YOLO v5
1.0.0
? ? Ahora Yolov5 se ha actualizado a la versión 6.0, pero su método de entrenamiento es el mismo que este repositorio. Solo necesita instalar el entorno Python correspondiente de acuerdo con la versión correspondiente. ¡La construcción de su conjunto de datos, modificación del archivo de configuración, método de capacitación, etc. es completamente consistente con este repositorio!
? ? Proporcionamos llamadas Tensorrt Yolov5 y el código de Python cuantificado y el código de Python (el método de aceleración Tensorrt es diferente de las llamadas Tensorrt proporcionadas por este repositorio). ¡Los grandes necesitados pueden dejar un mensaje en los problemas!
Xu Jing
Debido al ajuste de la columna vertebral y algunos parámetros de la nueva versión oficial de Yolo V5, muchos amigos han descargado el último modelo oficial previamente entrenado y no están disponibles. Aquí proporcionamos la dirección de descarga del disco de la nube de Baidu del modelo pre-entrenado original YOLO V5.
Enlace: https://pan.baidu.com/s/1sdwp6i_mnrlk45qdb3-ynw Código de extracción: 423J
Yolov4 aún no ha disminuido, ¡Yolov5 ha sido lanzado!
El 9 de junio, Ultralytics abrió la fuente de Yolov5, menos de 50 días después de que se lanzó el último Yolov4. ¡Y esta vez, YOLOV5 se implementa completamente en base a Pytorch!
El principal contribuyente a Yolo V5 es el autor de la mejora de datos de mosaico resaltado en YOLO V4

Este proyecto describe cómo entrenar Yolo V5 en función de su propio conjunto de datos
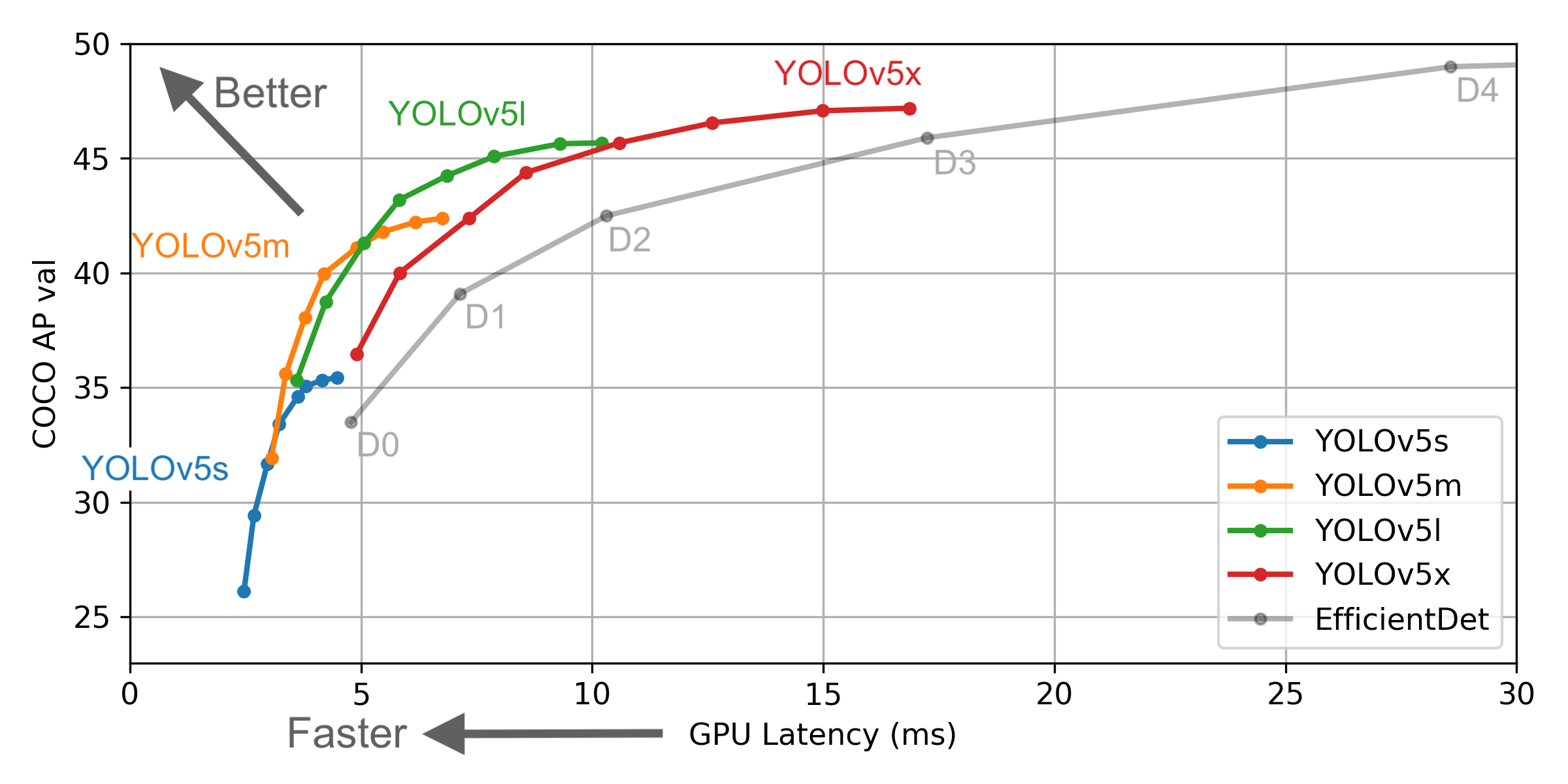
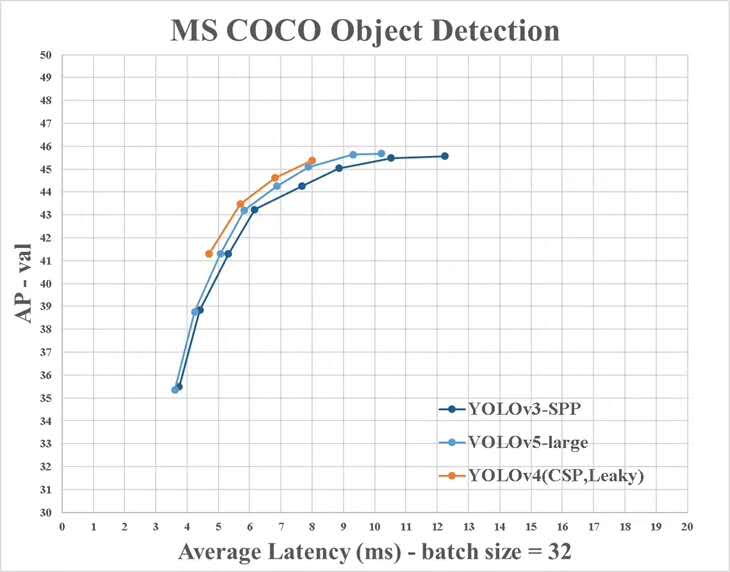
Sin embargo, existen algunas diferencias entre la información proporcionada por YOLO V4 y las oficiales:
Instale el paquete Python necesario y configure entornos relacionados
# python3.6
# torch==1.3.0
# torchvision==0.4.1
# git clone yolo v5 repo
git clone https://github.com/ultralytics/yolov5 # clone repo
