YOLO v5
1.0.0
- - ตอนนี้ YOLOV5 ได้รับการอัปเดตเป็นเวอร์ชัน 6.0 แต่วิธีการฝึกอบรมนั้นเหมือนกับ repo นี้ คุณจะต้องติดตั้งสภาพแวดล้อม Python ที่สอดคล้องกันตามเวอร์ชันที่เกี่ยวข้อง การสร้างชุดข้อมูลการปรับเปลี่ยนไฟล์การกำหนดค่าวิธีการฝึกอบรม ฯลฯ มีความสอดคล้องกับ repo นี้อย่างสมบูรณ์!
- - เราให้บริการการโทร Tensorrt YOLOV5 และ INT8 Quantized C ++ และรหัส Python (วิธีการเร่งความเร็ว Tensorrt นั้นแตกต่างจากการเรียก tensorrt ที่จัดทำโดย repo นี้) ผู้ชายที่ยิ่งใหญ่ที่ต้องการสามารถฝากข้อความไว้ในประเด็น!
Xu Jing
เนื่องจากการปรับตัวของกระดูกสันหลังและพารามิเตอร์บางอย่างของ Yolo V5 เวอร์ชันใหม่อย่างเป็นทางการเพื่อนหลายคนได้ดาวน์โหลดรูปแบบที่ผ่านการฝึกอบรมมาก่อนอย่างเป็นทางการล่าสุดและไม่สามารถใช้งานได้ ที่นี่เรามีที่อยู่ดาวน์โหลดดิสก์ Baidu Cloud ของรุ่น Yolo V5 ที่ผ่านการฝึกอบรมมาก่อน
