YOLO v5
1.0.0
? ? Jetzt wurde Yolov5 auf Version 6.0 aktualisiert, aber seine Trainingsmethode ist dieselbe wie dieses Repo. Sie müssen nur die entsprechende Python -Umgebung gemäß der entsprechenden Version installieren. Die Konstruktion seines Datensatzes, die Änderung der Konfigurationsdatei, die Schulungsmethode usw. stimmen vollständig mit diesem Repo überein!
? ? Wir bieten Yolov5 Tensorrt -Aufrufe und int8 quantisierte C ++ - und Python -Code (die Tensorrt -Beschleunigungsmethode unterscheidet sich von den von diesem Repo bereitgestellten Tensorrt -Aufrufen). Große Jungs in Not können eine Nachricht in Problemen hinterlassen!
Xu Jing
Aufgrund der Anpassung des Rückgrates und einiger Parameter der offiziellen neuen Version von Yolo V5 haben viele Freunde das neueste offizielle vorgebreitete Modell heruntergeladen und sind nicht verfügbar. Hier stellen wir die Download-Adresse des ursprünglichen Yolo V5 vorgeburten Yolo V5-Modells an.
Link: https://pan.baidu.com/s/1sdwp6i_Mnrlk45qdb3-ynw Extraktionscode: 423J
Yolov4 ist noch nicht nachgelassen, Yolov5 wurde veröffentlicht!
Am 9. Juni eröffnete Ultralytics die Quelle von Yolov5, weniger als 50 Tage nach der Veröffentlichung des letzten Yolov4. Und diesmal ist Yolov5 vollständig auf der Grundlage von Pytorch implementiert!
Der Hauptbeitrag zu Yolo V5 ist der Autor der in Yolo V4 hervorgehobenen Mosaikdatenverstärkung

Dieses Projekt beschreibt, wie Yolo V5 basierend auf Ihrem eigenen Datensatz trainiert wird
