YOLO v5
1.0.0
? ? 이제 YOLOV5는 버전 6.0으로 업데이트되었지만 교육 방법은이 repo와 동일합니다. 해당 버전에 따라 해당 파이썬 환경 만 설치하면됩니다. 데이터 세트, 구성 파일 수정, 교육 방법 등의 구성은이 리포지어와 완전히 일치합니다!
? ? 우리는 YOLOV5 TENSORRT 호출과 int8 양자화 된 C ++ 및 Python 코드를 제공합니다 (Tensorrt 가속 메소드는이 repo에서 제공 한 Tensorrt 호출과 다릅니다). 도움이 필요한 큰 사람들은 문제에 메시지를 남길 수 있습니다!
Xu Jing
백본의 조정과 공식 새 버전의 Yolo V5의 매개 변수로 인해 많은 친구들이 최신 공식 공식 훈련 된 모델을 다운로드했으며 사용할 수 없습니다. 여기서 우리는 원래 Yolo V5 사전 훈련 된 모델의 Baidu Cloud 디스크 다운로드 주소를 제공합니다.
링크 : https://pan.baidu.com/s/1sdwp6i_mnrlk45qdb3-ynw 추출 코드 : 423J
Yolov4는 아직 가라 앉지 않았으며 Yolov5가 출시되었습니다!
6 월 9 일, Ultralytics는 마지막 Yolov4가 풀린 후 50 일 이내에 Yolov5의 공급원을 열었습니다. 그리고 이번에는 Yolov5가 Pytorch를 기반으로 완전히 구현됩니다!
Yolo V5의 주요 기여자는 Yolo V4에서 강조된 모자이크 데이터 강화의 저자입니다.

이 프로젝트는 자신의 데이터 세트를 기반으로 Yolo V5를 훈련시키는 방법에 대해 설명합니다.
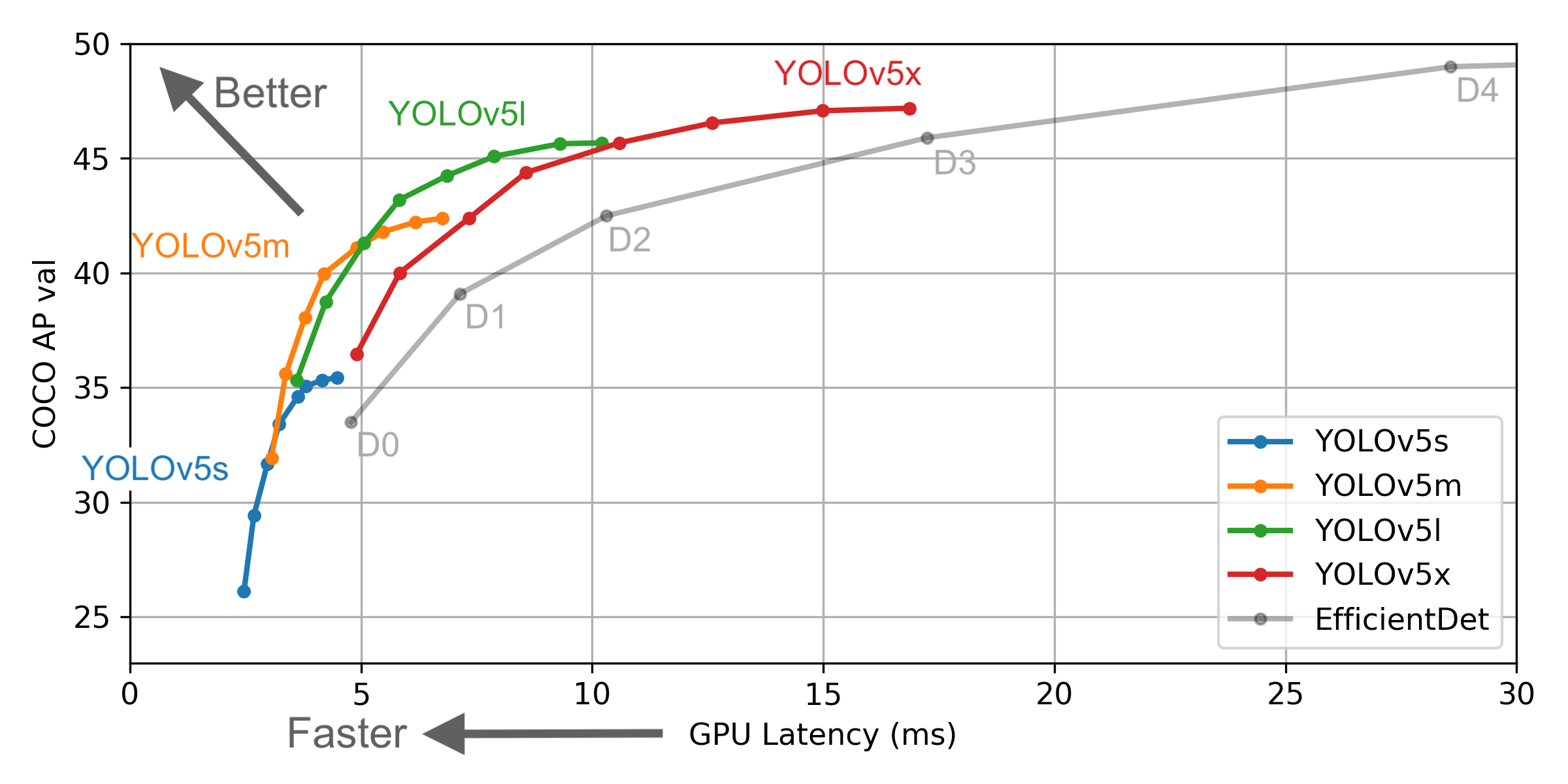
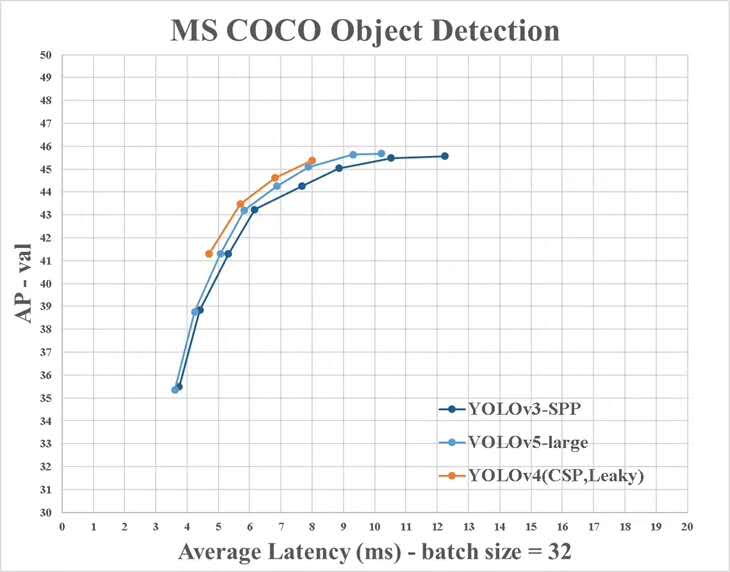
그러나 Yolo V4가 제공 한 정보와 공식 정보에는 몇 가지 차이가 있습니다.
필요한 파이썬 패키지를 설치하고 관련 환경을 구성하십시오