# 下载官方的样例数据(这一步可以省略)
python3 -c "from yolov5.utils.google_utils import gdrive_download; gdrive_download('1n_oKgR81BJtqk75b00eAjdv03qVCQn2f','coco128.zip')" # download dataset
cd yolov5
# 安装必要的package
pip3 install -U -r requirements.txt
dataset.yaml del archivo de configuración.yaml del conjunto de datos Data/COCO128.yaml proviene de las primeras 128 imágenes de entrenamiento del conjunto de datos Coco Train2017. Puede modificar el archivo yaml de su propio conjunto de datos en función de este yaml
# train and val datasets (image directory or *.txt file with image paths)
train: ./datasets/score/images/train/
val: ./datasets/score/images/val/
# number of classes
nc: 3
# class names
names: ['QP', 'NY', 'QG']
Puede usar LabelImg, LabMe, Labelbox y CVAT para etiquetar los datos. Para la detección de objetivos, debe etiquetar el cuadro delimitador. Luego, debe convertir la anotación en el mismo formato de anotación que el formato DarkNet , y cada imagen genera un archivo de anotación *.txt (si la imagen no tiene un objetivo de anotación, no necesita crear un archivo *.txt ). El archivo *.txt creado sigue las siguientes reglas:
class x_center y_center width height def convert ( size , box ):
'''
将标注的xml文件标注转换为darknet形的坐标
'''
dw = 1. / ( size [ 0 ])
dh = 1. / ( size [ 1 ])
x = ( box [ 0 ] + box [ 1 ]) / 2.0 - 1
y = ( box [ 2 ] + box [ 3 ]) / 2.0 - 1
w = box [ 1 ] - box [ 0 ]
h = box [ 3 ] - box [ 2 ]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return ( x , y , w , h ) Cada archivo de anotación *.txt se almacena en un directorio de archivos similar a la imagen. Solo necesita reemplazar /images/*.jpg con /lables/*.txt (este procesamiento interno de código es así al cargar datos. Puede modificarlo al formato de datos VOC para la carga)
Por ejemplo:
datasets/score/images/train/000000109622.jpg # image
datasets/score/labels/train/000000109622.txt # label
