f5 tts mlx
0.2.3
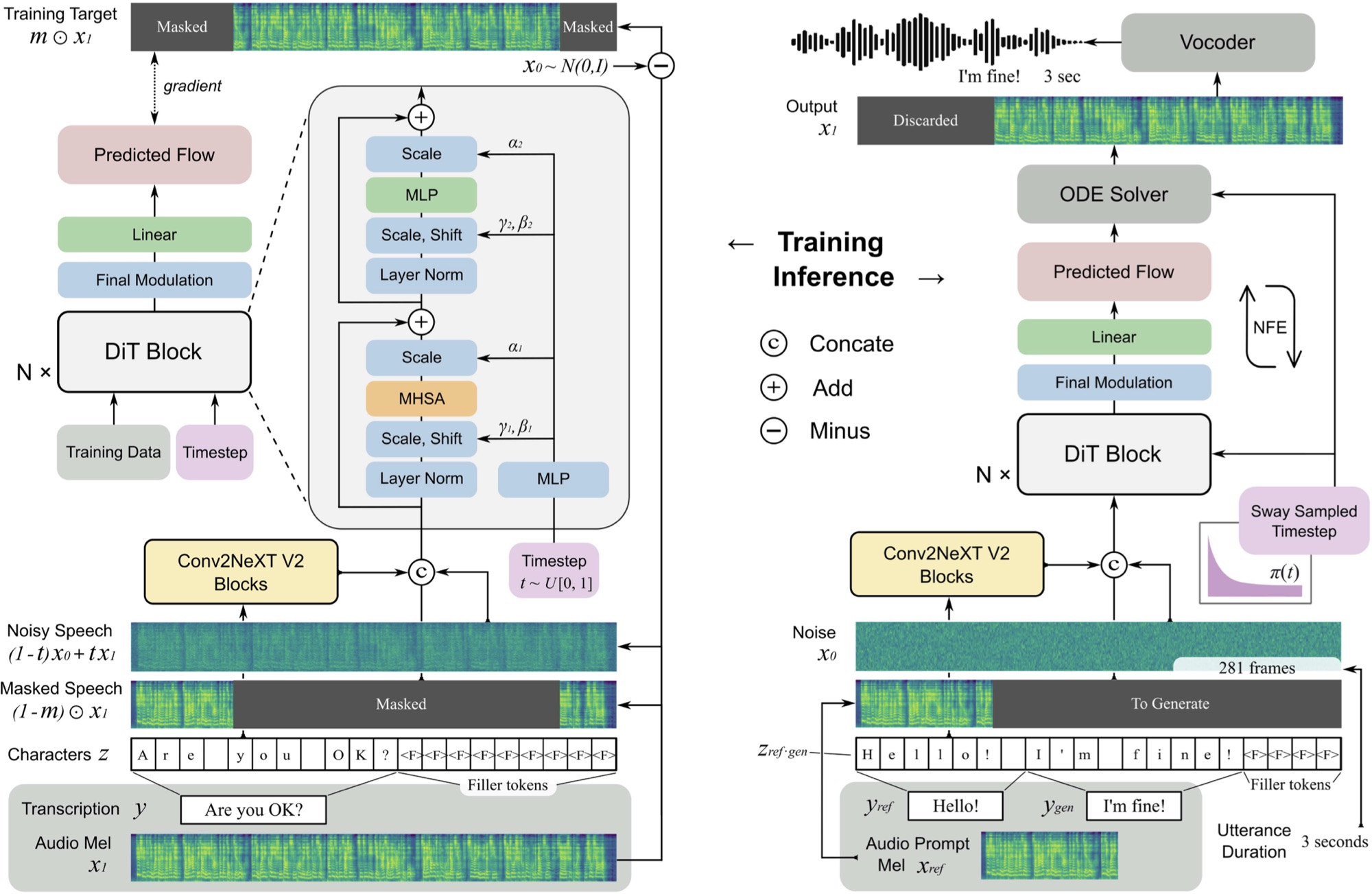
تنفيذ F5-TTS ، مع إطار MLX.
F5 TTS عبارة عن نظام نص إلى كلام غير متكافئ ، غير متكبر ، باستخدام مولد طيف MEL المطابق للتدفق مع محول انتشار (DIT).
يمكنك الاستماع إلى عينة هنا تم إنشاؤها في حوالي 11 ثانية على M3 Max MacBook Pro.
F5 هو تطور E2 TTS ويحسن الأداء مع كتل ConvNext V2 لمحاذاة النص المستفادة. يعتمد هذا المستودع على تطبيق Pytorch الأصلي المتاح هنا.
pip install f5-tts-mlxpython -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. "يمكنك أيضًا استخدام أنبوب لإنشاء خطاب من إخراج عملية أخرى ، على سبيل المثال من نموذج اللغة:
mlx_lm.generate --model mlx-community/Llama-3.2-1B-Instruct-4bit --verbose false
--temp 0 --max-tokens 512 --prompt " Write a concise paragraph explaning wavelets. "
| python -m f5_tts_mlx.generateإذا كنت ترغب في استخدام عينة الصوت المرجعية الخاصة بك ، فتأكد من أنه ملف WAV أحادي ، 24 كيلو هرتز من حوالي 5-10 ثانية:
python -m f5_tts_mlx.generate
--text " The quick brown fox jumped over the lazy dog. "
--ref-audio /path/to/audio.wav
--ref-text " This is the caption for the reference audio. "يمكنك تحويل ملف صوتي إلى التنسيق الصحيح مع FFMPEG مثل هذا:
ffmpeg -i /path/to/audio.wav -ac 1 -ar 24000 -sample_fmt s16 -t 10 /path/to/output_audio.wavانظر هنا للحصول على مزيد من الخيارات لتخصيص الجيل.
إذا كنت في نطاق ترددي أو بيئة محدودة للذاكرة ، فيمكنك استخدام الخيار- --q لتحميل إصدار كمي من النموذج. يتم دعم المتغيرات 4 بت و 8 بت.
python -m f5_tts_mlx.generate --text " The quick brown fox jumped over the lazy dog. " --q 4يمكنك تحميل نموذج مسبق من Python:
from f5_tts_mlx . generate import generate
audio = generate ( text = "Hello world." , ...)تتوفر أوزان نموذجية قبل المعانقة.
Yushen Chen لتنفيذ Pytorch الأصلي لـ F5 TTS والنموذج المسبق.
Phil Wang لتنفيذ E2 TTS الذي يعتمد عليه هذا النموذج.
@article { chen-etal-2024-f5tts ,
title = { F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching } ,
author = { Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen } ,
journal = { arXiv preprint arXiv:2410.06885 } ,
year = { 2024 } ,
} @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
}يتم إصدار الرمز في هذا المستودع بموجب ترخيص معهد ماساتشوستس للتكنولوجيا كما هو موجود في ملف الترخيص.


