f5 tts mlx
0.2.3
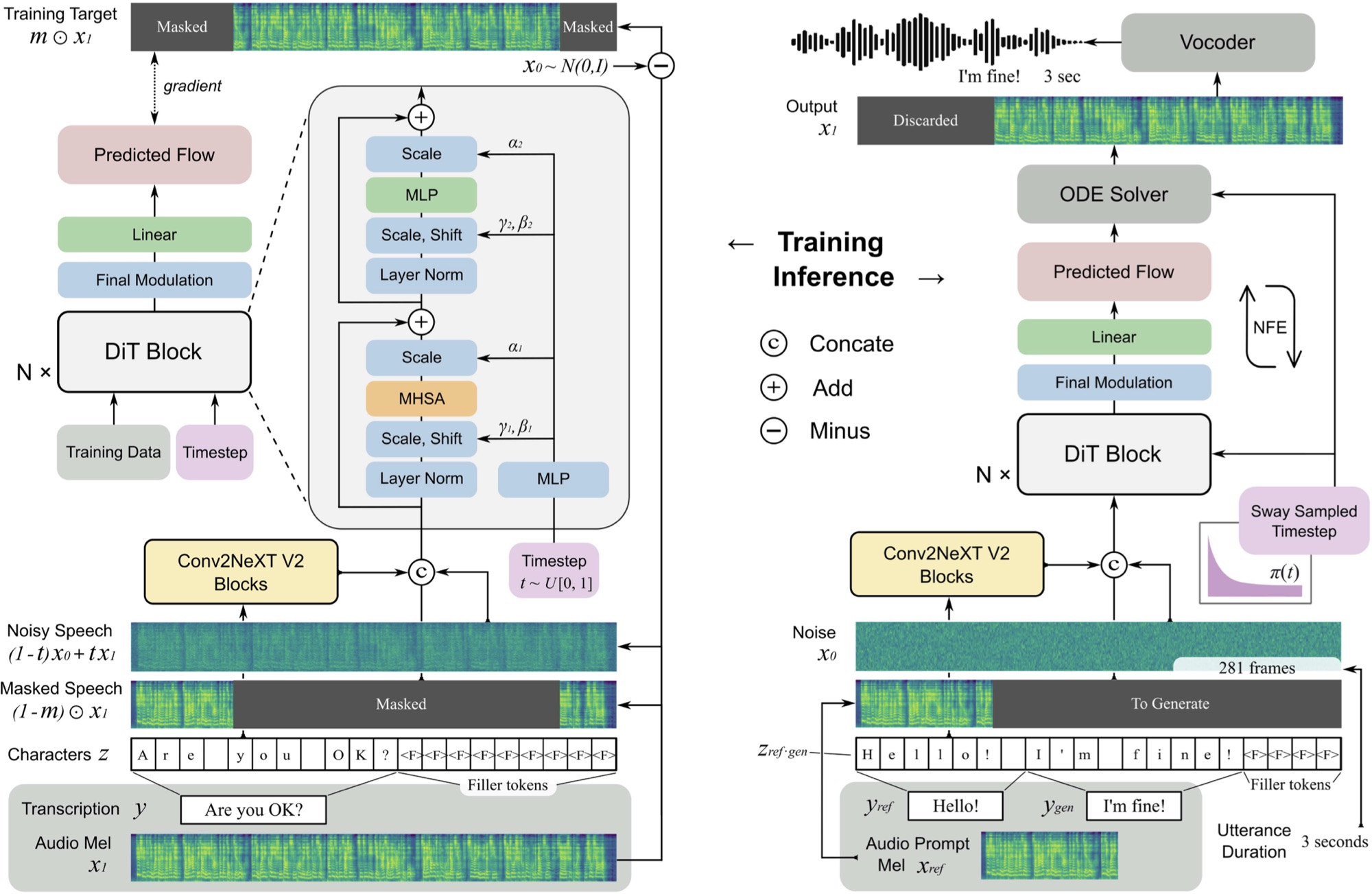
Реализация F5-TTS, с структурой MLX.
F5 TTS-это неавторегрессивная система с нулевым выстрелом в речь с использованием генератора спектрограммы MEL-соответствующего потока с диффузионным трансформатором (DIT).
Вы можете прослушать образец здесь, который был сгенерирован за ~ 11 секунд на M3 Max Macbook Pro.
F5 является эволюцией E2 TTS и повышает производительность с помощью блоков Convnext V2 для выравнивания обученного текста. Этот репозиторий основан на оригинальной реализации Pytorch, доступной здесь.
pip install f5-tts-mlxpython -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. "Вы также можете использовать трубу для генерации речи с вывода другого процесса, например, из языковой модели:
mlx_lm.generate --model mlx-community/Llama-3.2-1B-Instruct-4bit --verbose false
--temp 0 --max-tokens 512 --prompt " Write a concise paragraph explaning wavelets. "
| python -m f5_tts_mlx.generateЕсли вы хотите использовать свой собственный образец справочного аудио, убедитесь, что это моно, 24 кГц-вав, около 5-10 секунд:
python -m f5_tts_mlx.generate
--text " The quick brown fox jumped over the lazy dog. "
--ref-audio /path/to/audio.wav
--ref-text " This is the caption for the reference audio. "Вы можете преобразовать аудиофайл в правильный формат с FFMPEG, например:
ffmpeg -i /path/to/audio.wav -ac 1 -ar 24000 -sample_fmt s16 -t 10 /path/to/output_audio.wavСмотрите здесь для получения дополнительных вариантов настройки поколения.
Если вы находитесь в среде с ограниченной полосой или с ограниченной памятью, вы можете использовать опцию --q для загрузки квантовой версии модели. 4-битные и 8-битные варианты поддерживаются.
python -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. " --q 4Вы можете загрузить предварительную модель с Python:
from f5_tts_mlx . generate import generate
audio = generate ( text = "Hello world." , ...)Предварительно проведенные веса модели также доступны для обнимающегося лица.
Yushen Chen для оригинальной реализации Pytorch F5 TTS и предварительной модели.
Фил Ван для реализации E2 TTS, на которой основана эта модель.
@article { chen-etal-2024-f5tts ,
title = { F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching } ,
author = { Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen } ,
journal = { arXiv preprint arXiv:2410.06885 } ,
year = { 2024 } ,
} @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
}Код в этом репозитории выпускается по лицензии MIT, как найдено в файле лицензии.


