YOLO v5
1.0.0
؟ ؟ تم تحديث YOLOV5 الآن إلى الإصدار 6.0 ، ولكن طريقة التدريب الخاصة بها هي نفسها مثل هذا الريبو. تحتاج فقط إلى تثبيت بيئة Python المقابلة وفقًا للنسخة المقابلة. إن بناء مجموعة البيانات الخاصة بها ، وتعديل ملفات التكوين ، وطريقة التدريب ، وما إلى ذلك ، يتوافق تمامًا مع هذا الريبو!
؟ ؟ نحن نقدم مكالمات Tensorrt YOLOV5 ورمز C ++ الكمي ورمز Python (طريقة تسارع Tensorrt مختلفة عن مكالمات Tensorrt التي توفرها هذا الريبو). يمكن للرجال الكبار في حاجة أن يترك رسالة في القضايا!
شو جينغ
نظرًا لتعديل العمود الفقري وبعض المعلمات من الإصدار الجديد الرسمي من Yolo V5 ، قام العديد من الأصدقاء بتنزيل أحدث طراز رسمي تم تدريبه مسبقًا وغير متاحون. نحن هنا نقدم عنوان تنزيل Daidu Cloud Disk للنموذج الأصلي الذي تم تدريبه مسبقًا Yolo V5.
الرابط: https://pan.baidu.com/s/1sdwp6i_mnrlk45qdb3-ynw رمز الاستخراج: 423J
YOLOV4 لم يهدأ بعد ، تم إصدار YOLOV5!
في 9 يونيو ، افتتح Ultralytics مصدر Yolov5 ، بعد أقل من 50 يومًا من إطلاق آخر Yolov4. وهذه المرة ، يتم تنفيذ YOLOV5 بالكامل بناءً على Pytorch!
المساهم الرئيسي في YOLO V5 هو مؤلف كتاب تعزيز بيانات الفسيفساء الذي تم تسليط الضوء عليه في Yolo V4

يصف هذا المشروع كيفية تدريب Yolo V5 استنادًا إلى مجموعة البيانات الخاصة بك
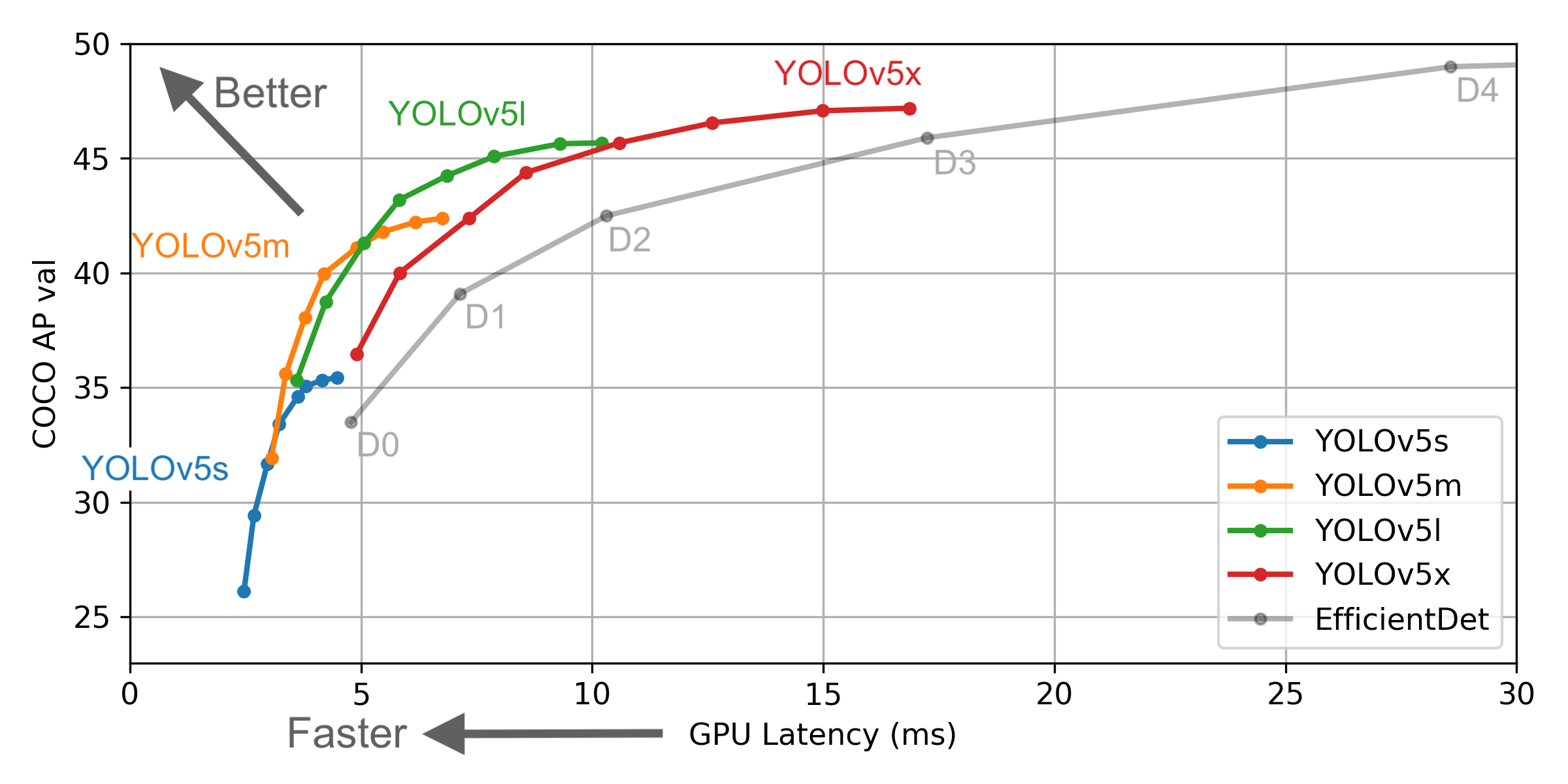