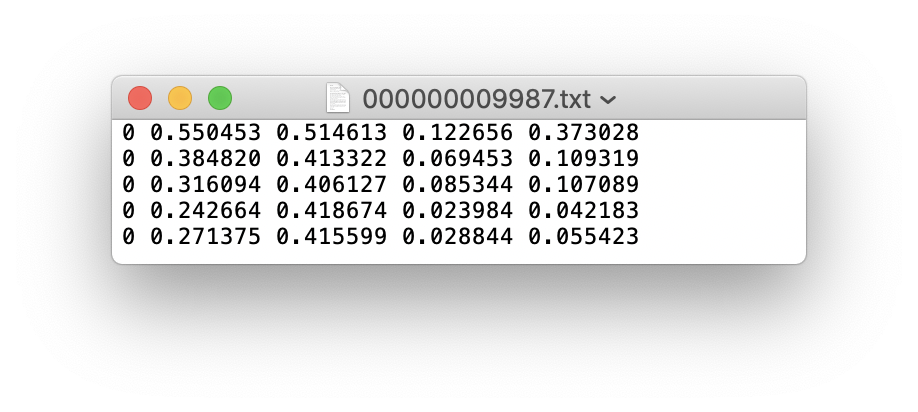
Si un archivo de etiqueta contiene categorías de 5 personas (la persona es la primera categoría en el conjunto de datos de Coco, por lo que el índice es 0):
Almacene las carpetas de imágenes y etiquetas del set de entrenamiento y el conjunto de verificación de verificación de la siguiente manera

En este punto, se ha completado la fase de preparación de datos. Durante el proceso, suponemos que el proceso de división de datos y de limpieza de datos del ingeniero de algoritmo y la división del conjunto de datos se han completado por sí mismo.
Seleccione un modelo que debe ser capacitado en la carpeta del proyecto ./models . Aquí seleccionamos yolov5x.yaml, el modelo más grande para el entrenamiento. Consulte la tabla en el ReadMe oficial para comprender el tamaño y la velocidad de inferencia de diferentes modelos. Si ha seleccionado un modelo, debe modificar el archivo yaml correspondiente al modelo
# parameters
nc : 3 # number of classes <------------------ UPDATE to match your dataset
depth_multiple : 1.33 # model depth multiple
width_multiple : 1.25 # layer channel multiple
# anchors
anchors :
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov5 backbone
backbone :
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 1-P1/2
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]], # 10
]
# yolov5 head
head :
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# Train yolov5x on score for 300 epochs
$ python3 train.py --img-size 640 --batch-size 16 --epochs 300 --data ./data/score.yaml --cfg ./models/score/yolov5x.yaml --weights weights/yolov5x.pt
Después de comenzar la capacitación, verifique la imagen train*.jpg para ver datos de capacitación, etiquetas y mejoras de datos. Si su imagen muestra etiquetas o mejoras de datos son incorrectas, debe verificar si hay algún problema con el proceso de construcción de su conjunto de datos.
