usar sua própria amostra de áudio de referência, verifique se é um arquivo WAV mono e 24kHz de cerca de 5 a 10 segundos:
python -m f5_tts_mlx.generate
--text " The quick brown fox jumped over the lazy dog. "
--ref-audio /path/to/audio.wav
--ref-text " This is the caption for the reference audio. "Você pode converter um arquivo de áudio no formato correto com FFMPEG como este:
ffmpeg -i /path/to/audio.wav -ac 1 -ar 24000 -sample_fmt s16 -t 10 /path/to/output_audio.wavVeja aqui para obter mais opções para personalizar a geração.
Se você estiver em um ambiente de largura de banda ou com memória, poderá usar a opção --q para carregar uma versão quantizada do modelo. Variantes de 4 bits e 8 bits são suportadas.
python -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. " --q 4Você pode carregar um modelo pré -traido da Python:
from f5_tts_mlx . generate import generate
audio = generate ( text = "Hello world." , ...)Pesos do modelo pré -tenhado também estão disponíveis para abraçar o rosto.
Yushen Chen para a implementação original de Pytorch de F5 TTS e modelo pré -terenciado.
Phil Wang para a implementação do E2 TTS em que este modelo se baseia.
@article { chen-etal-2024-f5tts ,
title = { F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching } ,
author = { Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen } ,
journal = { arXiv preprint arXiv:2410.06885 } ,
year = { 2024 } ,
} @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
}O código deste repositório é liberado sob a licença do MIT, conforme encontrado no arquivo de licença.


