YOLO v5
1.0.0
? ? Agora o Yolov5 foi atualizado para a versão 6.0, mas seu método de treinamento é o mesmo que este repositório. Você só precisa instalar o ambiente Python correspondente de acordo com a versão correspondente. A construção de seu conjunto de dados, modificação de arquivo de configuração, método de treinamento etc. é completamente consistente com este repositório!
? ? Fornecemos chamadas Yolov5 Tensorrt e Int8 Quantized C ++ e código Python (o método de aceleração da tensorrt é diferente das chamadas de tensorrt fornecidas por este repositório). Os grandes caras necessitados podem deixar uma mensagem em questões!
Xu Jing
Devido ao ajuste da espinha dorsal e a alguns parâmetros da nova versão oficial do YOLO V5, muitos amigos baixaram o mais recente modelo oficial pré-treinado e não estão disponíveis. Aqui, fornecemos o endereço de download do disco do Baidu Cloud do modelo pré-treinado YOLO V5 original.
Link: https://pan.baidu.com/s/1sdwp6i_mnrlk45qdb3-ynw Código de extração: 423J
Yolov4 ainda não diminuiu, o Yolov5 foi lançado!
Em 9 de junho, a Ultralytics abriu a fonte do Yolov5, menos de 50 dias após o lançamento do último Yolov4. E desta vez, o Yolov5 é completamente implementado com base no Pytorch!
O principal colaborador do YOLO V5 é o autor do aprimoramento de dados em mosaico destacado em Yolo V4

Este projeto descreve como treinar Yolo V5 com base no seu próprio conjunto de dados
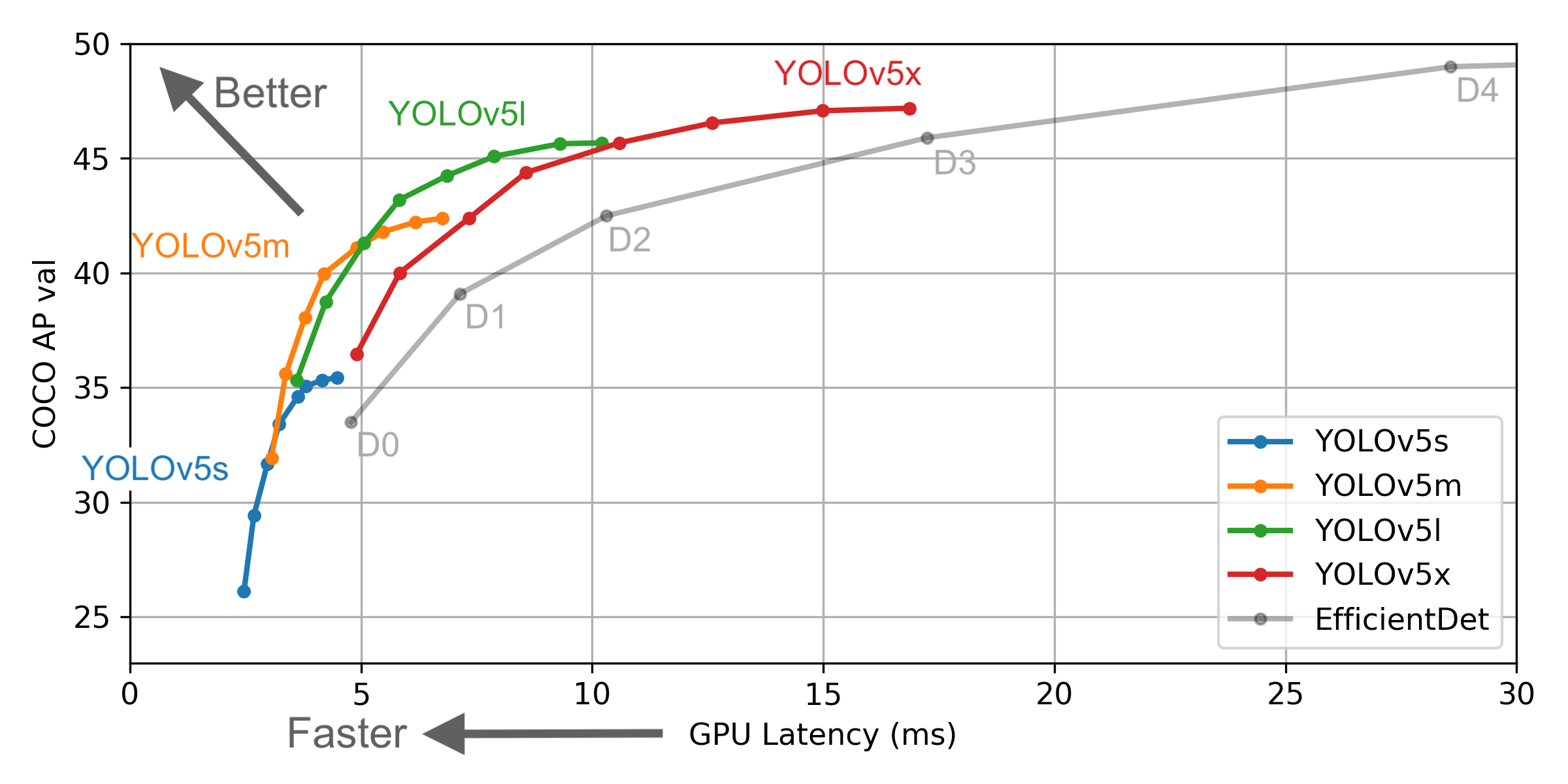
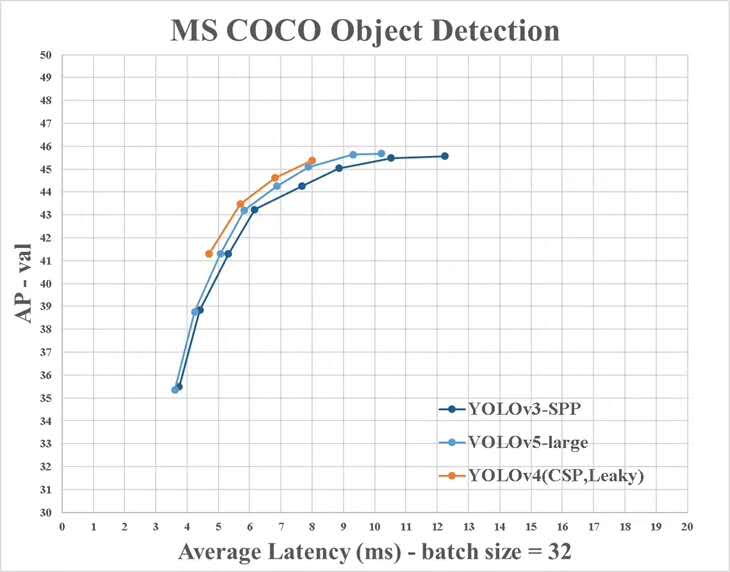
No entanto, existem algumas diferenças entre as informações fornecidas pelo YOLO V4 e as oficiais:
Instale o pacote Python necessário e configure ambientes relacionados
# python3.6
# torch==1.3.0
# torchvision==0.4.1
# git clone yolo v5 repo
git clone https://github.com/ultralytics/yolov5 # clone repo