# python3.6
# torch==1.3.0
# torchvision==0.4.1
# git clone yolo v5 repo
git clone https://github.com/ultralytics/yolov5 # clone repo
# 下载官方的样例数据(这一步可以省略)
python3 -c "from yolov5.utils.google_utils import gdrive_download; gdrive_download('1n_oKgR81BJtqk75b00eAjdv03qVCQn2f','coco128.zip')" # download dataset
cd yolov5
# 安装必要的package
pip3 install -U -r requirements.txt
dataset.yaml 만듭니다 Data/Coco128.yaml은 Coco Train2017 데이터 세트의 첫 128 개의 교육 이미지에서 제공됩니다. 이 YAML을 기반으로 자신의 데이터 세트의 yaml 파일을 수정할 수 있습니다 yaml
# train and val datasets (image directory or *.txt file with image paths)
train: ./datasets/score/images/train/
val: ./datasets/score/images/val/
# number of classes
nc: 3
# class names
names: ['QP', 'NY', 'QG']
labelimg, labme, labelbox 및 cvat을 사용하여 데이터를 레이블로 표시 할 수 있습니다. 대상 감지의 경우 경계 상자에 레이블을 지정해야합니다. 그런 다음 주석을 DarkNet 형식 과 동일한 주석 양식으로 변환해야하며 각 이미지는 *.txt 주석 파일을 생성합니다 (이미지에 주석 대상이없는 경우 *.txt 파일을 만들 필요가 없습니다). 생성 된 *.txt 파일은 다음 규칙을 따릅니다.
