f5 tts mlx
0.2.3
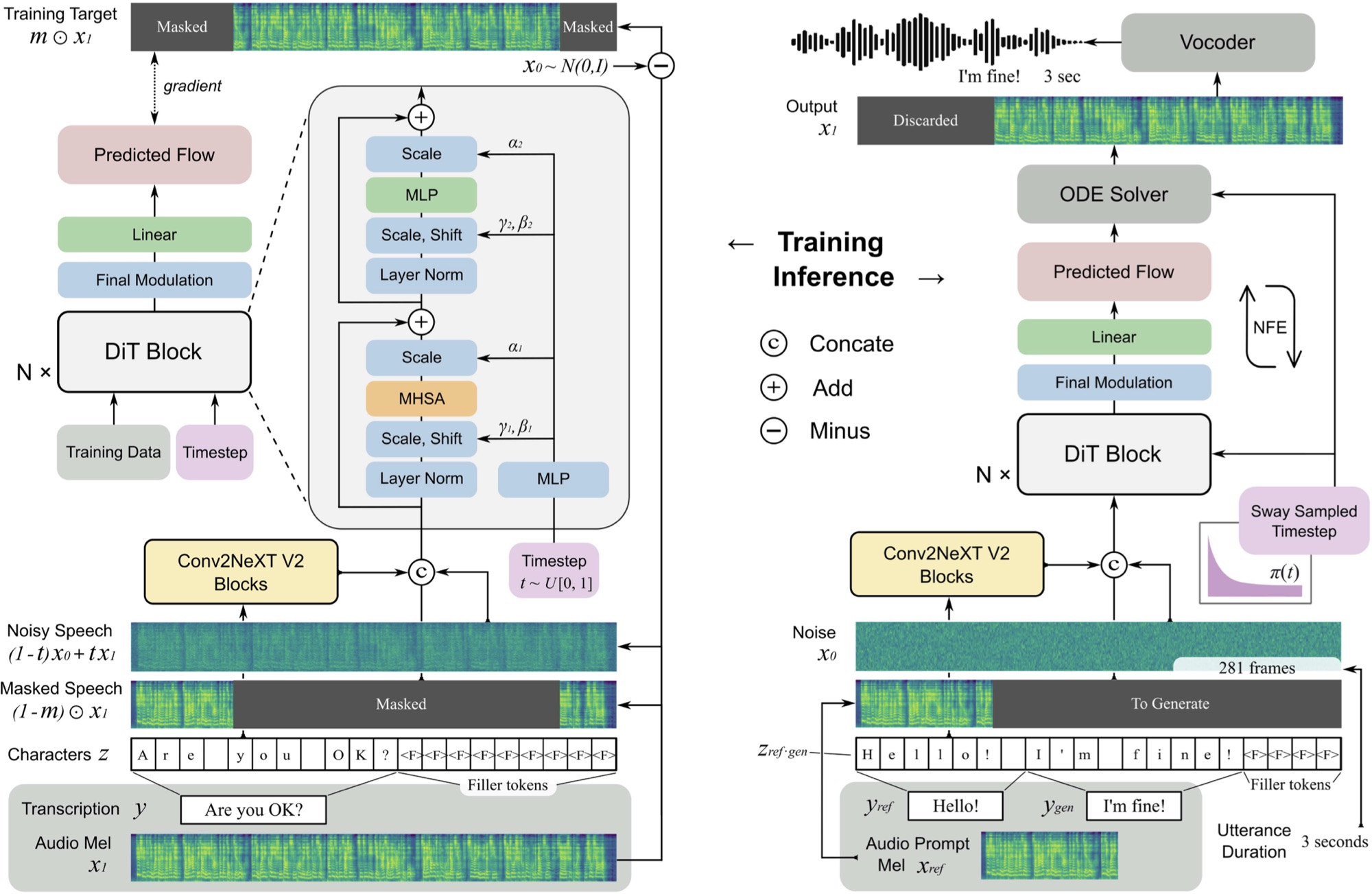
Implémentation de F5-TTS, avec le cadre MLX.
F5 TTS est un système de texte à dispection non autorégressif et zéro à l'aide d'un générateur de spectrogramme MEL de correspondance de flux avec un transformateur de diffusion (DIT).
Vous pouvez écouter un échantillon ici généré en ~ 11 secondes sur un M3 MAX MacBook Pro.
F5 est une évolution de E2 TTS et améliore les performances avec les blocs Convnext V2 pour l'alignement du texte savant. Ce référentiel est basé sur l'implémentation originale de Pytorch disponible ici.
pip install f5-tts-mlxpython -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. "Vous pouvez également utiliser un tuyau pour générer une parole à partir de la sortie d'un autre processus, par exemple à partir d'un modèle de langue:
mlx_lm.generate --model mlx-community/Llama-3.2-1B-Instruct-4bit --verbose false
--temp 0 --max-tokens 512 --prompt " Write a concise paragraph explaning wavelets. "
| python -m f5_tts_mlx.generateSi vous souhaitez utiliser votre propre échantillon audio de référence, assurez-vous qu'il s'agit d'un fichier WAV mono, 24KHz d'environ 5 à 10 secondes:
python -m f5_tts_mlx.generate
--text " The quick brown fox jumped over the lazy dog. "
--ref-audio /path/to/audio.wav
--ref-text " This is the caption for the reference audio. "Vous pouvez convertir un fichier audio au format correct avec ffmpeg comme ceci:
ffmpeg -i /path/to/audio.wav -ac 1 -ar 24000 -sample_fmt s16 -t 10 /path/to/output_audio.wavVoir ici pour plus d'options pour personnaliser la génération.
Si vous êtes dans une bande passante ou un environnement limité par la mémoire, vous pouvez utiliser l'option --q pour charger une version quantifiée du modèle. Les variantes 4 bits et 8 bits sont prises en charge.
python -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. " --q 4Vous pouvez charger un modèle pré-entraîné de Python:
from f5_tts_mlx . generate import generate
audio = generate ( text = "Hello world." , ...)Des poids de modèle pré-entraînés sont également disponibles sur le visage étreint.
Yushen Chen pour la mise en œuvre originale de Pytorch de F5 TTS et du modèle pré-entraîné.
Phil Wang pour l'implémentation E2 TTS sur laquelle ce modèle est basé.
@article { chen-etal-2024-f5tts ,
title = { F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching } ,
author = { Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen } ,
journal = { arXiv preprint arXiv:2410.06885 } ,
year = { 2024 } ,
} @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
}Le code de ce référentiel est publié dans le cadre de la licence MIT telle que trouvée dans le fichier de licence.