# 下载官方的样例数据(这一步可以省略)
python3 -c "from yolov5.utils.google_utils import gdrive_download; gdrive_download('1n_oKgR81BJtqk75b00eAjdv03qVCQn2f','coco128.zip')" # download dataset
cd yolov5
# 安装必要的package
pip3 install -U -r requirements.txt
dataset.yaml do arquivo de configuração.yaml do conjunto de dados dados/coco128.yaml vem das primeiras 128 imagens de treinamento do conjunto de dados Coco Train2017. Você pode modificar o arquivo yaml do seu próprio conjunto de dados com base neste yaml
# train and val datasets (image directory or *.txt file with image paths)
train: ./datasets/score/images/train/
val: ./datasets/score/images/val/
# number of classes
nc: 3
# class names
names: ['QP', 'NY', 'QG']
Você pode usar o LABELIMG, LABME, LABELBOX e CVAT para rotular dados. Para detecção de destino, você precisa rotular a caixa delimitadora. Em seguida, você precisa converter a anotação para o mesmo formato de anotação do formato Darknet , e cada imagem gera um arquivo de anotação *.txt (se a imagem não tiver um destino de anotação, não precisará criar um arquivo *.txt ). O arquivo *.txt criado segue as seguintes regras:
class x_center y_center width height def convert ( size , box ):
'''
将标注的xml文件标注转换为darknet形的坐标
'''
dw = 1. / ( size [ 0 ])
dh = 1. / ( size [ 1 ])
x = ( box [ 0 ] + box [ 1 ]) / 2.0 - 1
y = ( box [ 2 ] + box [ 3 ]) / 2.0 - 1
w = box [ 1 ] - box [ 0 ]
h = box [ 3 ] - box [ 2 ]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return ( x , y , w , h ) Cada arquivo de anotação *.txt é armazenado em um diretório de arquivos semelhante à imagem. Você só precisa substituir /images/*.jpg com /lables/*.txt (este código de processamento interno é assim ao carregar dados. Você pode modificá -lo no formato de dados VOC para carregar)
Por exemplo:
datasets/score/images/train/000000109622.jpg # image
datasets/score/labels/train/000000109622.txt # label