ลิงค์: https://pan.baidu.com/s/1sdwp6i_mnrlk45qdb3-ynw รหัสการแยก: 423J
YOLOV4 ยังไม่ได้ลดลง YOLOV5 ได้รับการปล่อยตัว!
เมื่อวันที่ 9 มิถุนายน Ultralytics เปิดแหล่งที่มาของ YOLOV5 น้อยกว่า 50 วันหลังจากการปล่อย YOLOV4 ล่าสุด และในครั้งนี้ YOLOV5 ถูกนำไปใช้อย่างสมบูรณ์ตาม Pytorch!
ผู้สนับสนุนหลักของ YOLO V5 คือผู้เขียนการเพิ่มประสิทธิภาพข้อมูลโมเสคที่เน้นใน YOLO V4

โครงการนี้อธิบายวิธีการฝึกอบรม YOLO V5 ตามชุดข้อมูลของคุณเอง
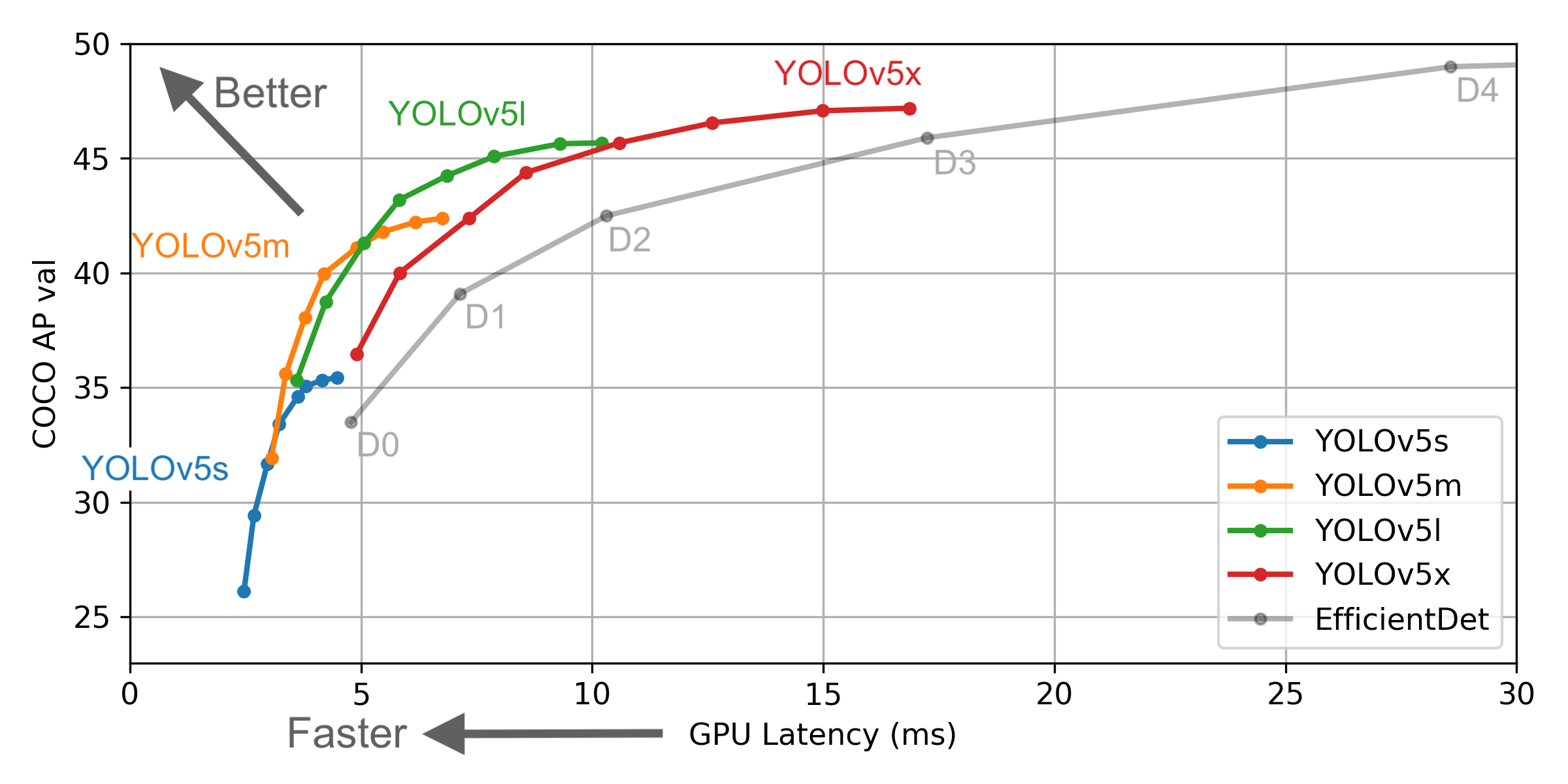
อย่างไรก็ตามมีความแตกต่างระหว่างข้อมูลที่จัดทำโดย Yolo V4 และข้อมูลอย่างเป็นทางการ:
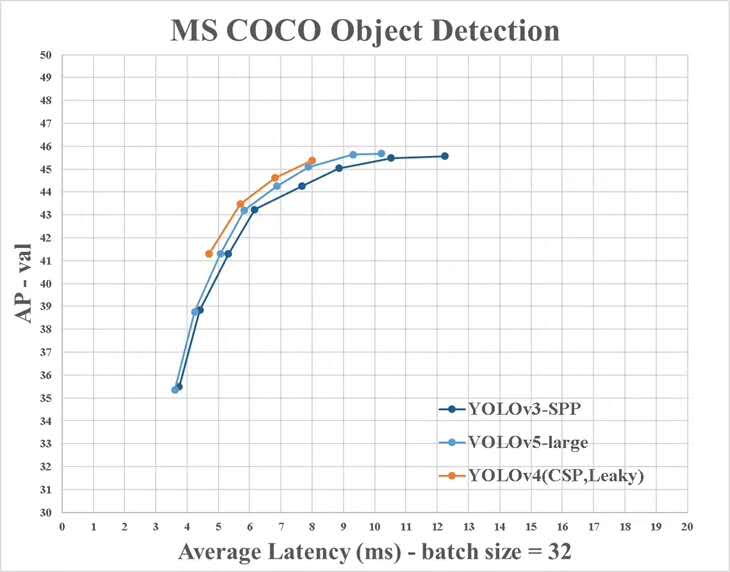
ติดตั้งแพ็คเกจ Python ที่จำเป็นและกำหนดค่าสภาพแวดล้อมที่เกี่ยวข้อง
# python3.6
# torch==1.3.0
# torchvision==0.4.1
# git clone yolo v5 repo
git clone https://github.com/ultralytics/yolov5 # clone repo