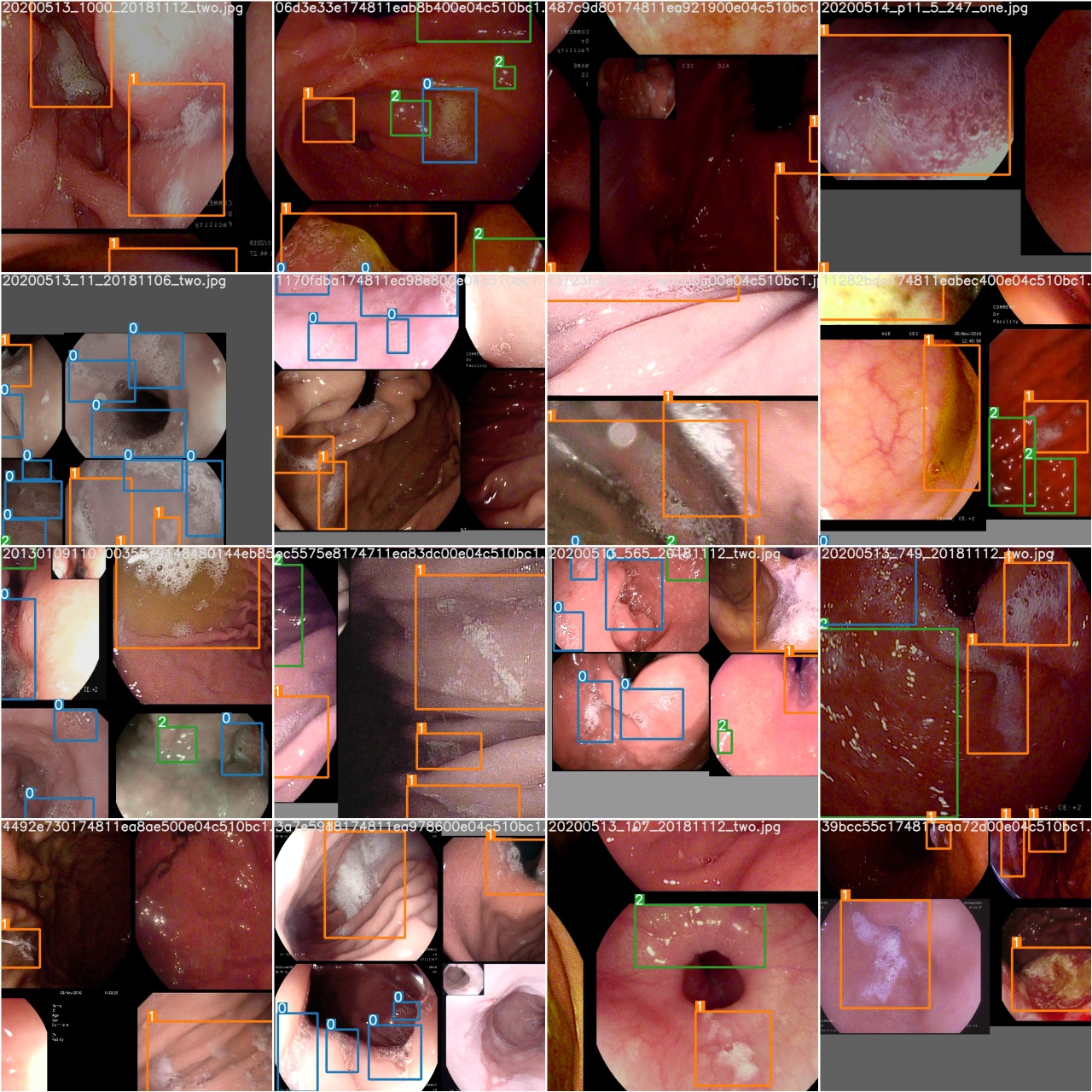
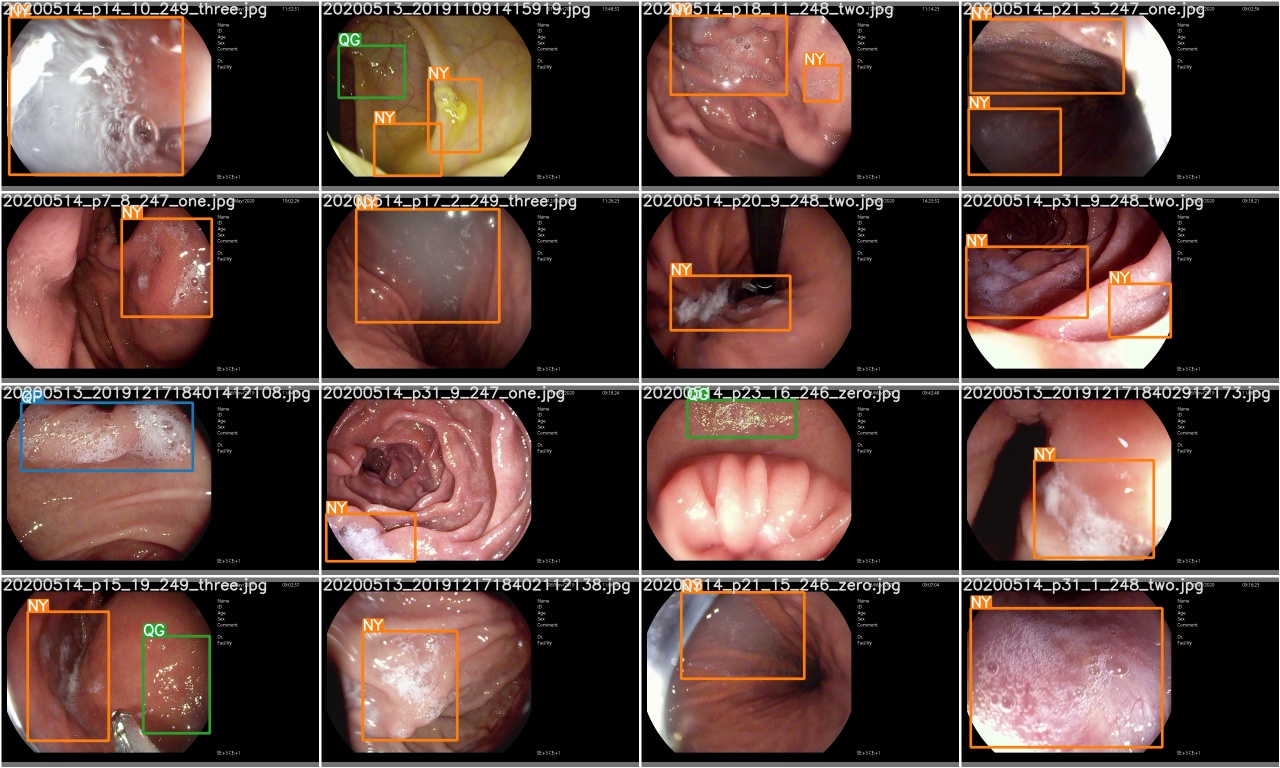
Después de completar una época de entrenamiento, verifique test_batch0_gt.jpg para ver las etiquetas de la verdad del lote 0
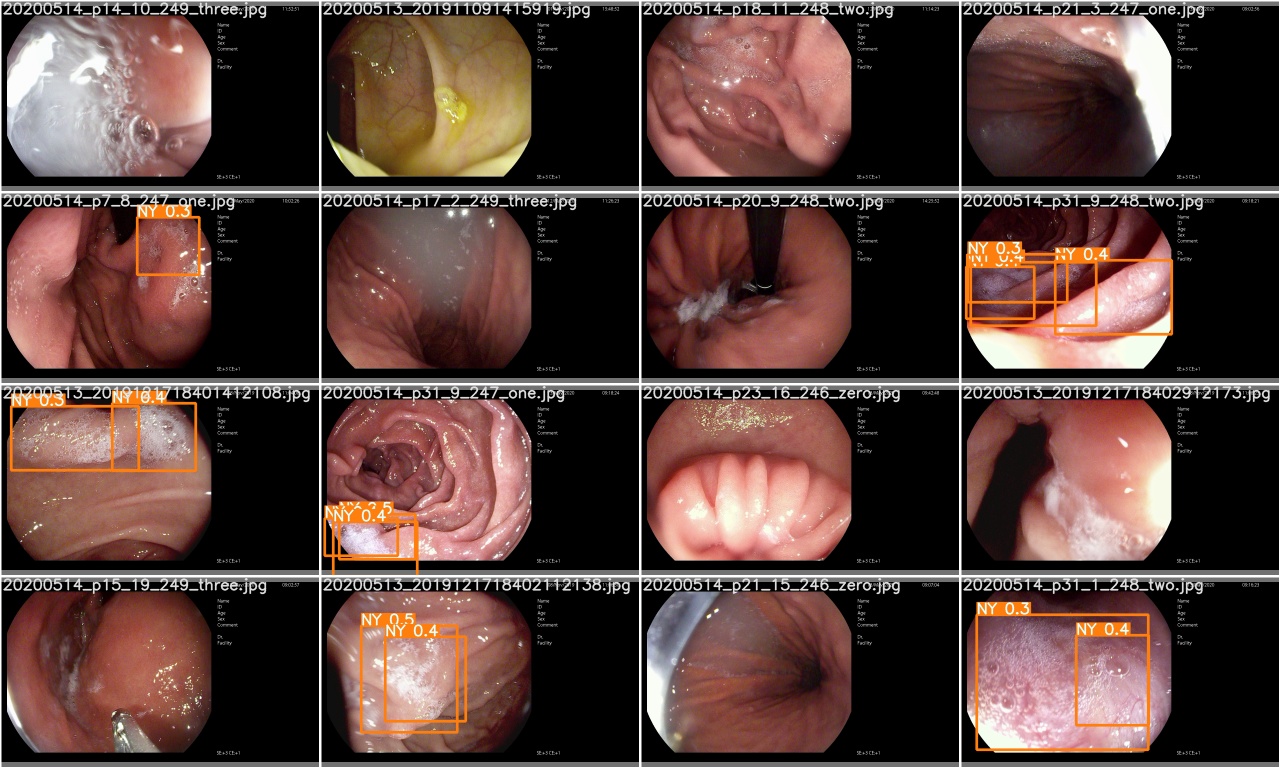
Verifique test_batch0_pred.jpg para ver la predicción del lote de prueba 0