class x_center y_center width height 포함됩니다. def convert ( size , box ):
'''
将标注的xml文件标注转换为darknet形的坐标
'''
dw = 1. / ( size [ 0 ])
dh = 1. / ( size [ 1 ])
x = ( box [ 0 ] + box [ 1 ]) / 2.0 - 1
y = ( box [ 2 ] + box [ 3 ]) / 2.0 - 1
w = box [ 1 ] - box [ 0 ]
h = box [ 3 ] - box [ 2 ]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return ( x , y , w , h ) 각 주석 *.txt 파일은 이미지와 유사한 파일 디렉토리에 저장됩니다. /images/*.jpg /lables/*.txt 로만 교체하면됩니다 (이 코드 내부 처리는 데이터를로드 할 때 이와 같습니다.로드를 위해 VOC 데이터 형식으로 수정할 수 있습니다).
예를 들어:
datasets/score/images/train/000000109622.jpg # image
datasets/score/labels/train/000000109622.txt # label
레이블 파일에 5 인원 범주가 포함 된 경우 (사람이 Coco 데이터 세트의 첫 번째 범주이므로 인덱스는 0) :
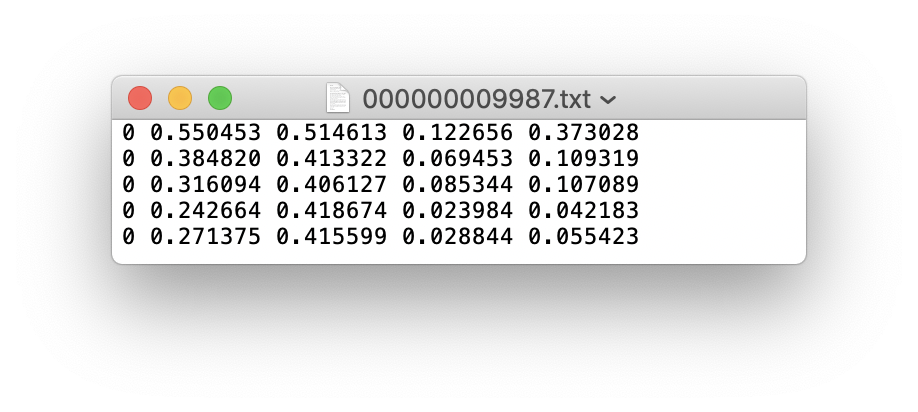
교육 세트 열차 및 검증 세트 val의 이미지 및 레이블 폴더를 다음과 같이 저장하십시오.

이 시점에서 데이터 준비 단계가 완료되었습니다. 이 과정에서 우리는 알고리즘 엔지니어의 데이터 정리 및 데이터 세트 디비전 프로세스가 자체적으로 완료되었다고 가정합니다.
프로젝트에서 훈련 해야하는 모델을 선택하십시오 ./models 폴더. 여기서 우리는 훈련을위한 가장 큰 모델 인 Yolov5x.yaml을 선택합니다. 다른 모델의 크기와 추론 속도를 이해하려면 공식 readme의 표를 참조하십시오. 모델을 선택한 경우 모델에 해당하는 yaml 파일을 수정해야합니다.