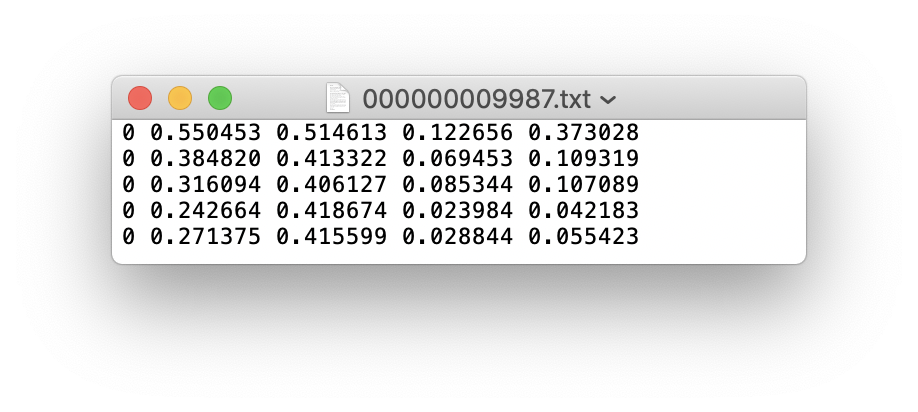
Se um arquivo de etiqueta contiver categorias de 5 pessoas (a pessoa é a primeira categoria no conjunto de dados Coco, então o índice é 0):
Armazene as pastas de imagens e etiquetas do conjunto de trem e verificação do conjunto de treinamento Val, como seguinte

Neste ponto, a fase de preparação de dados foi concluída. Durante o processo, assumimos que o processo de divisão de limpeza e conjunto de dados do engenheiro de algoritmo foi concluído por si só.
Selecione um modelo que precisa ser treinado na pasta do projeto ./models . Aqui, selecionamos Yolov5x.yaml, o maior modelo para treinamento. Consulte a tabela no Readme oficial para entender o tamanho e a velocidade de inferência de diferentes modelos. Se você selecionou um modelo, precisa modificar o arquivo yaml correspondente ao modelo
# parameters
nc : 3 # number of classes <------------------ UPDATE to match your dataset
depth_multiple : 1.33 # model depth multiple
width_multiple : 1.25 # layer channel multiple
# anchors
anchors :
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov5 backbone
backbone :
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 1-P1/2
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]], # 10
]
# yolov5 head
head :
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# Train yolov5x on score for 300 epochs
$ python3 train.py --img-size 640 --batch-size 16 --epochs 300 --data ./data/score.yaml --cfg ./models/score/yolov5x.yaml --weights weights/yolov5x.pt
Após o início do treinamento, verifique train*.jpg Imagem para visualizar dados de treinamento, etiquetas e aprimoramentos de dados. Se a sua imagem exibir rótulos ou aprimoramentos de dados estiverem incorretos, verifique se há algum problema com o processo de construção do seu conjunto de dados.