Las pérdidas de capacitación y las métricas de evaluación se guardan en los archivos de registro de tensorboard y results.txt . results.txt se visualizará como results.png después de que termine el entrenamiento
> >> from utils . utils import plot_results
> >> plot_results ()
# 如果你是用远程连接请安装配置Xming: https://blog.csdn.net/akuoma/article/details/82182913 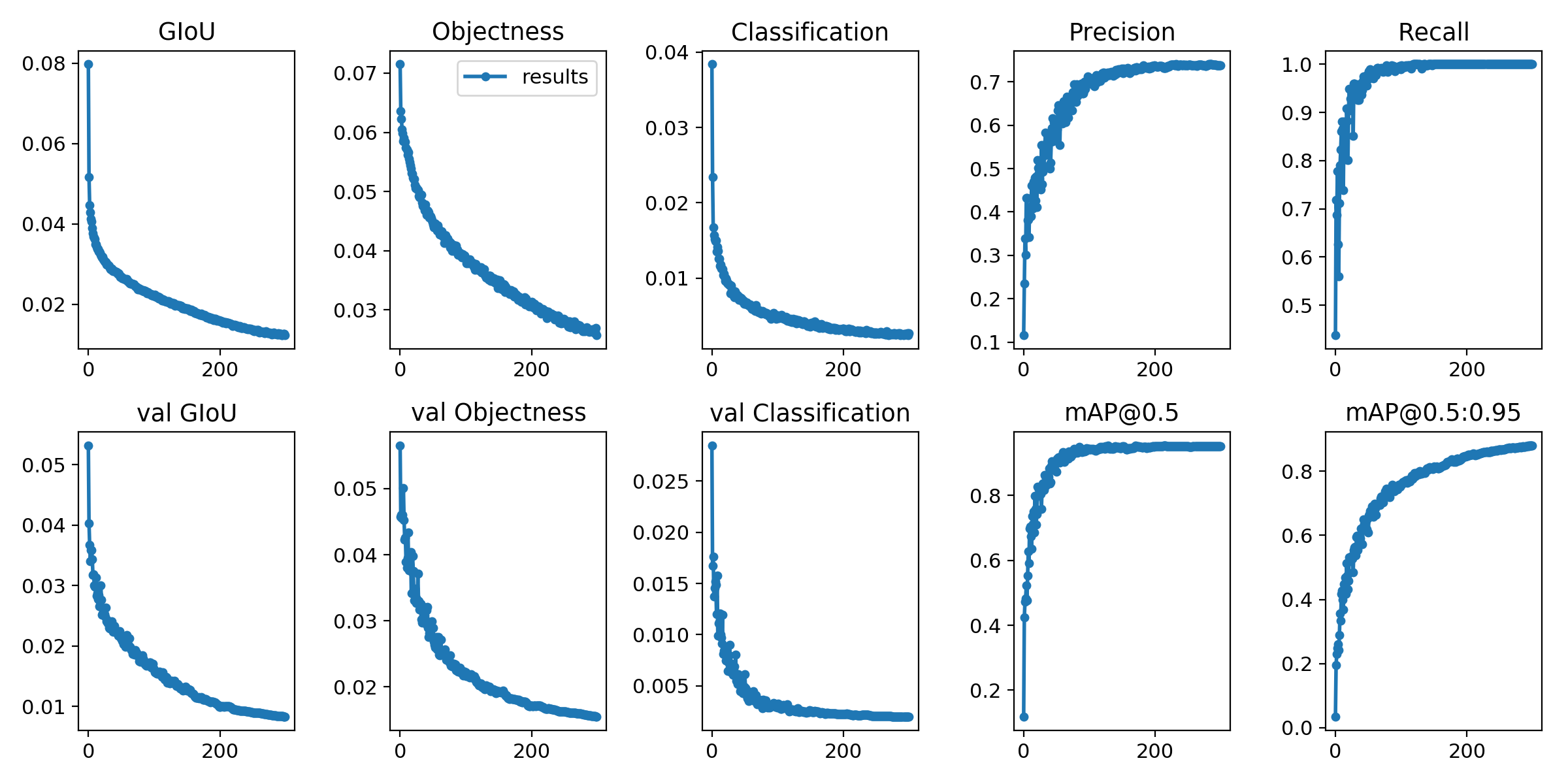
$ python3 detect . py - - source file . jpg # image
file . mp4 # video
. / dir # directory
0 # webcam
rtsp : // 170.93 . 143.139 / rtplive / 470011e600 ef003a004ee33696235daa # rtsp stream
http : // 112.50 . 