YOLO v5
1.0.0
? ? Sekarang YOLOV5 telah diperbarui ke versi 6.0, tetapi metode pelatihannya sama dengan repo ini. Anda hanya perlu menginstal lingkungan Python yang sesuai sesuai dengan versi yang sesuai. Konstruksi datasetnya, modifikasi file konfigurasi, metode pelatihan, dll. Benar -benar konsisten dengan repo ini!
? ? Kami memberikan panggilan Tensorrt YOLOV5 dan Kode C ++ dan Python yang dikuantisasi (metode akselerasi Tensorrt berbeda dari panggilan TensorRt yang disediakan oleh repo ini). Orang -orang besar yang membutuhkan dapat meninggalkan pesan dalam masalah!
Xu Jing
Karena penyesuaian tulang punggung dan beberapa parameter dari versi baru YOLO V5 resmi, banyak teman telah mengunduh model pra-terlatih resmi terbaru dan tidak tersedia. Di sini kami memberikan alamat unduhan Disk Cloud Baidu dari model pra-terlatih Yolo V5 asli.
Tautan: https://pan.baidu.com/s/1sdwp6i_mnrlk45qdb3-ynw Kode ekstraksi: 423j
Yolov4 belum mereda, YOLOV5 telah dirilis!
Pada 9 Juni, Ultralytics membuka sumber YOLOV5, kurang dari 50 hari setelah YOLOV4 terakhir dirilis. Dan kali ini, YOLOV5 sepenuhnya diimplementasikan berdasarkan Pytorch!
Kontributor utama Yolo V5 adalah penulis peningkatan data mosaik yang disorot dalam Yolo V4

Proyek ini menjelaskan cara melatih Yolo V5 berdasarkan dataset Anda sendiri
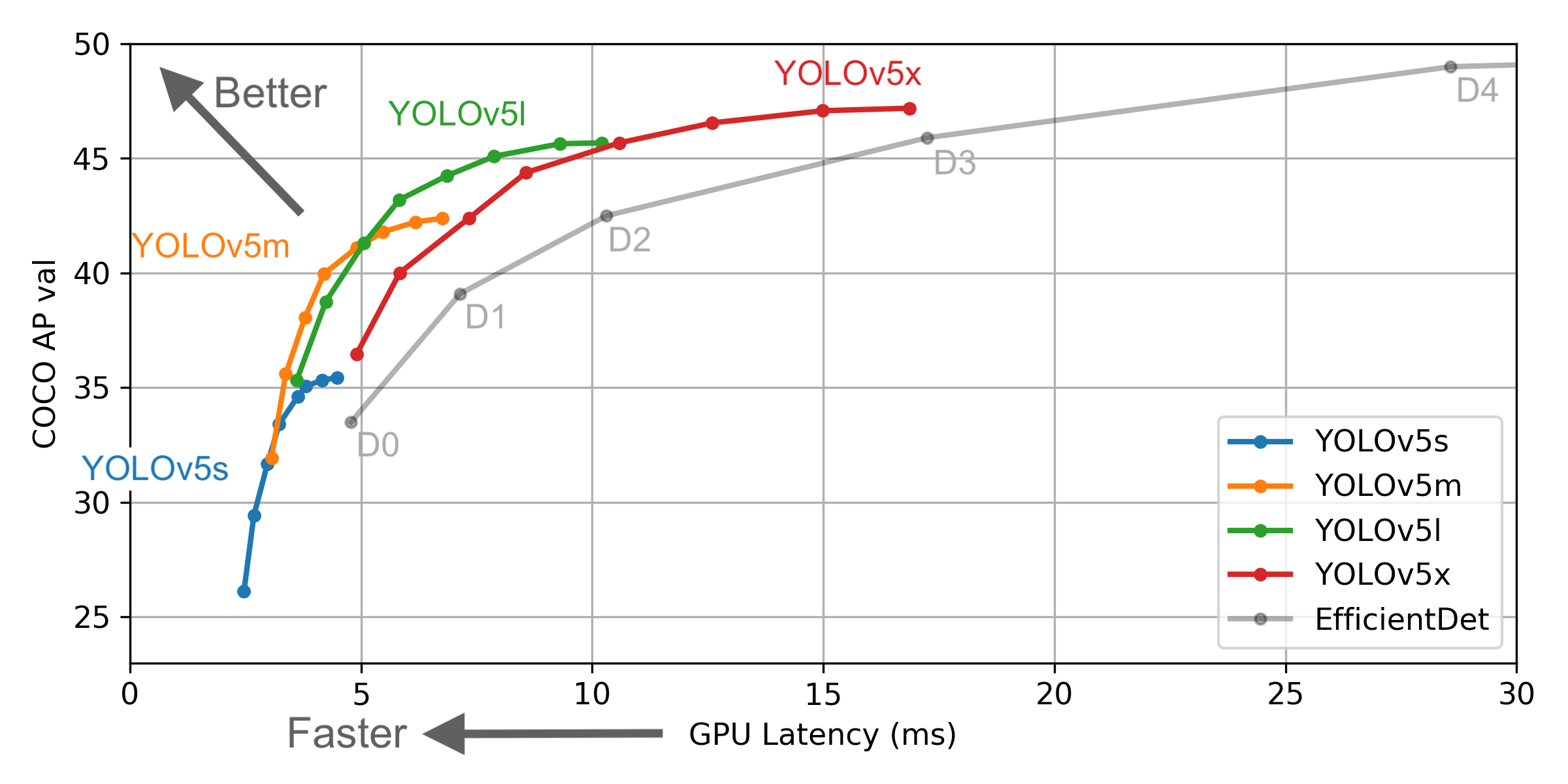
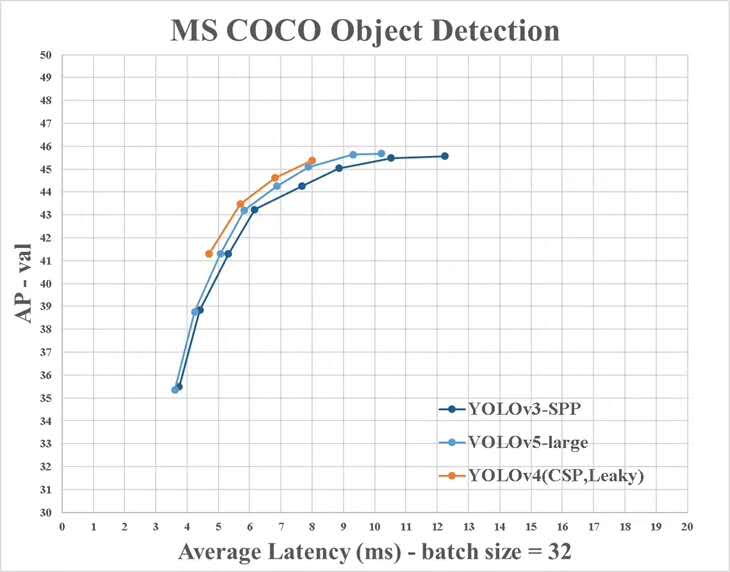
Namun, ada beberapa perbedaan antara informasi yang disediakan oleh Yolo V4 dan yang resmi:
Instal Paket Python yang Diperlukan dan Konfigurasikan Lingkungan Terkait
# python3.6
# torch==1.3.0
# torchvision==0.4.1
# git clone yolo v5 repo
git clone https://github.com/ultralytics/yolov5 # clone repo