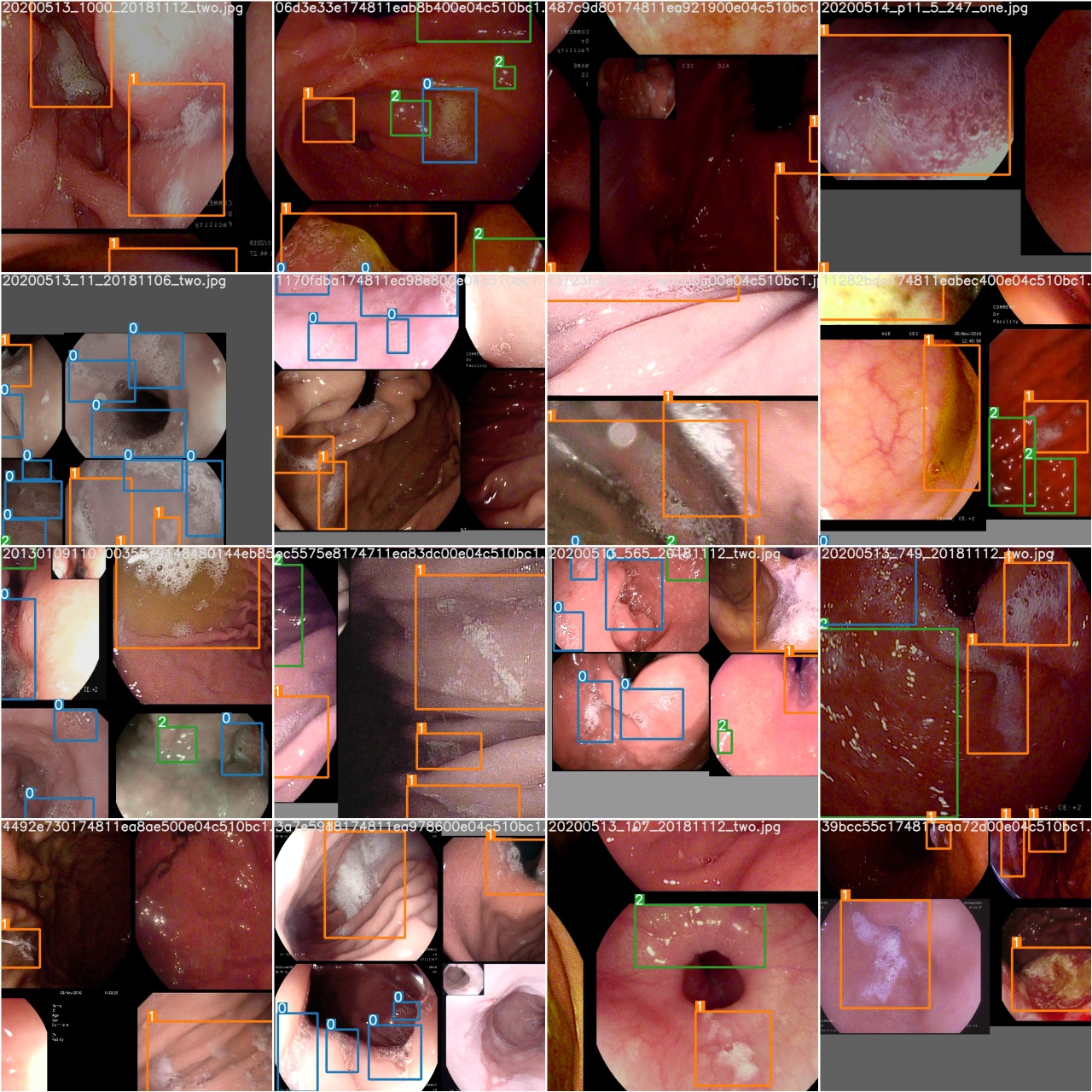
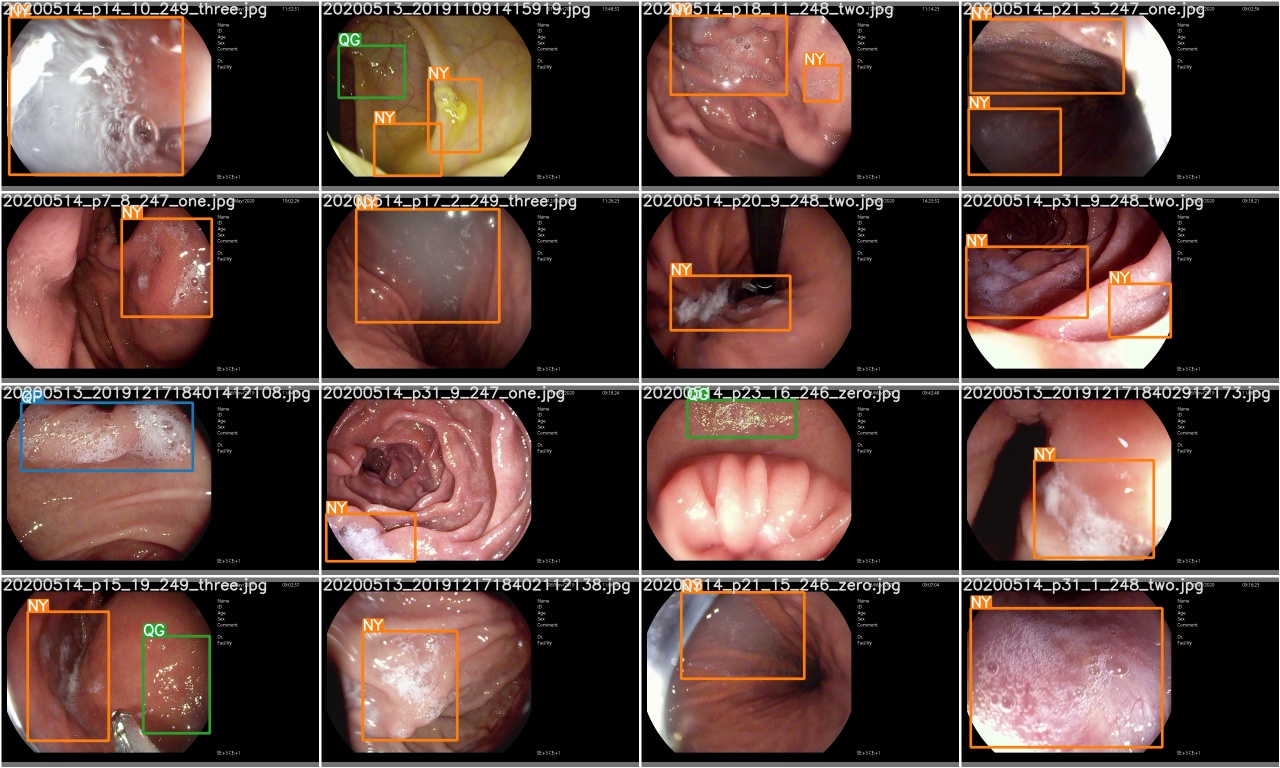
Após a conclusão de uma época de treinamento, verifique test_batch0_gt.jpg para ver os rótulos do lote 0 Verdade do solo
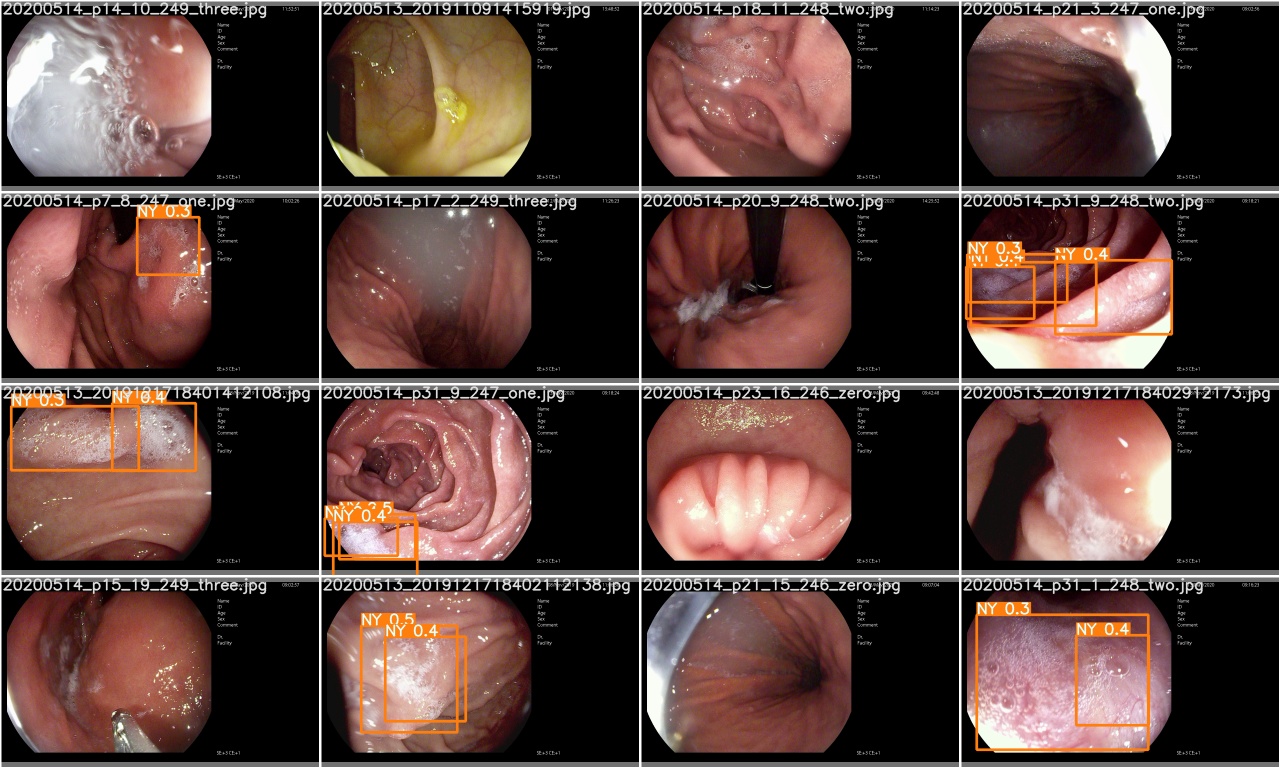
Verifique test_batch0_pred.jpg para ver a previsão do lote de teste 0