243.8 / PLTV / 88888888 / 224 / 3221225900 / 1. m3u8 # http stream # inference /home/myuser/xujing/EfficientDet-Pytorch/dataset/test/ 文件夹下的图像
$ python3 detect . py - - source / home / myuser / xujing / EfficientDet - Pytorch / dataset / test / - - weights weights / best . pt - - conf 0.1
$ python3 detect . py - - source . / inference / images / - - weights weights / yolov5x . pt - - conf 0.5
# inference 视频
$ python3 detect . py - - source test . mp4 - - weights weights / yolov5x . pt - - conf 0.4 
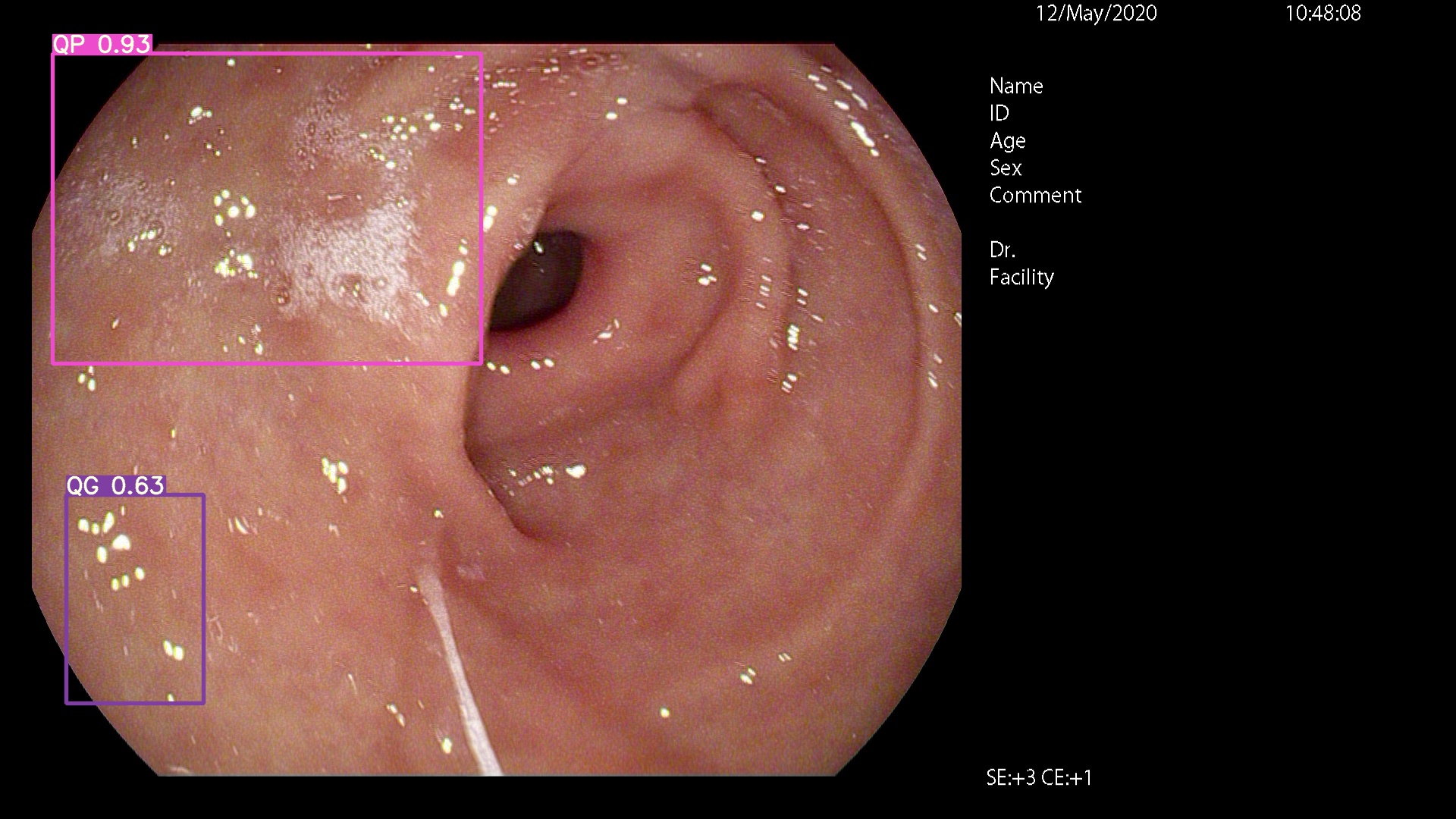
Por favor ven aquí
Referencia
[1] .https: //github.com/ultralytics/yolov5
[2] .https: //github.com/ultralytics/yolov5/wiki/train-custom-data