# 下载官方的样例数据(这一步可以省略)
python3 -c "from yolov5.utils.google_utils import gdrive_download; gdrive_download('1n_oKgR81BJtqk75b00eAjdv03qVCQn2f','coco128.zip')" # download dataset
cd yolov5
# 安装必要的package
pip3 install -U -r requirements.txt
dataset.yaml File Konfigurasi.YAML dari Dataset Data/Coco128.YAML berasal dari 128 gambar pelatihan pertama dari dataset Coco Train2017. Anda dapat memodifikasi file yaml dari dataset Anda sendiri berdasarkan yaml
# train and val datasets (image directory or *.txt file with image paths)
train: ./datasets/score/images/train/
val: ./datasets/score/images/val/
# number of classes
nc: 3
# class names
names: ['QP', 'NY', 'QG']
Anda dapat menggunakan LabelIMG, LABME, LabelBox, dan CVAT untuk memberi label data. Untuk deteksi target, Anda perlu memberi label pada kotak pembatas. Maka Anda perlu mengonversi anotasi ke bentuk anotasi yang sama dengan format DarkNet , dan setiap gambar menghasilkan file anotasi *.txt (jika gambar tidak memiliki target anotasi, Anda tidak perlu membuat file *.txt ). File *.txt yang dibuat mengikuti aturan berikut:
class x_center y_center width height def convert ( size , box ):
'''
将标注的xml文件标注转换为darknet形的坐标
'''
dw = 1. / ( size [ 0 ])
dh = 1. / ( size [ 1 ])
x = ( box [ 0 ] + box [ 1 ]) / 2.0 - 1
y = ( box [ 2 ] + box [ 3 ]) / 2.0 - 1
w = box [ 1 ] - box [ 0 ]
h = box [ 3 ] - box [ 2 ]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return ( x , y , w , h ) Setiap file anotasi *.txt disimpan dalam direktori file yang mirip dengan gambar. Anda hanya perlu mengganti /images/*.jpg dengan /lables/*.txt (pemrosesan internal kode ini seperti ini saat memuat data. Anda dapat memodifikasinya ke format data VOC untuk memuat)
Misalnya:
datasets/score/images/train/000000109622.jpg # image