# 下载官方的样例数据(这一步可以省略)
python3 -c "from yolov5.utils.google_utils import gdrive_download; gdrive_download('1n_oKgR81BJtqk75b00eAjdv03qVCQn2f','coco128.zip')" # download dataset
cd yolov5
# 安装必要的package
pip3 install -U -r requirements.txt
dataset.yaml ข้อมูลไฟล์กำหนดค่า. yaml ของชุดข้อมูล Data/Coco128.yaml มาจากภาพการฝึกอบรม 128 ภาพแรกของชุดข้อมูล Coco Train2017 คุณสามารถแก้ไขไฟล์ yaml ของชุดข้อมูลของคุณเองตาม yaml นี้
# train and val datasets (image directory or *.txt file with image paths)
train: ./datasets/score/images/train/
val: ./datasets/score/images/val/
# number of classes
nc: 3
# class names
names: ['QP', 'NY', 'QG']
คุณสามารถใช้ LabelImg, LabMe, LabelBox และ CVAT เพื่อติดฉลากข้อมูล สำหรับการตรวจจับเป้าหมายคุณต้องติดฉลากกล่องขอบเขต จากนั้นคุณต้องแปลงคำอธิบายประกอบเป็นรูปแบบคำอธิบายประกอบเดียวกันกับ รูปแบบ DarkNet และแต่ละภาพจะสร้างไฟล์คำอธิบายประกอบ *.txt (หากภาพไม่มีเป้าหมายคำอธิบายประกอบคุณไม่จำเป็นต้องสร้างไฟล์ *.txt ) ไฟล์ *.txt ที่สร้างขึ้นตามกฎต่อไปนี้:
class x_center y_center width height def convert ( size , box ):
'''
将标注的xml文件标注转换为darknet形的坐标
'''
dw = 1. / ( size [ 0 ])
dh = 1. / ( size [ 1 ])
x = ( box [ 0 ] + box [ 1 ]) / 2.0 - 1
y = ( box [ 2 ] + box [ 3 ]) / 2.0 - 1
w = box [ 1 ] - box [ 0 ]
h = box [ 3 ] - box [ 2 ]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return ( x , y , w , h ) แต่ละคำอธิบายประกอบ *.txt จะถูกเก็บไว้ในไดเรกทอรีไฟล์คล้ายกับรูปภาพ คุณจะต้องแทนที่ /images/*.jpg ด้วย /lables/*.txt (การประมวลผลภายในรหัสนี้เป็นเช่นนี้เมื่อโหลดข้อมูลคุณสามารถแก้ไขได้ในรูปแบบข้อมูล VOC สำหรับการโหลด)
ตัวอย่างเช่น:
datasets/score/images/train/000000109622.jpg # image
datasets/score/labels/train/000000109622.txt # label
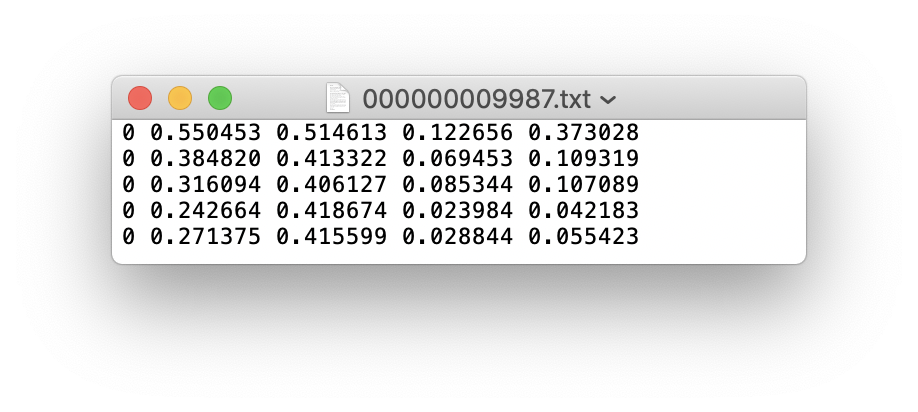
หากไฟล์ฉลากมี 5 หมวดหมู่บุคคล (บุคคลเป็นหมวดหมู่แรกในชุดข้อมูล COCO ดังนั้นดัชนีคือ 0):
จัดเก็บโฟลเดอร์รูปภาพและฉลากของชุดฝึกอบรมและชุดตรวจสอบ Val ดังนี้

ณ จุดนี้ขั้นตอนการเตรียมข้อมูลเสร็จสิ้นแล้ว ในระหว่างกระบวนการเราสันนิษฐานว่ากระบวนการทำความสะอาดข้อมูลของวิศวกรอัลกอริทึมและกระบวนการแผนกชุดข้อมูลเสร็จสมบูรณ์ด้วยตัวเอง
เลือกรุ่นที่ต้องได้รับการฝึกอบรมในโฟลเดอร์ ./models โมเดลโฟลเดอร์ ที่นี่เราเลือก yolov5x.yaml ซึ่งเป็นรุ่นที่ใหญ่ที่สุดสำหรับการฝึกอบรม อ้างถึงตารางใน ReadMe อย่างเป็นทางการเพื่อทำความเข้าใจขนาดและความเร็วการอนุมานของรุ่นที่แตกต่างกัน หากคุณเลือกโมเดลคุณต้องแก้ไขไฟล์ yaml ที่สอดคล้องกับโมเดล