As perdas de treinamento e as métricas de avaliação são salvas no Tensorboard e results.txt Log Arquivos. results.txt será visualizado como results.png após o término do treinamento
> >> from utils . utils import plot_results
> >> plot_results ()
# 如果你是用远程连接请安装配置Xming: https://blog.csdn.net/akuoma/article/details/82182913 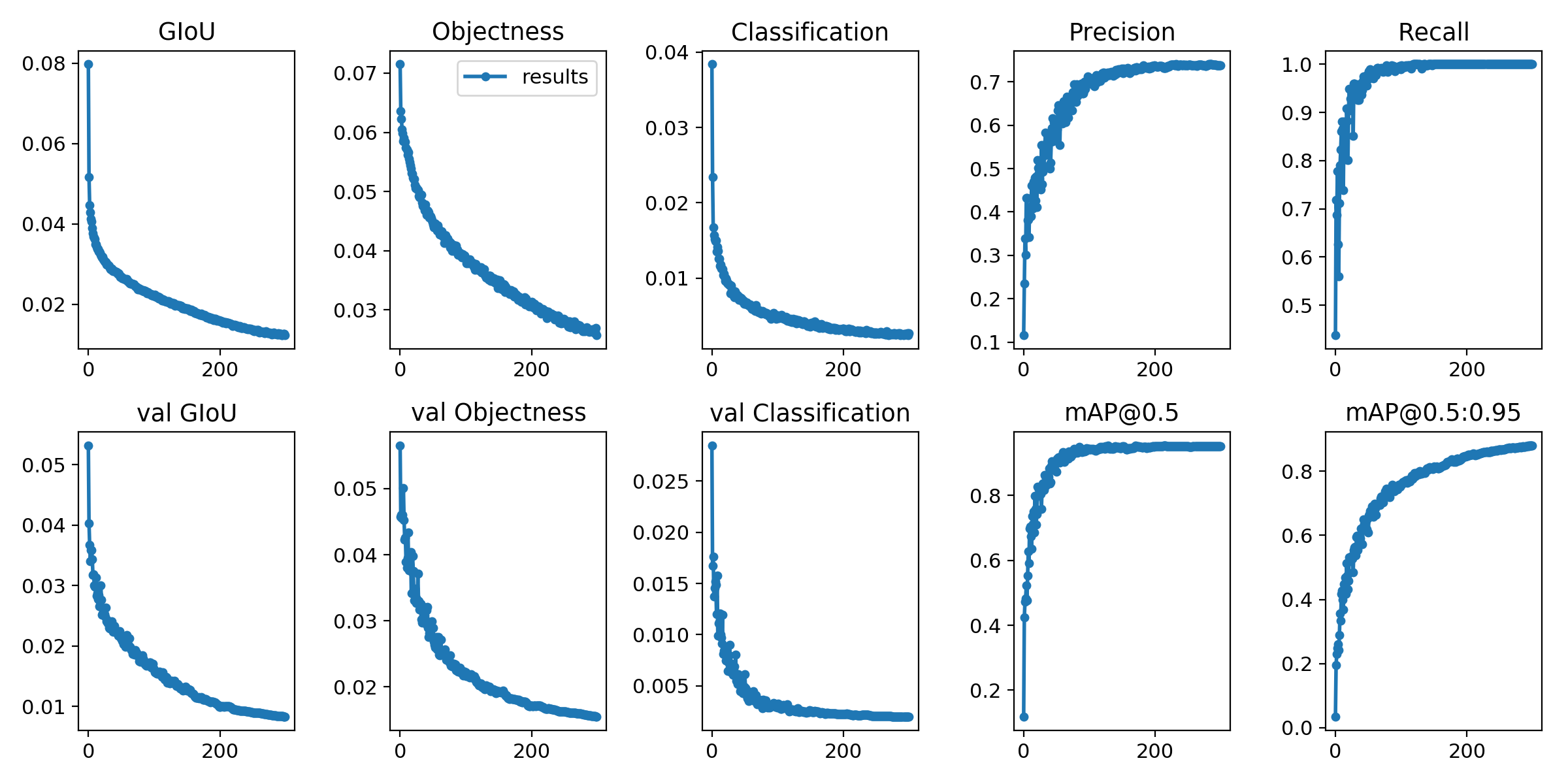
$ python3 detect . py - - source file . jpg # image
file . mp4 # video
. / dir # directory
0 # webcam
rtsp : // 170.93 . 143.139 / rtplive / 470011e600 ef003a004ee33696235daa # rtsp stream
http : // 112.50 . 243.8 / PLTV / 88888888 / 224 / 3221225900 / 1. m3u8 # http