# parameters
nc : 3 # number of classes <------------------ UPDATE to match your dataset
depth_multiple : 1.33 # model depth multiple
width_multiple : 1.25 # layer channel multiple
# anchors
anchors :
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov5 backbone
backbone :
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 1-P1/2
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]], # 10
]
# yolov5 head
head :
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# Train yolov5x on score for 300 epochs
$ python3 train.py --img-size 640 --batch-size 16 --epochs 300 --data ./data/score.yaml --cfg ./models/score/yolov5x.yaml --weights weights/yolov5x.pt
교육을 시작한 후 train*.jpg 이미지를 확인하여 교육 데이터, 레이블 및 데이터 향상을 볼 수 있습니다. 이미지에 레이블이 표시되거나 데이터 향상이 잘못된 경우 데이터 세트의 구성 프로세스에 문제가 있는지 확인해야합니다.
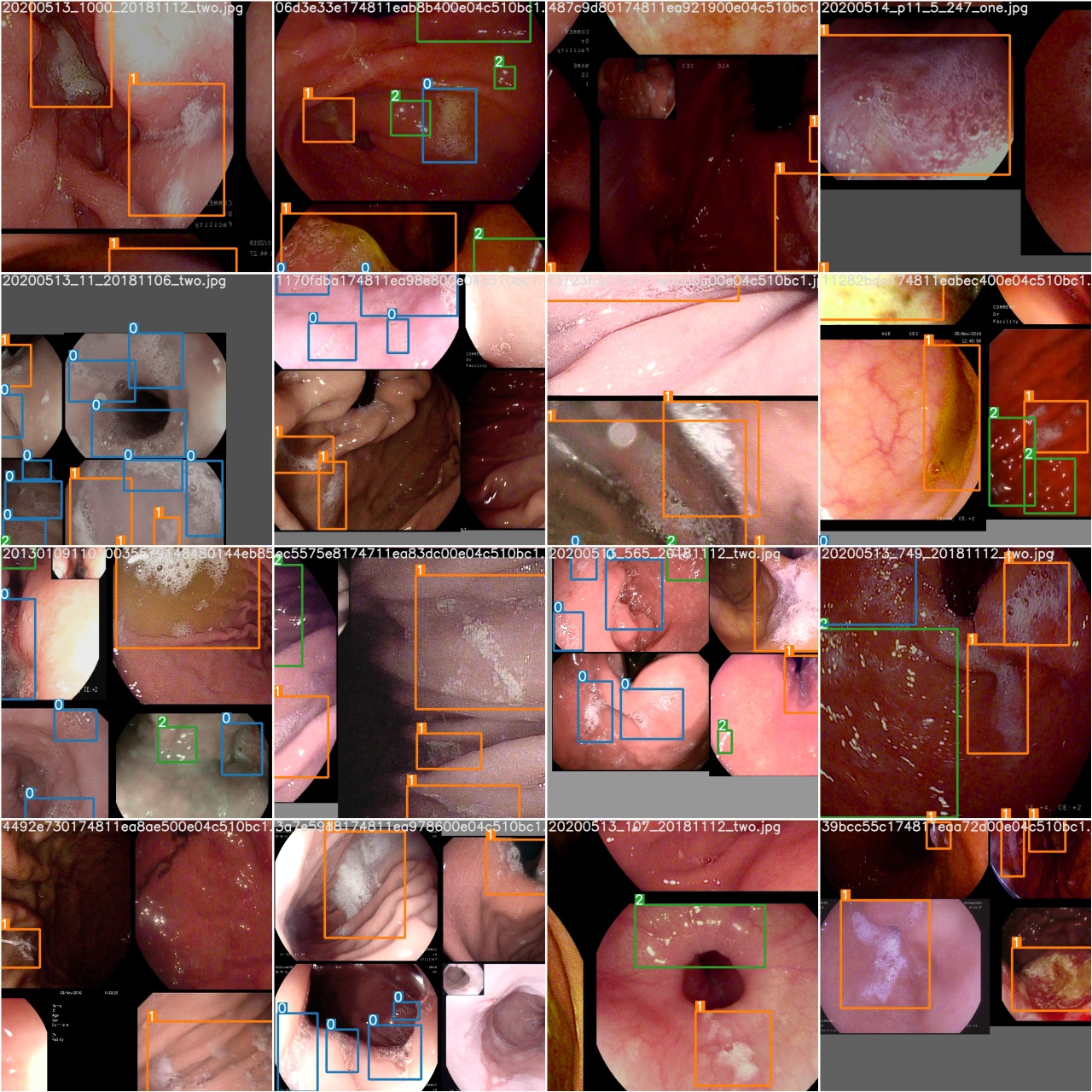
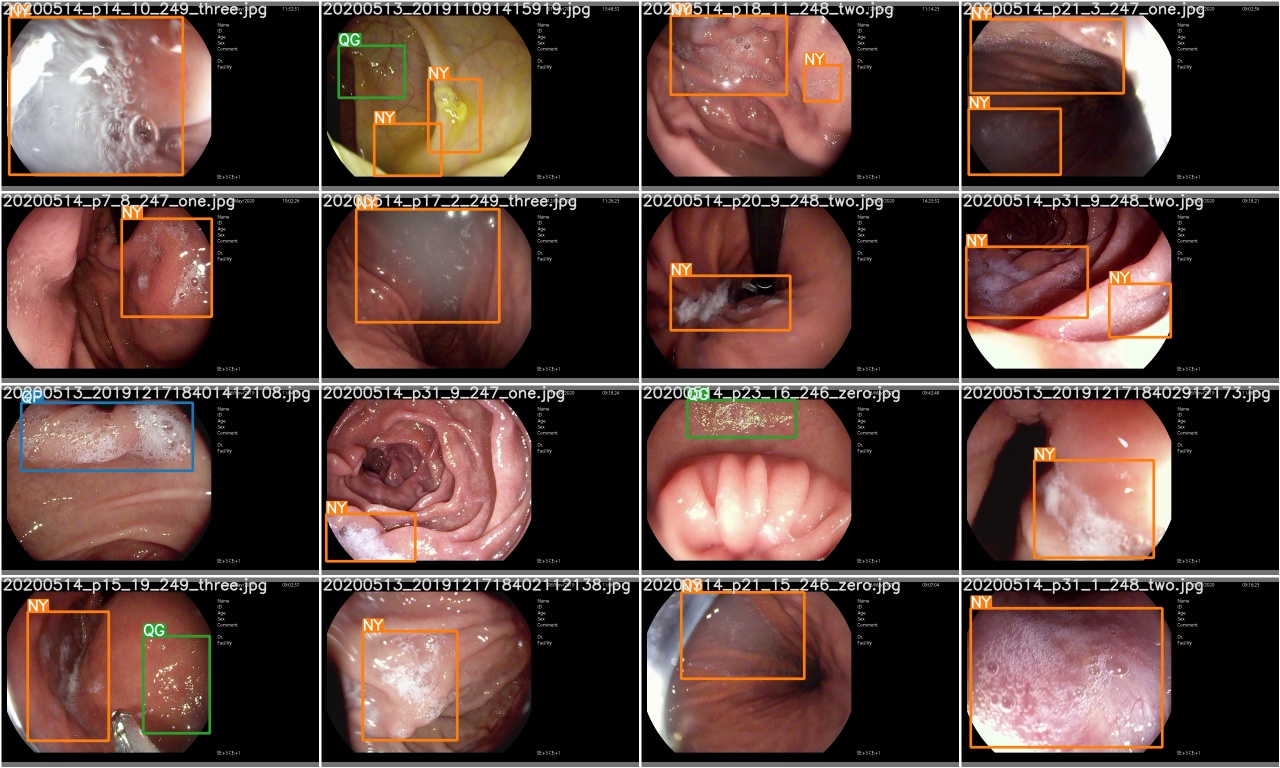
훈련 에포크가 완료된 후, test_batch0_gt.jpg 확인하여 배치 0 그라운드 진실의 레이블을 확인하십시오.