# parameters
nc : 3 # number of classes <------------------ UPDATE to match your dataset
depth_multiple : 1.33 # model depth multiple
width_multiple : 1.25 # layer channel multiple
# anchors
anchors :
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov5 backbone
backbone :
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 1-P1/2
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]], # 10
]
# yolov5 head
head :
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# Train yolov5x on score for 300 epochs
$ python3 train.py --img-size 640 --batch-size 16 --epochs 300 --data ./data/score.yaml --cfg ./models/score/yolov5x.yaml --weights weights/yolov5x.pt
หลังจากเริ่มการฝึกอบรมให้ตรวจสอบภาพ train*.jpg เพื่อดูข้อมูลการฝึกอบรมฉลากและการปรับปรุงข้อมูล หากภาพของคุณแสดงฉลากหรือการปรับปรุงข้อมูลไม่ถูกต้องคุณควรตรวจสอบว่ามีปัญหาใด ๆ กับกระบวนการก่อสร้างของชุดข้อมูลของคุณหรือไม่
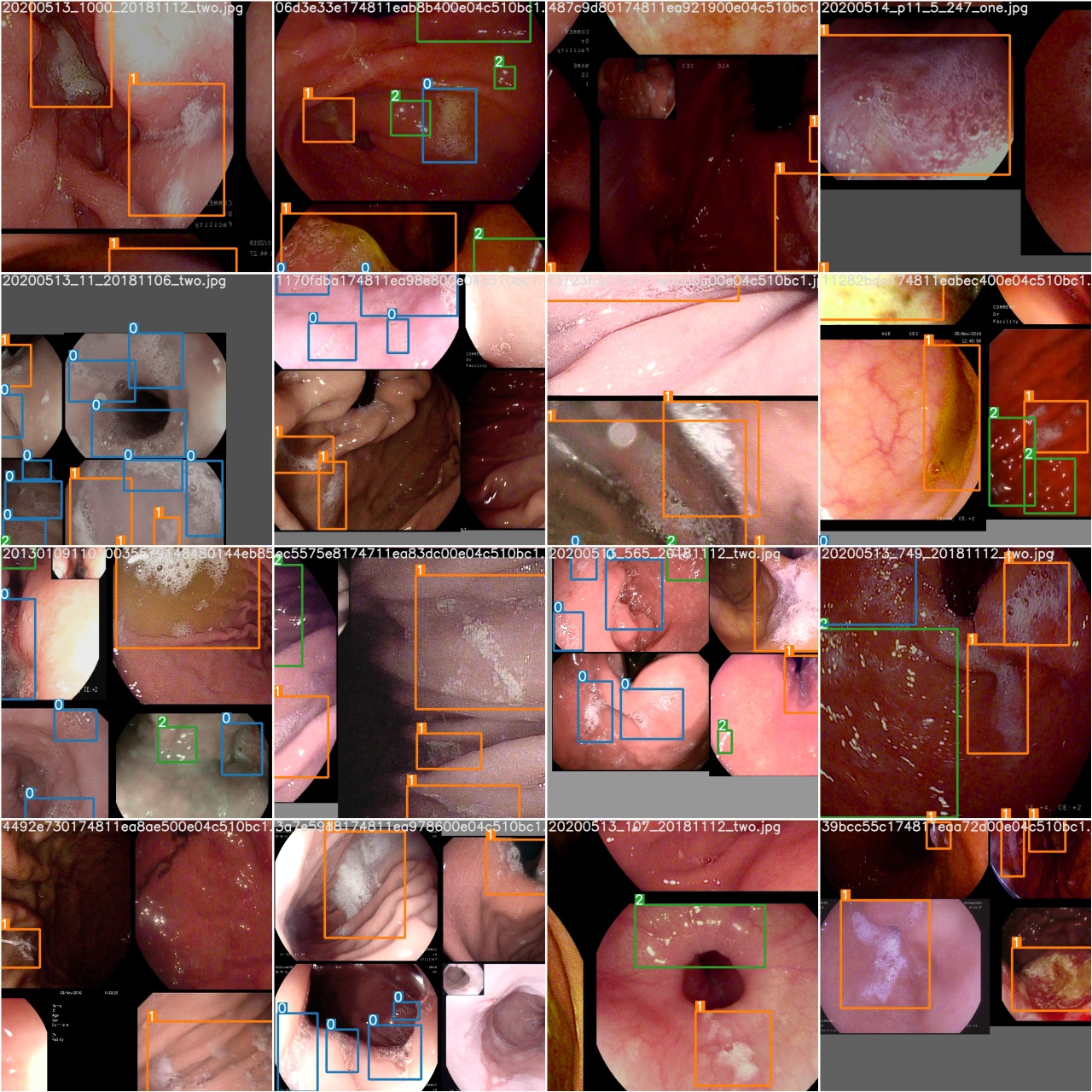
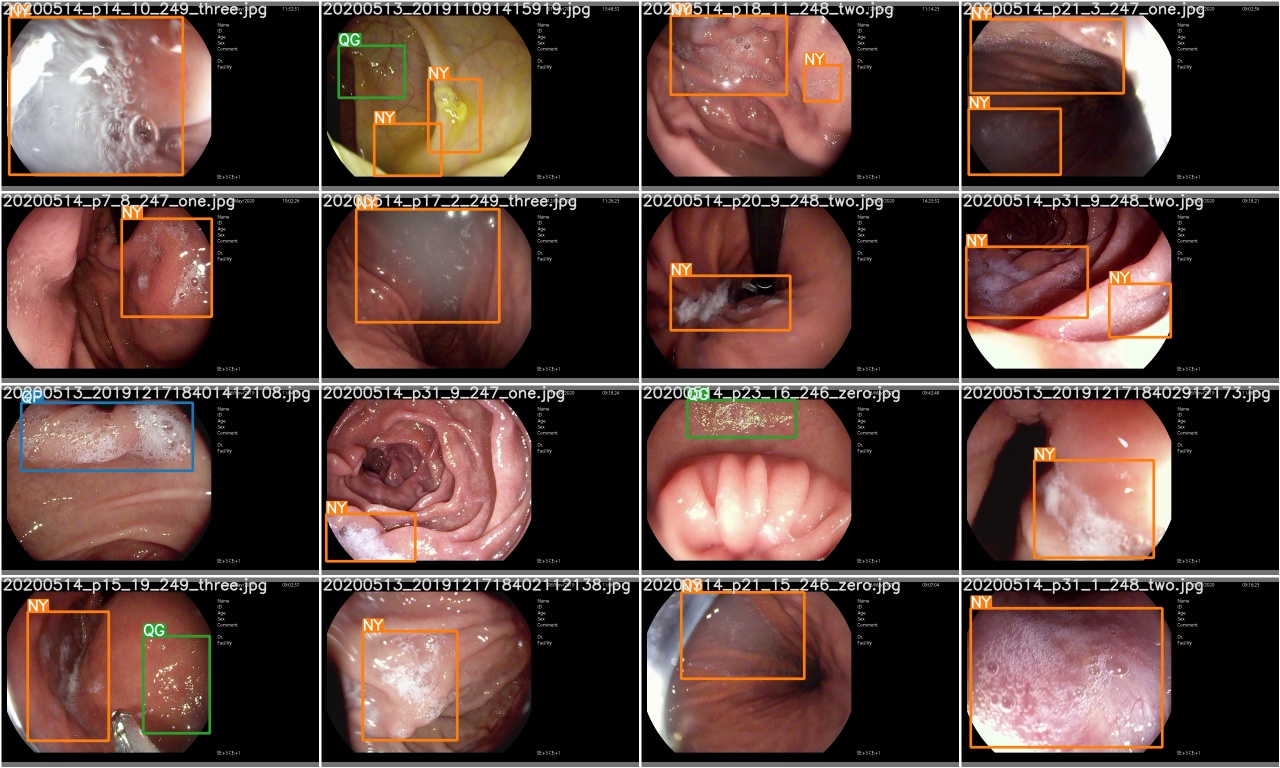
หลังจากยุคการฝึกอบรมเสร็จสมบูรณ์ให้ตรวจสอบ test_batch0_gt.jpg เพื่อดูฉลากของแบทช์ 0 ความจริงภาคพื้นดิน
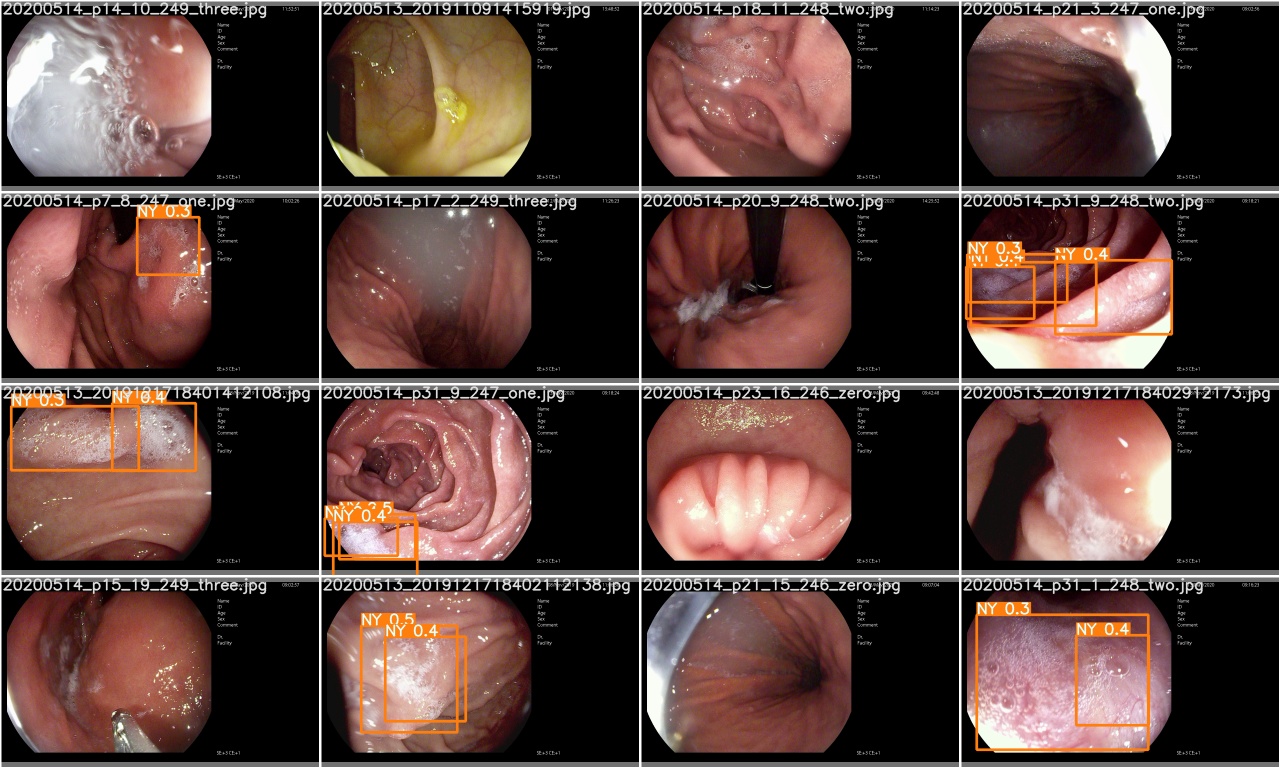
ตรวจสอบ test_batch0_pred.jpg เพื่อดูการทำนายชุดทดสอบ 0
การสูญเสียการฝึกอบรมและตัวชี้วัดการประเมินผลจะถูกบันทึกไว้ใน Tensorboard และ results.txt ไฟล์บันทึก TXT results.txt จะถูกมองเห็นเป็น results.png หลังจากการฝึกเสร็จสิ้น
> >> from utils . utils import plot_results
> >> plot_results ()
# 如果你是用远程连接请安装配置Xming: https://blog.csdn.net/akuoma/article/details/82182913 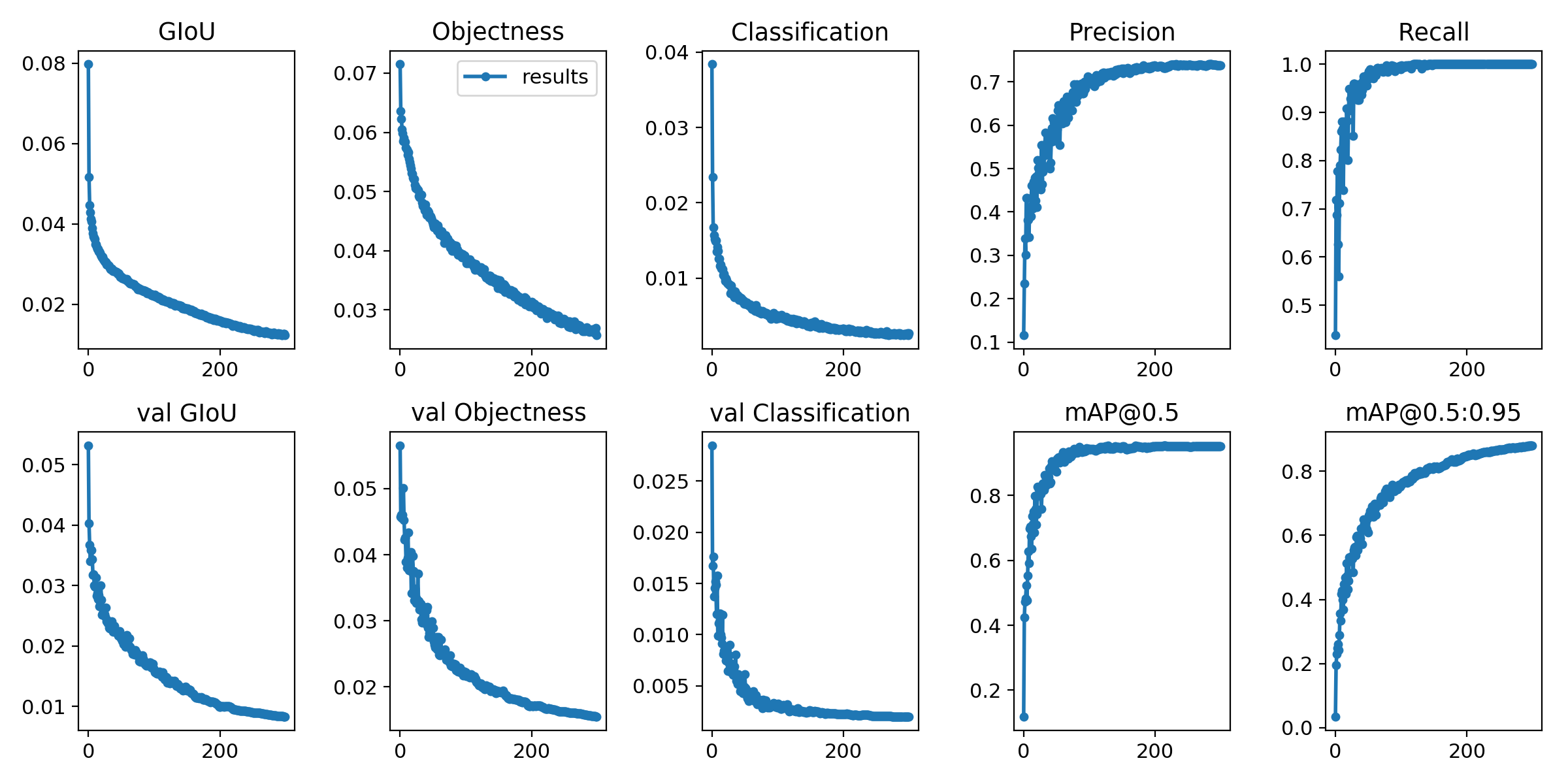
$ python3 detect . py - - source file . jpg # image
file . mp4 # video
. / dir # directory
0 # webcam