datasets/score/labels/train/000000109622.txt # label
Jika file label berisi kategori 5 orang (orang adalah kategori pertama dalam dataset Coco, jadi indeksnya adalah 0):
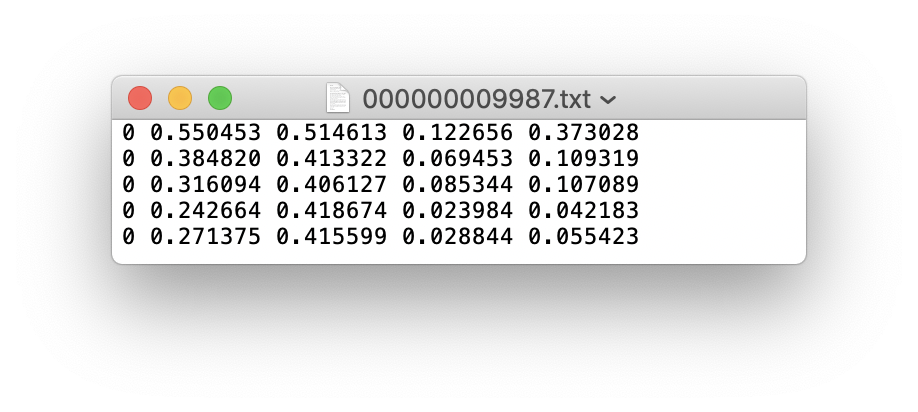
Simpan folder gambar dan label dari pelatihan set pelatihan dan set verifikasi val sebagai berikut

Pada titik ini, fase persiapan data telah selesai. Selama proses tersebut, kami mengasumsikan bahwa proses pembersihan data algoritma dan proses pembagian data telah selesai dengan sendirinya.
Pilih model yang perlu dilatih dalam folder proyek ./models . Di sini kami memilih yolov5x.yaml, model terbesar untuk pelatihan. Lihat tabel di readme resmi untuk memahami ukuran dan kecepatan inferensi dari berbagai model. Jika Anda telah memilih model, Anda perlu memodifikasi file yaml yang sesuai dengan model
# parameters
nc : 3 # number of classes <------------------ UPDATE to match your dataset
depth_multiple : 1.33 # model depth multiple
width_multiple : 1.25 # layer channel multiple
# anchors
anchors :
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov5 backbone
backbone :
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 1-P1/2
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]], # 10
]
# yolov5 head
head :
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# Train yolov5x on score for 300 epochs
$ python3 train.py --img-size 640 --batch-size 16 --epochs 300 --data ./data/score.yaml --cfg ./models/score/yolov5x.yaml --weights weights/yolov5x.pt
Setelah memulai pelatihan, periksa train*.jpg gambar untuk melihat data pelatihan, label dan peningkatan data. Jika gambar Anda menampilkan label atau peningkatan data salah, Anda harus memeriksa apakah ada masalah dengan proses konstruksi dataset Anda.