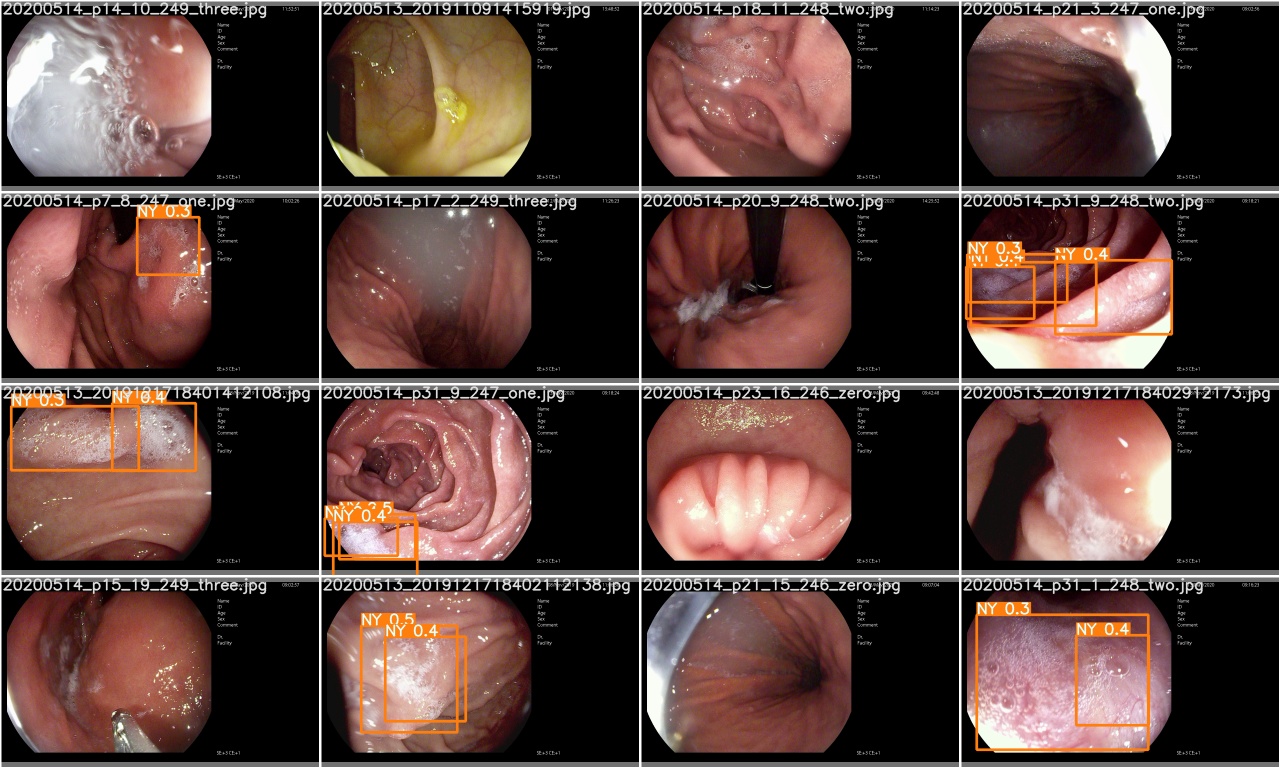
test_batch0_pred.jpg 확인하여 테스트 배치 예측을 확인하십시오.
교육 손실 및 평가 지표는 Tensorboard 및 results.txt Log 파일에 저장됩니다. results.txt 는 results.png 후에 시각화됩니다.
> >> from utils . utils import plot_results
> >> plot_results ()
# 如果你是用远程连接请安装配置Xming: https://blog.csdn.net/akuoma/article/details/82182913 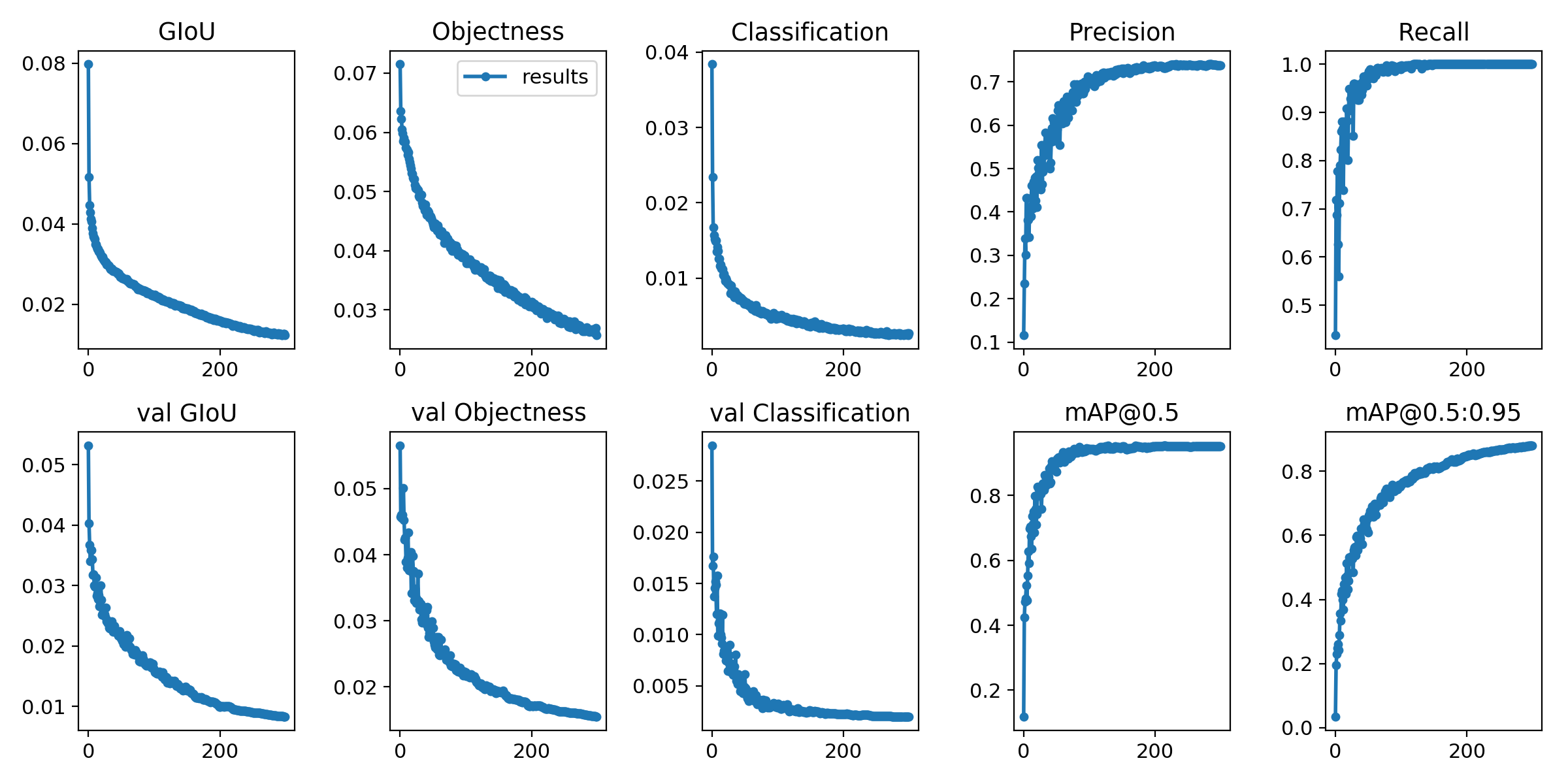
$ python3 detect . py - - source file . jpg # image
file . mp4 # video
. / dir # directory
0 # webcam
rtsp : // 170.93 . 143.139 / rtplive / 470011e600 ef003a004ee33696235daa # rtsp stream
http : // 112.50 . 243.8 / PLTV / 88888888 / 224 / 3221225900 / 1. m3u8 # http stream # inference /home/myuser/xujing/EfficientDet-Pytorch/dataset/test/ 文件夹下的图像
