f5 tts mlx
0.2.3
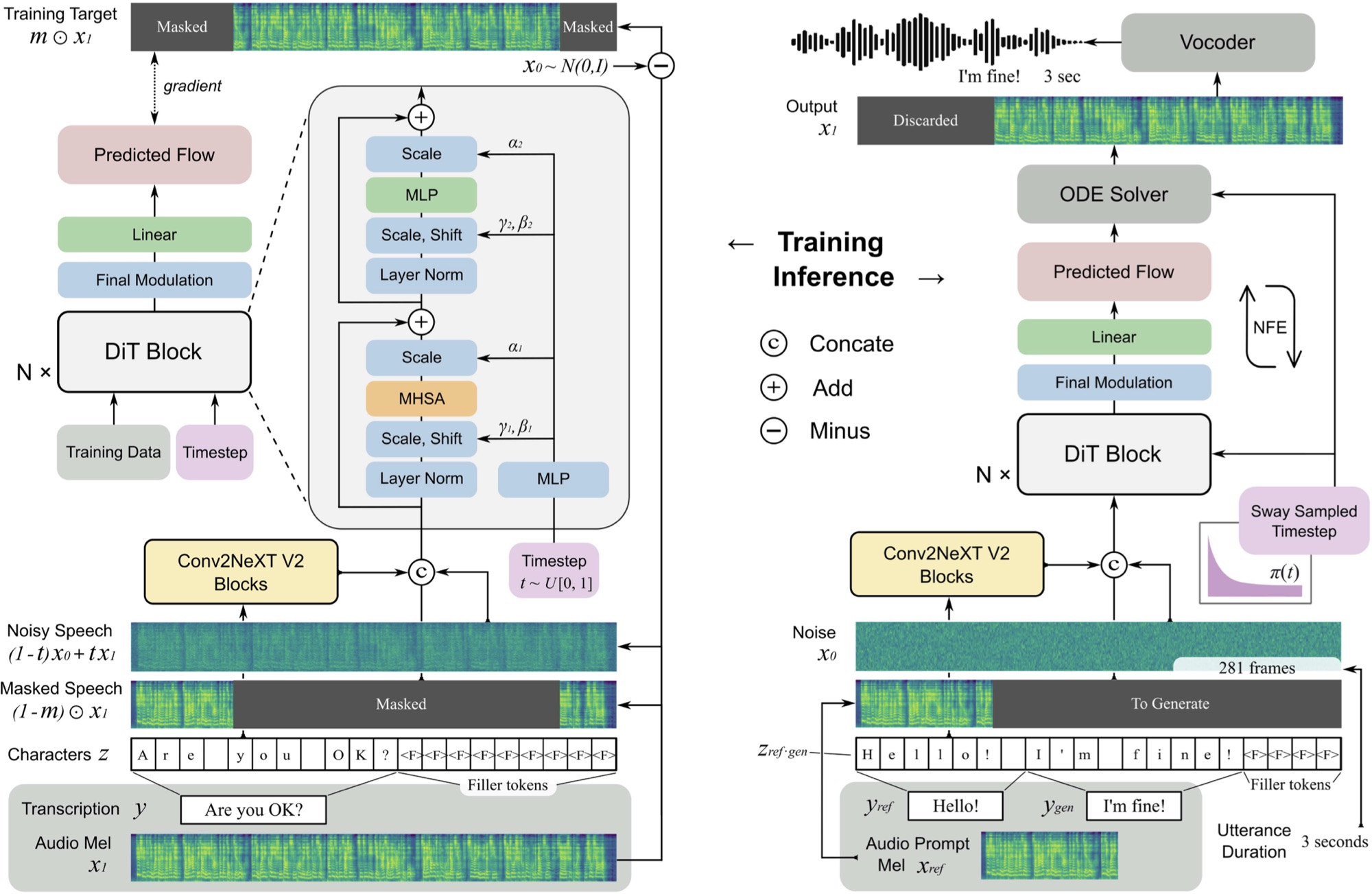
Implementierung von F5-TTs mit dem MLX-Framework.
F5 TTS ist ein nicht-autoregressives Text-zu-Sprach-System mit Null-Shot-System mit einem fließenden MEL-Spektrogrammgenerator mit einem Diffusionstransformator (DIT).
Sie können hier ein Beispiel anhören, das in ~ 11 Sekunden auf einem M3 Max MacBook Pro erzeugt wurde.
F5 ist eine Entwicklung von E2 TTs und verbessert die Leistung mit Convnext V2 -Blöcken für die gelernte Textausrichtung. Dieses Repository basiert auf der hier verfügbaren ursprünglichen Pytorch -Implementierung.
pip install f5-tts-mlxpython -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. "Sie können auch ein Rohr verwenden, um Sprache aus der Ausgabe eines anderen Prozesses zu generieren, beispielsweise aus einem Sprachmodell:
mlx_lm.generate --model mlx-community/Llama-3.2-1B-Instruct-4bit --verbose false
--temp 0 --max-tokens 512 --prompt " Write a concise paragraph explaning wavelets. "
| python -m f5_tts_mlx.generateWenn Sie Ihr eigenes Referenz-Audio-Beispiel verwenden möchten, stellen Sie sicher, dass es sich um eine 24-kHz-WAV-Datei mit rund 5 bis 10 Sekunden handelt:
python -m f5_tts_mlx.generate
--text " The quick brown fox jumped over the lazy dog. "
--ref-audio /path/to/audio.wav
--ref-text " This is the caption for the reference audio. "Sie können eine Audiodatei mit FFMPEG wie folgt in das richtige Format konvertieren:
ffmpeg -i /path/to/audio.wav -ac 1 -ar 24000 -sample_fmt s16 -t 10 /path/to/output_audio.wavWeitere Optionen zum Anpassen der Generation.
Wenn Sie sich in einer Bandbreite oder einer Speicherbeschränkung befinden, können Sie die Option --q verwenden, um eine quantisierte Version des Modells zu laden. 4-Bit- und 8-Bit-Varianten werden unterstützt.
python -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. " --q 4Sie können ein vorgezogenes Modell aus Python laden:
from f5_tts_mlx . generate import generate
audio = generate ( text = "Hello world." , ...)Vorbereitete Modellgewichte sind auch auf dem Umarmungsgesicht erhältlich.
Yushen Chen für die ursprüngliche Pytorch -Implementierung von F5 TTs und vorgezogenem Modell.
Phil Wang für die E2 TTS -Implementierung, auf der dieses Modell basiert.
@article { chen-etal-2024-f5tts ,
title = { F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching } ,
author = { Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen } ,
journal = { arXiv preprint arXiv:2410.06885 } ,
year = { 2024 } ,
} @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
}Der Code in diesem Repository wird unter der MIT -Lizenz veröffentlicht, wie in der Lizenzdatei gefunden.