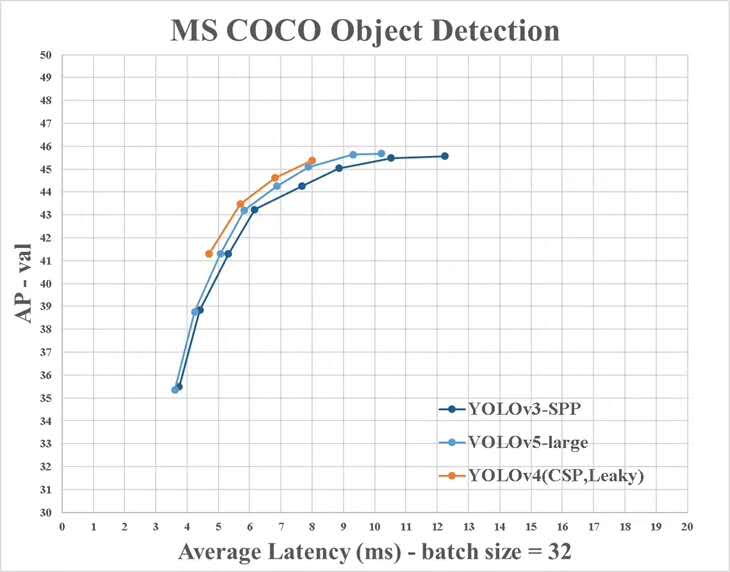
ومع ذلك ، هناك بعض الاختلافات بين المعلومات التي توفرها YOLO V4 والرسوم الرسمية:
تثبيت حزمة Python اللازمة وتكوين البيئات ذات الصلة
# python3.6
# torch==1.3.0
# torchvision==0.4.1
# git clone yolo v5 repo
git clone https://github.com/ultralytics/yolov5 # clone repo
# 下载官方的样例数据(这一步可以省略)
python3 -c "from yolov5.utils.google_utils import gdrive_download; gdrive_download('1n_oKgR81BJtqk75b00eAjdv03qVCQn2f','coco128.zip')" # download dataset
cd yolov5
# 安装必要的package
pip3 install -U -r requirements.txt
dataset.yaml ملفات التكوين. YAML من مجموعة البيانات Data/Coco128.yaml تأتي من أول 128 صورة تدريب لمجموعة بيانات Coco Train2017. يمكنك تعديل ملف yaml لمجموعة البيانات الخاصة بك بناءً على هذا yaml
# train and val datasets (image directory or *.txt file with image paths)
train: ./datasets/score/images/train/
val: ./datasets/score/images/val/
# number of classes
nc: 3
# class names
names: ['QP', 'NY', 'QG']
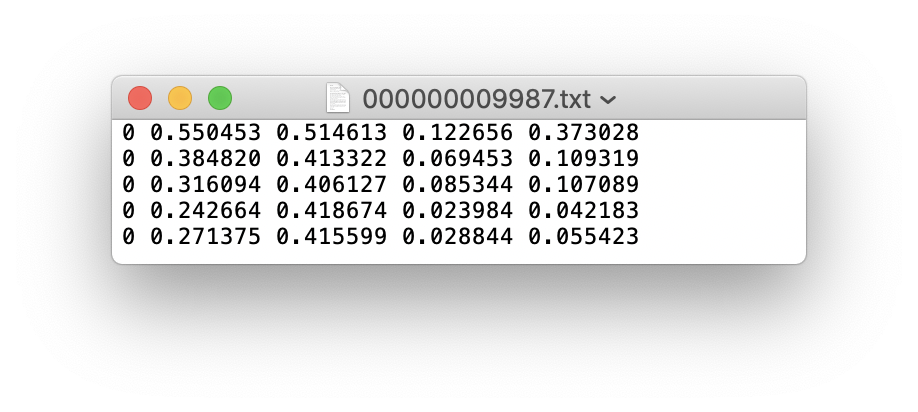
يمكنك استخدام Labelimg و Labme و Labelbox و CVAT لتسمية البيانات. للكشف عن الهدف ، تحتاج إلى تسمية مربع المحيط. ثم تحتاج إلى تحويل التعليق التوضيحي إلى نفس نموذج التعليقات التوضيحية مثل تنسيق DarkNet ، وتولد كل صورة ملف التعليق التوضيحي *.txt (إذا لم يكن للصورة هدف التعليق ، فأنت لا تحتاج إلى إنشاء ملف *.txt ). يتبع ملف *.txt الذي تم إنشاؤه القواعد التالية:
class x_center y_center width height def convert ( size , box ):
'''
将标注的xml文件标注转换为darknet形的坐标
'''
dw = 1. / ( size [ 0 ])
dh = 1. / ( size [ 1 ])
x = ( box [ 0 ] + box [ 1 ]) / 2.0 - 1
y = ( box [ 2 ] + box [ 3 ]) / 2.0 - 1
w = box [ 1 ] - box [ 0 ]
h = box [ 3 ] - box [ 2 ]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return ( x , y , w , h ) يتم تخزين كل تعليق *.txt تحتاج فقط إلى استبدال /images/*.jpg بـ /lables/*.txt (هذه الكود المعالجة الداخلية مثل هذا عند تحميل البيانات. يمكنك تعديلها إلى تنسيق بيانات VOC للتحميل)
على سبيل المثال:
datasets/score/images/train/000000109622.jpg # image
datasets/score/labels/train/000000109622.txt # label
إذا كان ملف التسمية يحتوي على 5 فئات أشخاص (الشخص هو الفئة الأولى في مجموعة بيانات COCO ، وبالتالي فإن الفهرس هو 0):
قم بتخزين مجلدات الصور والملصقات في مجموعة التدريب ومجموعة التحقق من Val على النحو التالي

في هذه المرحلة ، تم الانتهاء من مرحلة إعداد البيانات. خلال هذه العملية ، نفترض أن عملية تنظيف البيانات ومجموعة البيانات الخاصة بمهندس الخوارزمية قد تم الانتهاء منها.