$ python3 detect . py - - source / home / myuser / xujing / EfficientDet - Pytorch / dataset / test / - - weights weights / best . pt - - conf 0.1
$ python3 detect . py - - source . / inference / images / - - weights weights / yolov5x . pt - - conf 0.5
# inference 视频
$ python3 detect . py - - source test . mp4 - - weights weights / yolov5x . pt - - conf 0.4 
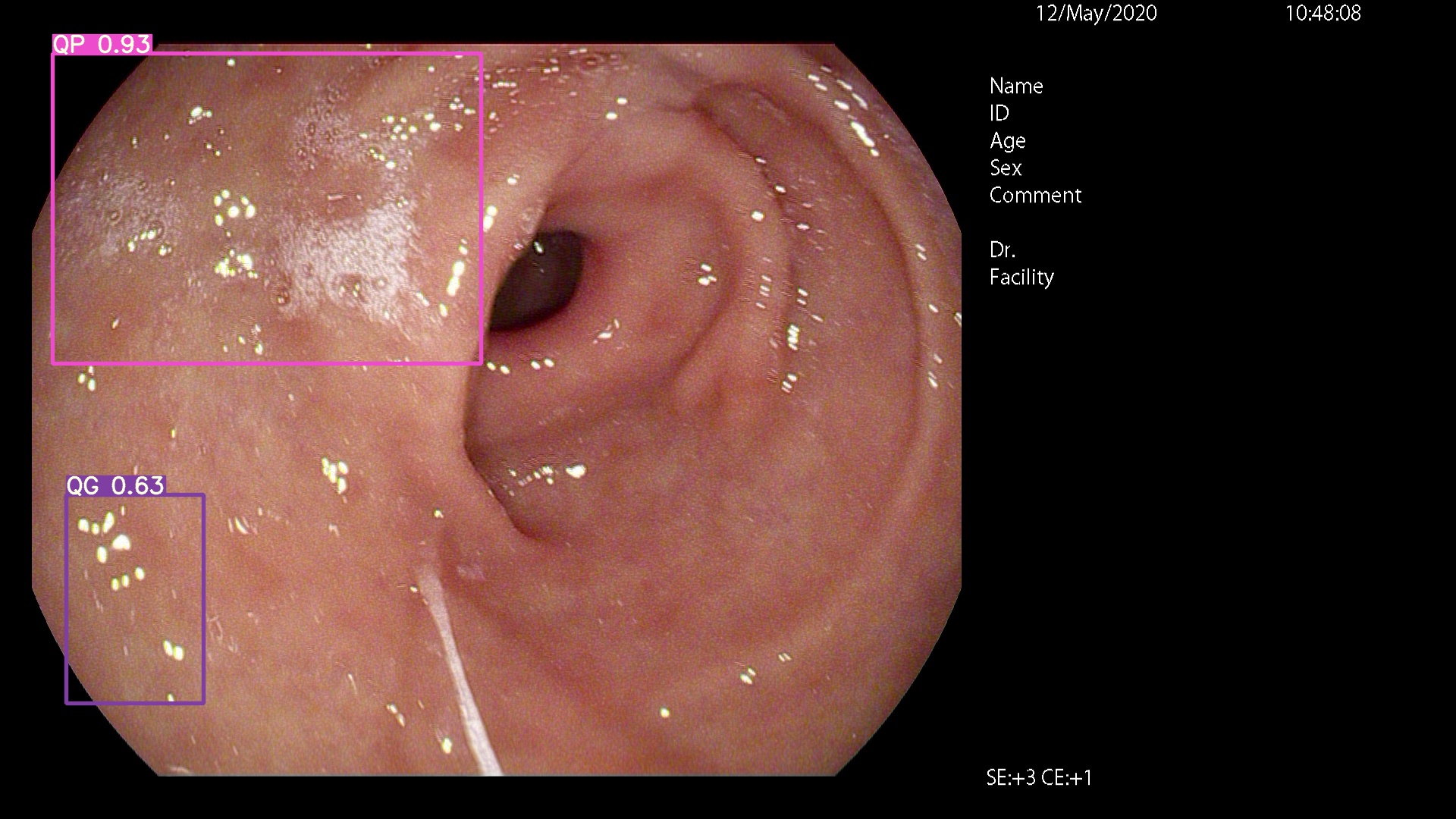
제발 여기 오세요
참조
[1] .https : //github.com/ultralytics/yolov5
[2] .https : //github.com/ultralytics/yolov5/wiki/train-custom-data