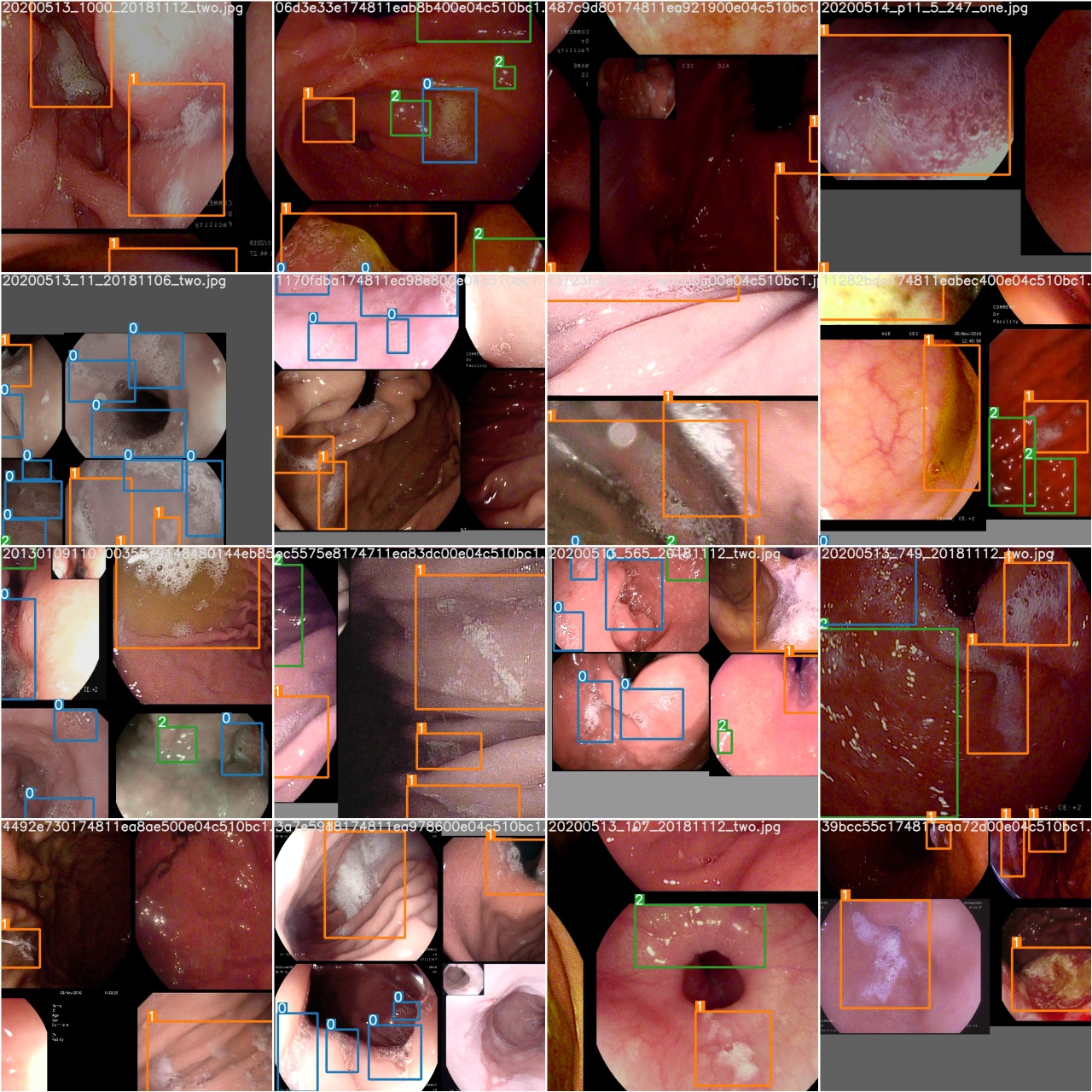
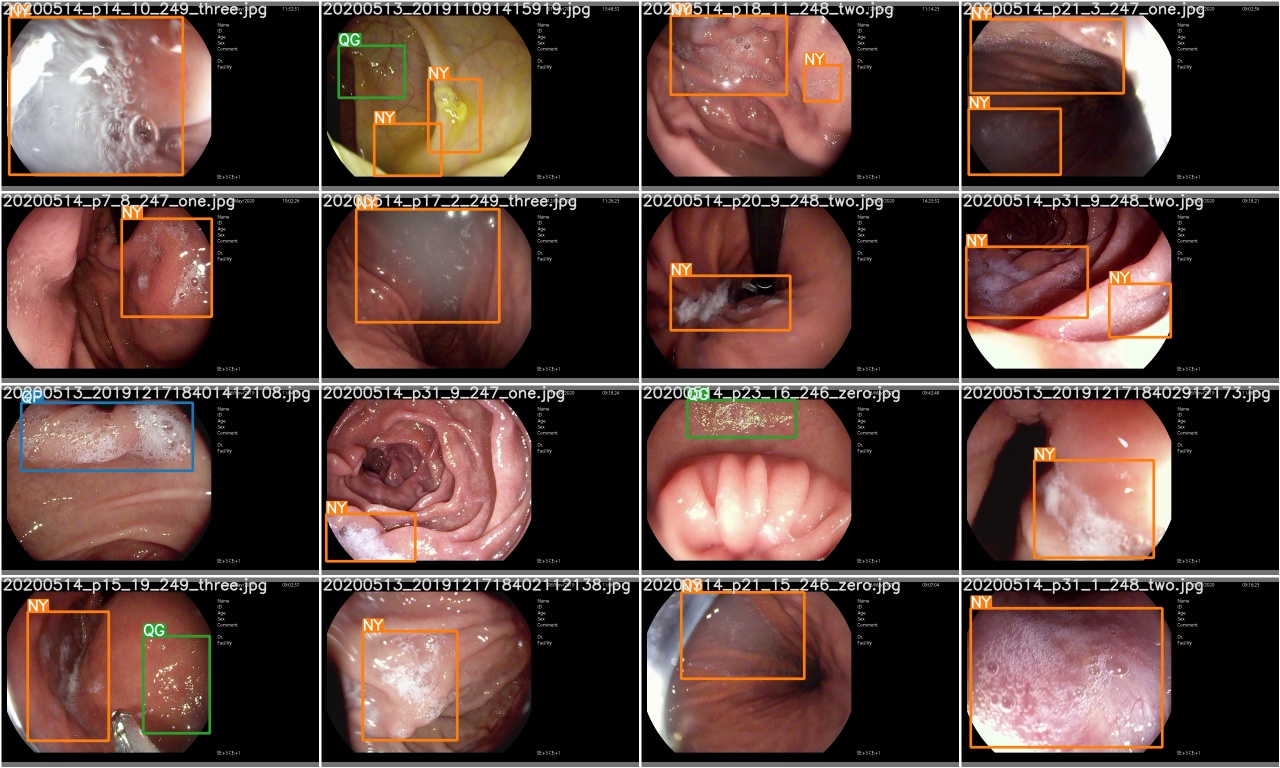
Setelah zaman pelatihan selesai, periksa test_batch0_gt.jpg untuk melihat label -label kebenaran batch 0
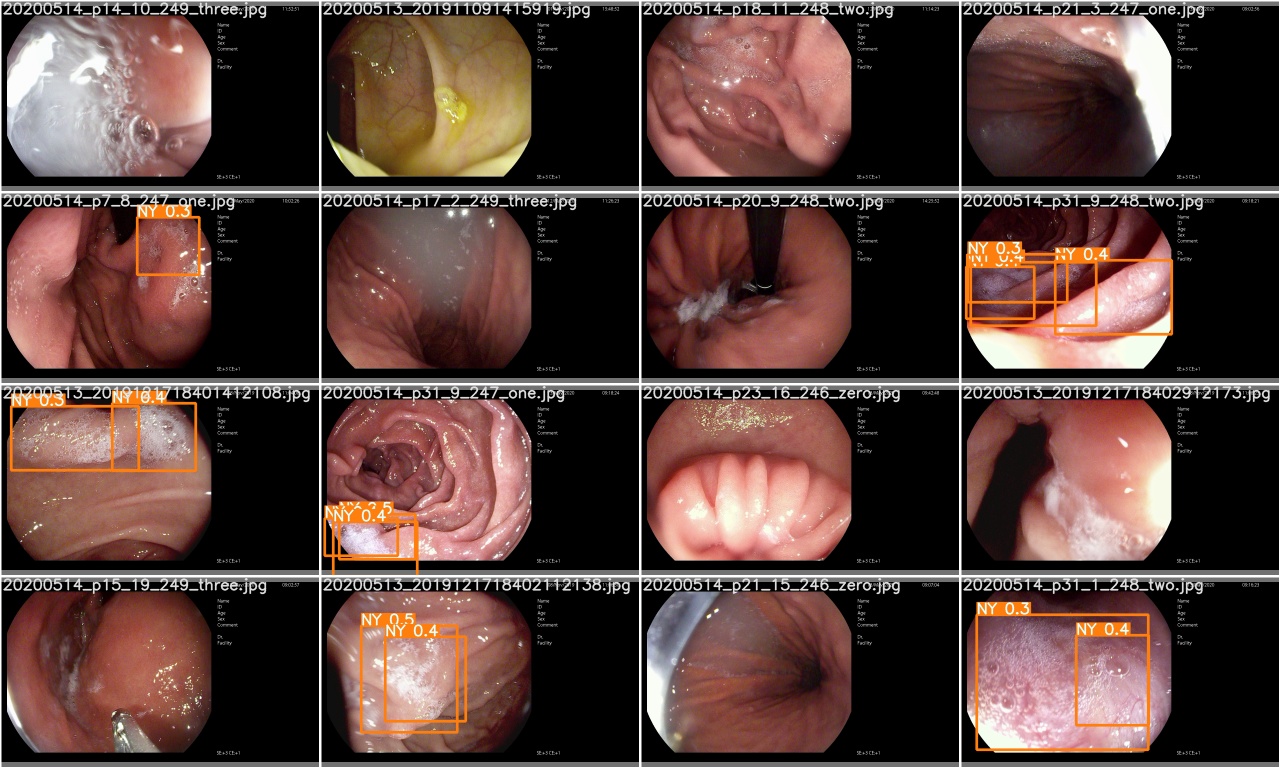
Periksa test_batch0_pred.jpg untuk melihat prediksi batch uji 0