حدد نموذجًا يحتاج إلى تدريب في مجلد ./models . هنا نختار yolov5x.yaml ، أكبر نموذج للتدريب. ارجع إلى الجدول في ReadMe الرسمي لفهم حجم وسرعة الاستدلال للنماذج المختلفة. إذا كنت قد حددت نموذجًا ، فأنت بحاجة إلى تعديل ملف yaml المقابل للنموذج
# parameters
nc : 3 # number of classes <------------------ UPDATE to match your dataset
depth_multiple : 1.33 # model depth multiple
width_multiple : 1.25 # layer channel multiple
# anchors
anchors :
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov5 backbone
backbone :
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 1-P1/2
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]], # 10
]
# yolov5 head
head :
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# Train yolov5x on score for 300 epochs
$ python3 train.py --img-size 640 --batch-size 16 --epochs 300 --data ./data/score.yaml --cfg ./models/score/yolov5x.yaml --weights weights/yolov5x.pt
بعد بدء التدريب ، تحقق من الصورة train*.jpg لعرض بيانات التدريب والعلامات وتحسينات البيانات. إذا كانت صورتك تعرض الملصقات أو تحسينات البيانات غير صحيحة ، فيجب عليك التحقق مما إذا كانت هناك مشكلة في عملية بناء مجموعة البيانات الخاصة بك.
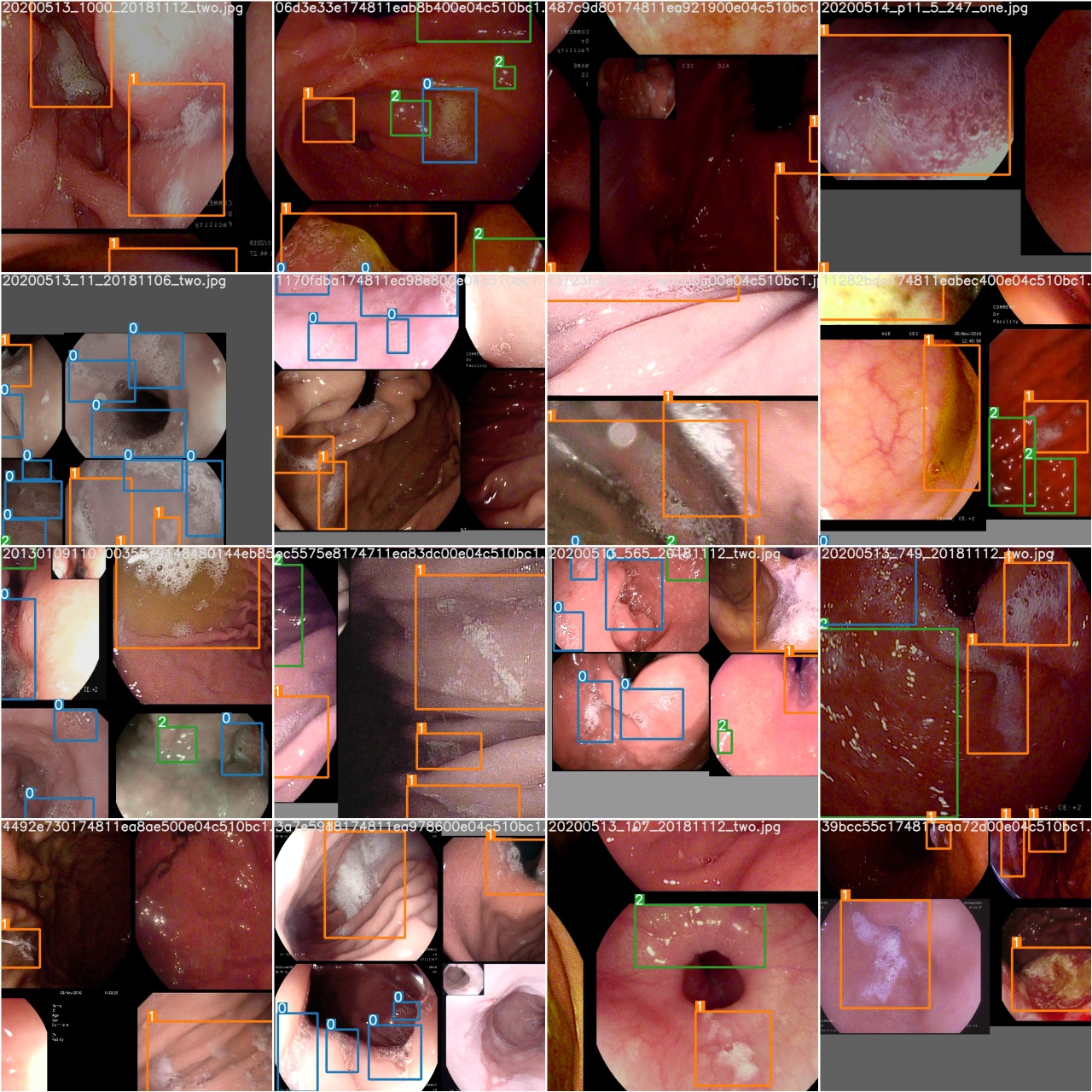
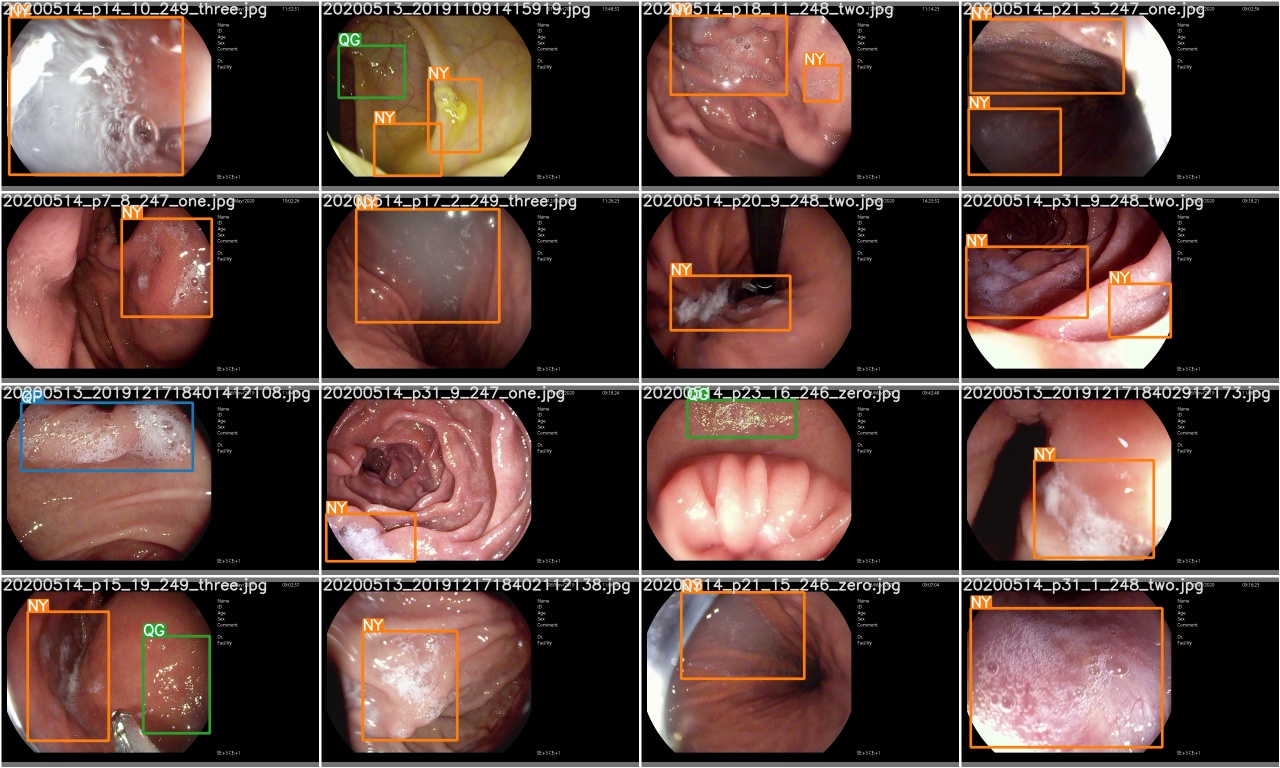
بعد اكتمال فترة تدريب ، test_batch0_gt.jpg
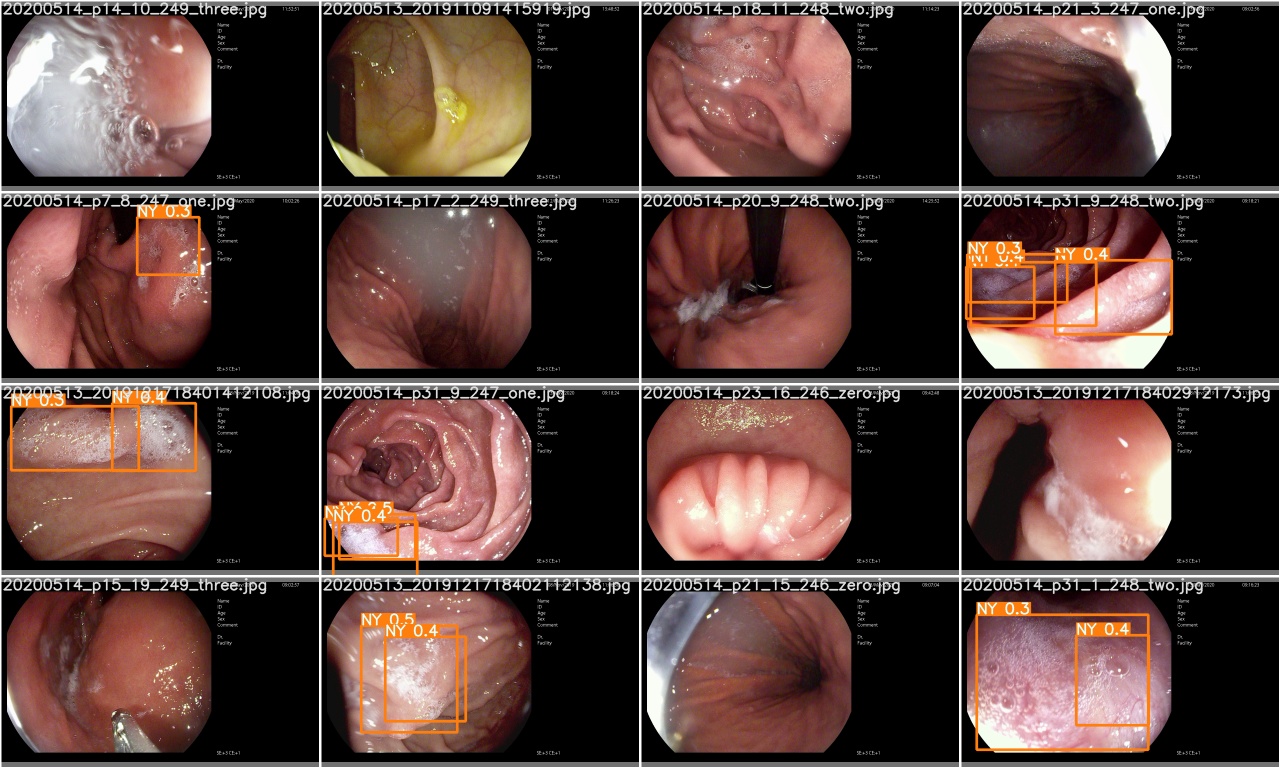
تحقق من test_batch0_pred.jpg لمعرفة التنبؤ بدفعات الاختبار 0
يتم حفظ خسائر التدريب ومقاييس التقييم في ملفات سجل Tensorboard و results.txt . سيتم تصور results.txt results.png
> >> from utils . utils import plot_results