rtsp : // 170.93 . 143.139 / rtplive / 470011e600 ef003a004ee33696235daa # rtsp stream
http : // 112.50 . 243.8 / PLTV / 88888888 / 224 / 3221225900 / 1. m3u8 # http stream # inference /home/myuser/xujing/EfficientDet-Pytorch/dataset/test/ 文件夹下的图像
$ python3 detect . py - - source / home / myuser / xujing / EfficientDet - Pytorch / dataset / test / - - weights weights / best . pt - - conf 0.1
$ python3 detect . py - - source . / inference / images / - - weights weights / yolov5x . pt - - conf 0.5
# inference 视频
$ python3 detect . py - - source test . mp4 - - weights weights / yolov5x . pt - - conf 0.4 
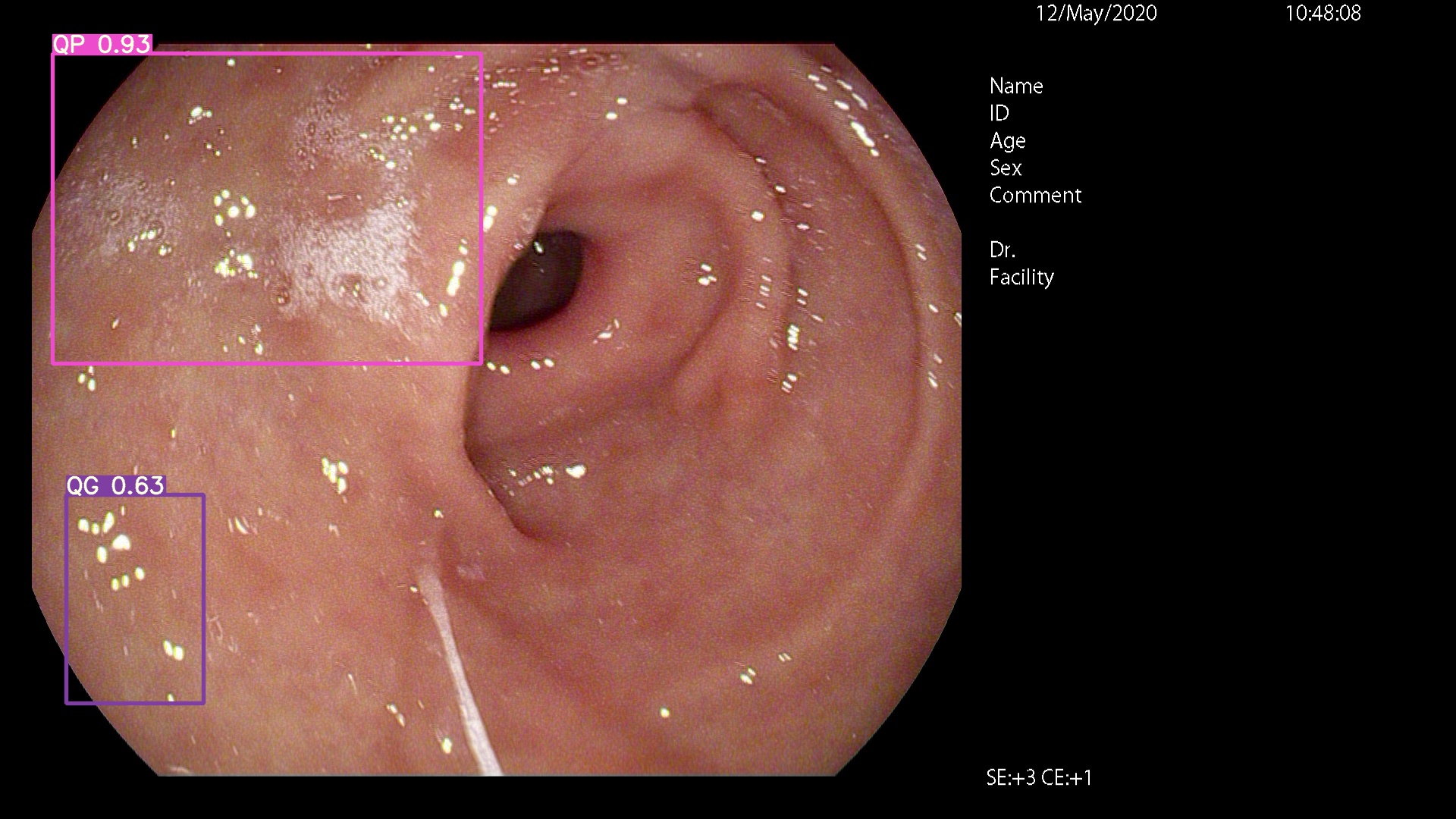
กรุณามาที่นี่
อ้างอิง
[1] .https: //github.com/ultralytics/yolov5
[2] .https: //github.com/ultralytics/yolov5/wiki/train-custom-data