Metrik kerugian dan evaluasi pelatihan disimpan di papan tensor dan results.txt . results.txt akan divisualisasikan sebagai results.png setelah pelatihan selesai
> >> from utils . utils import plot_results
> >> plot_results ()
# 如果你是用远程连接请安装配置Xming: https://blog.csdn.net/akuoma/article/details/82182913 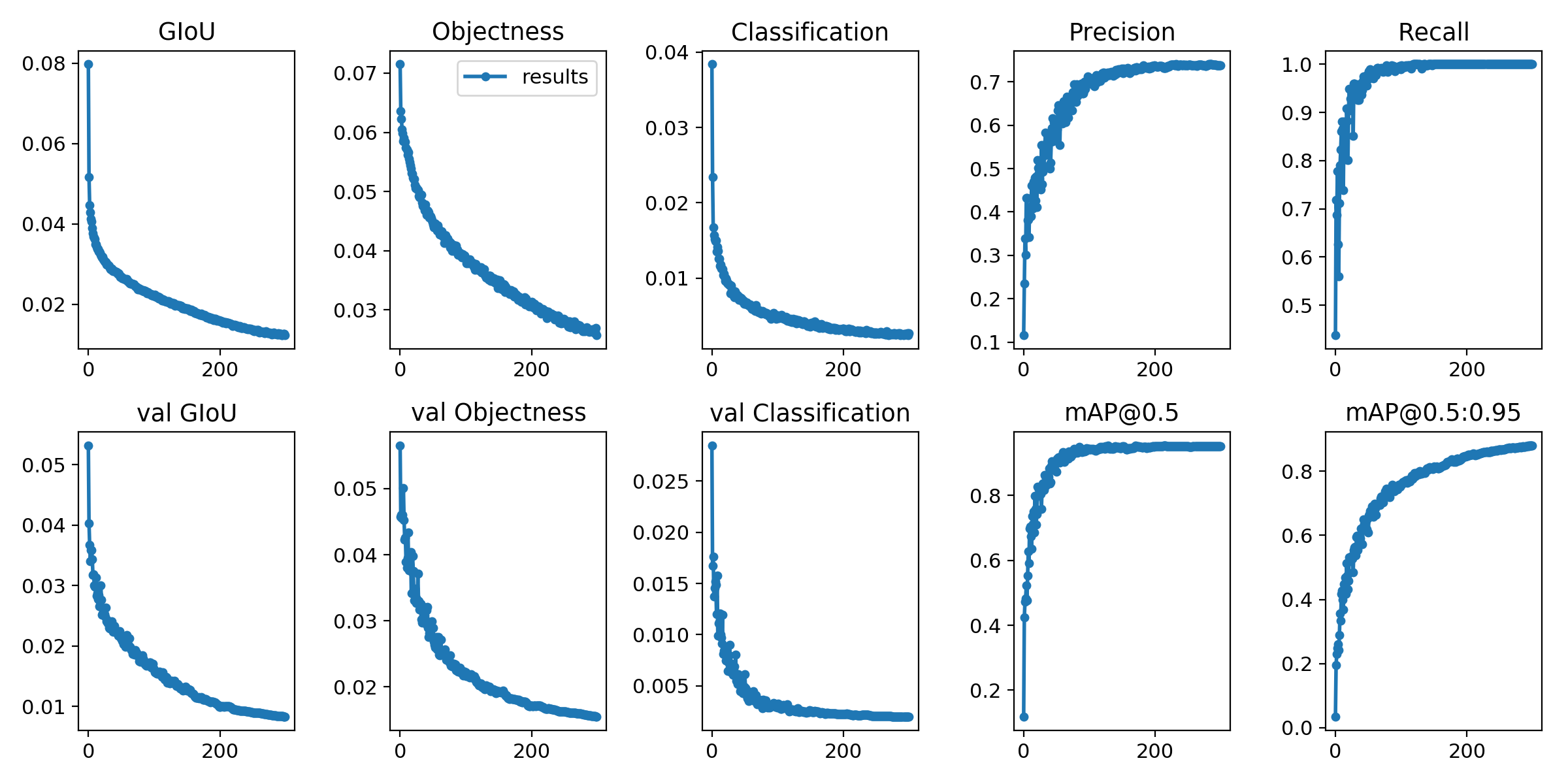
$ python3 detect . py - - source file . jpg # image
file . mp4 # video
. / dir # directory
0 # webcam
rtsp : // 170.93 . 143.139 / rtplive / 470011e600 ef003a004ee33696235daa # rtsp stream
http : // 112.50 . 243.8 / PLTV / 88888888 / 224 / 3221225900 / 1. m3u8 # http stream # inference /home/myuser/xujing/EfficientDet-Pytorch/dataset/test/ 文件夹下的图像
$ python3 detect . py - - source / home / myuser / xujing / EfficientDet - Pytorch / dataset / test / - - weights weights / best . pt - - conf 0.1
$ python3 detect . py - - source . / inference / images / - - weights weights / yolov5x . pt - - conf 0.5
# inference 视频
$ python3 detect . py - - source test . mp4 - - weights weights / yolov5x . pt - - conf 0.4 
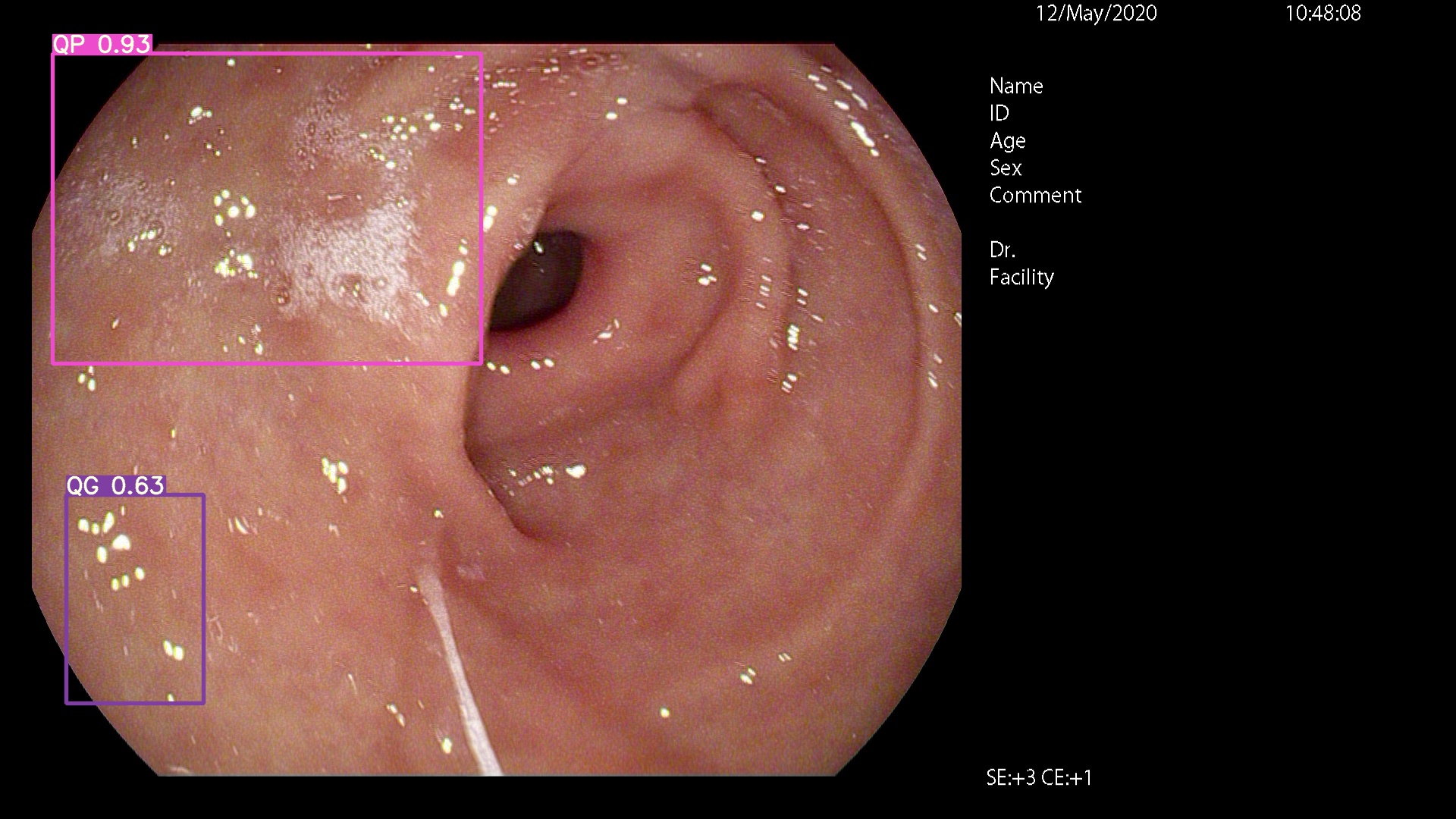
Silakan datang ke sini
Referensi
[1] .https: //github.com/ultralytics/yolov5
[2] .https: //github.com/ultralytics/yolov5/wiki/train-custom-data