> >> plot_results ()
# 如果你是用远程连接请安装配置Xming: https://blog.csdn.net/akuoma/article/details/82182913 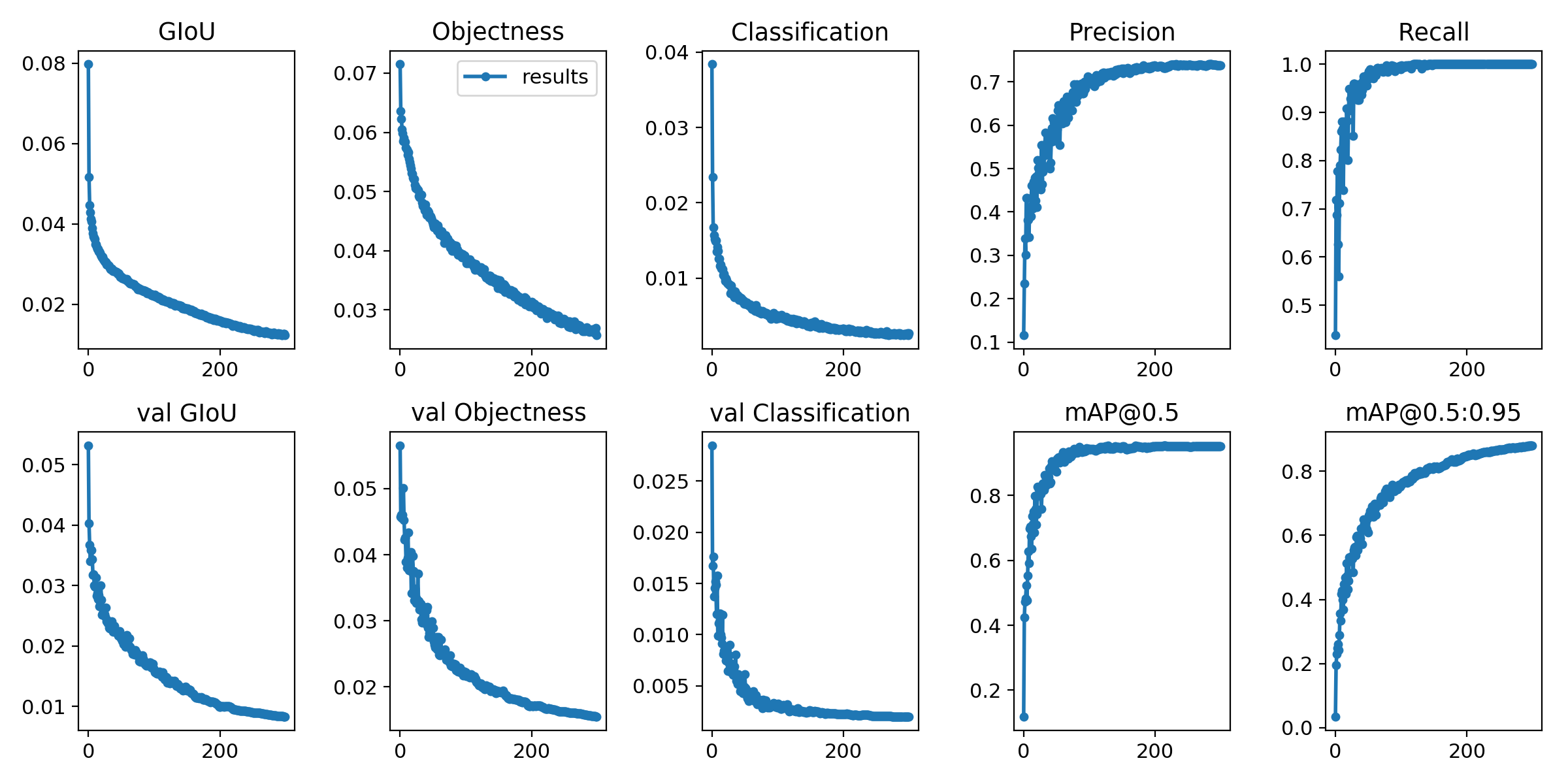
$ python3 detect . py - - source file . jpg # image
file . mp4 # video
. / dir # directory
0 # webcam
rtsp : // 170.93 . 143.139 / rtplive / 470011e600 ef003a004ee33696235daa # rtsp stream
http : // 112.50 . 243.8 / PLTV / 88888888 / 224 / 3221225900 / 1. m3u8 # http stream # inference /home/myuser/xujing/EfficientDet-Pytorch/dataset/test/ 文件夹下的图像