stream # inference /home/myuser/xujing/EfficientDet-Pytorch/dataset/test/ 文件夹下的图像
$ python3 detect . py - - source / home / myuser / xujing / EfficientDet - Pytorch / dataset / test / - - weights weights / best . pt - - conf 0.1
$ python3 detect . py - - source . / inference / images / - - weights weights / yolov5x . pt - - conf 0.5
# inference 视频
$ python3 detect . py - - source test . mp4 - - weights weights / yolov5x . pt - - conf 0.4 
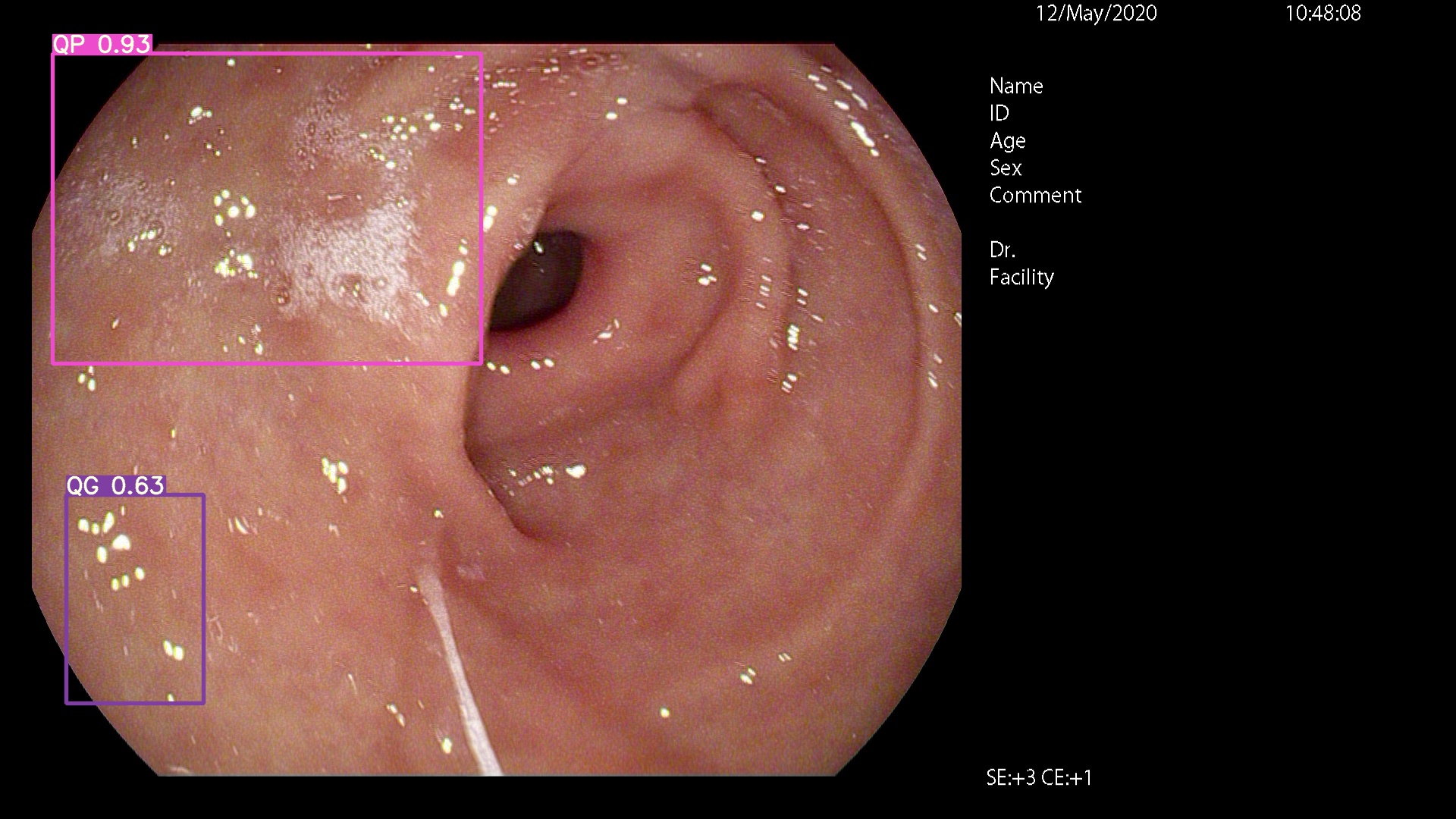
Por favor, venha aqui
Referência
[1] .https: //github.com/ultralytics/yolov5
[2] .https: //github.com/ultralytics/yolov5/wiki/train-custom-data