$ python3 detect . py - - source / home / myuser / xujing / EfficientDet - Pytorch / dataset / test / - - weights weights / best . pt - - conf 0.1
$ python3 detect . py - - source . / inference / images / - - weights weights / yolov5x . pt - - conf 0.5
# inference 视频
$ python3 detect . py - - source test . mp4 - - weights weights / yolov5x . pt - - conf 0.4 
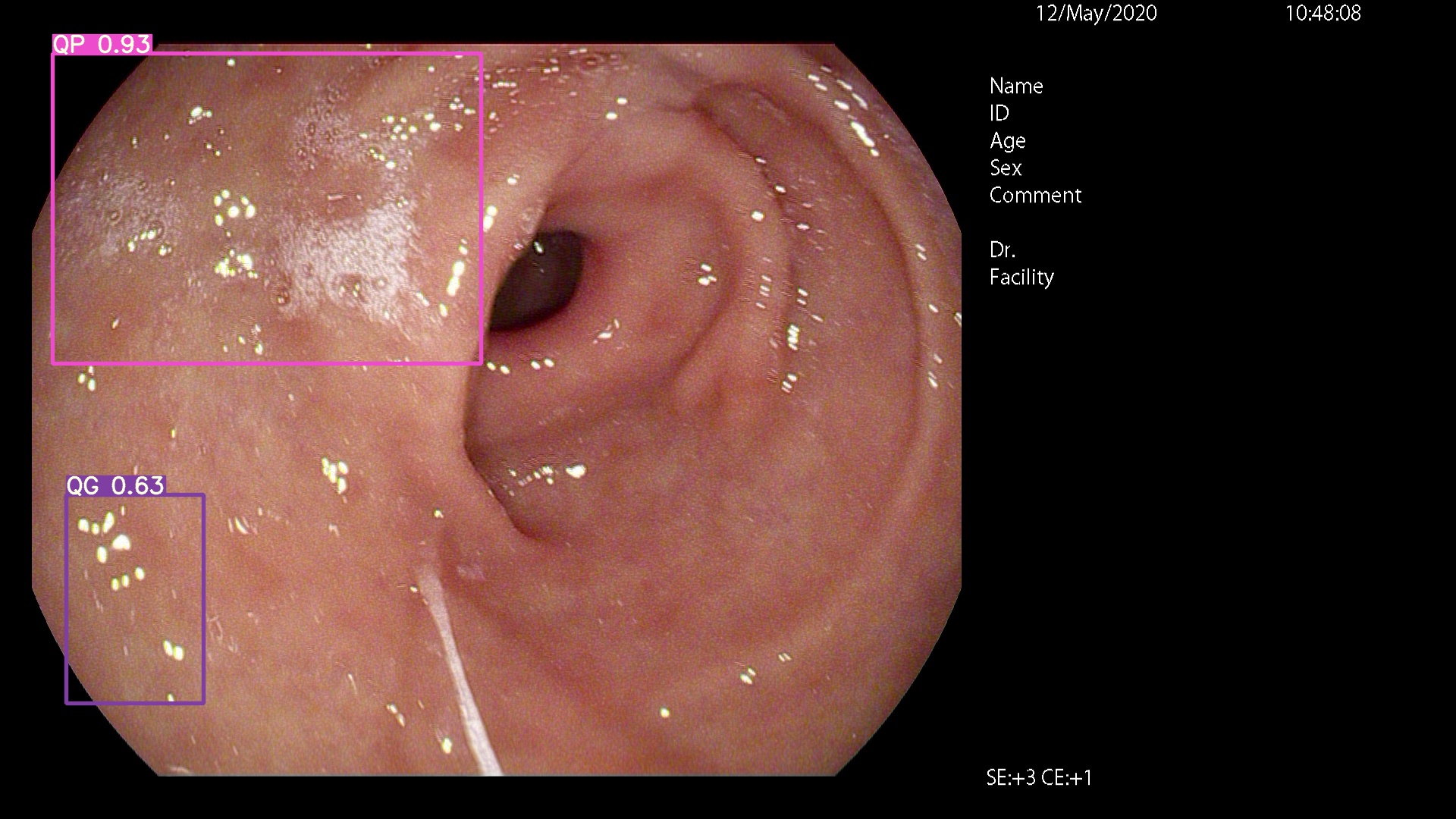
من فضلك تعال إلى هنا
مرجع
[1] .https: //github.com/ultralytics/yolov5
[2] .https: //github.com/ultralytics/yolov5/wiki/train-custom-data