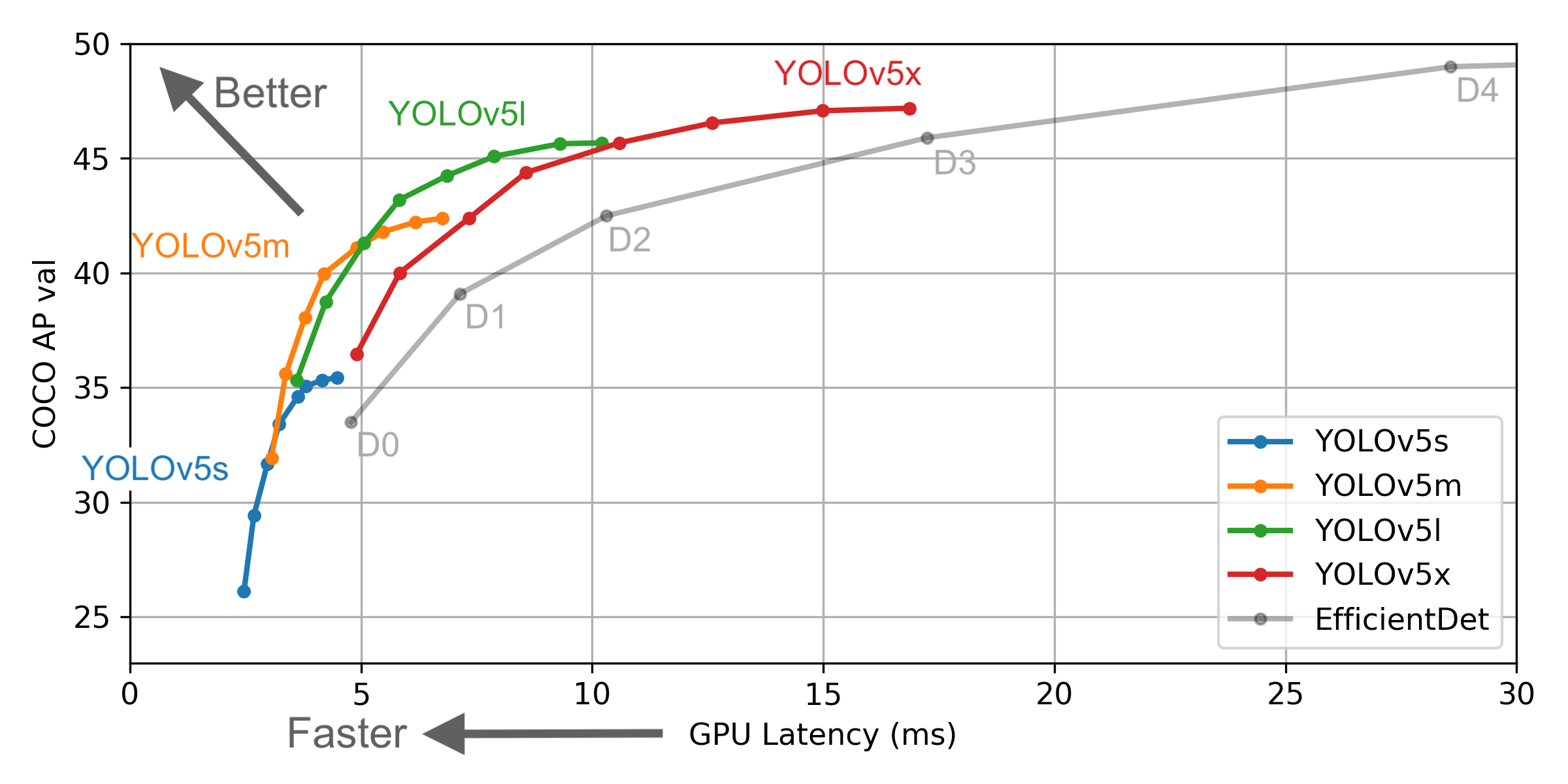
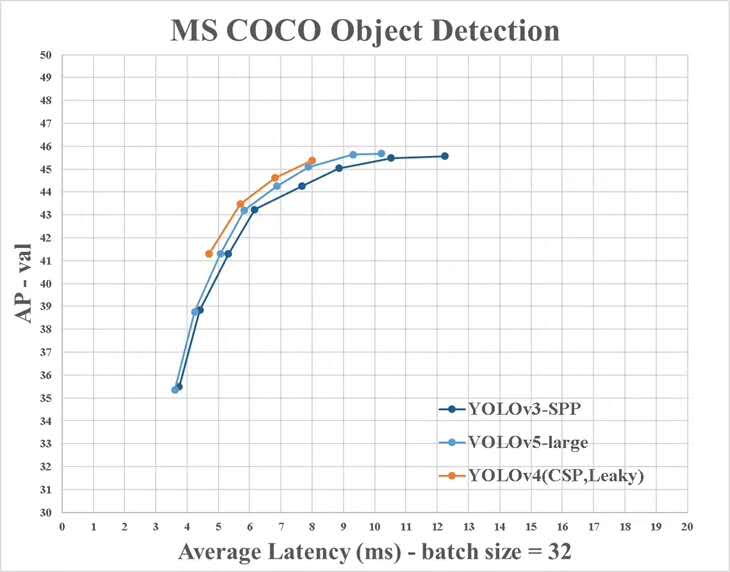
Es gibt jedoch einige Unterschiede zwischen den Informationen von Yolo V4 und den offiziellen:
Installieren Sie das erforderliche Python -Paket und konfigurieren Sie verwandte Umgebungen
# python3.6
# torch==1.3.0
# torchvision==0.4.1
# git clone yolo v5 repo
git clone https://github.com/ultralytics/yolov5 # clone repo
# 下载官方的样例数据(这一步可以省略)
python3 -c "from yolov5.utils.google_utils import gdrive_download; gdrive_download('1n_oKgR81BJtqk75b00eAjdv03qVCQn2f','coco128.zip')" # download dataset
cd yolov5
# 安装必要的package
pip3 install -U -r requirements.txt
dataset.yaml des Datensatzes Data/Coco128.yaml stammt aus den ersten 128 Trainingsbildern des CoCo Train2017 -Datensatzes. Sie können die yaml -Datei Ihres eigenen Datensatzes basierend auf dieser yaml
# train and val datasets (image directory or *.txt file with image paths)
train: ./datasets/score/images/train/
val: ./datasets/score/images/val/
# number of classes
nc: 3
# class names
names: ['QP', 'NY', 'QG']
Sie können LabelImg, Labme, Labelbox und CVAT verwenden, um Daten zu kennzeichnen. Zur Zielerkennung müssen Sie Begrenzungsbox kennzeichnen. Anschließend müssen Sie die Annotation in das gleiche Annotationsformat wie DarkNet -Format konvertieren, und jedes Bild generiert eine *.txt -Annotationsdatei (wenn das Bild kein Annotationsziel hat, müssen Sie keine *.txt -Datei erstellen). Die erstellte *.txt -Datei folgt den folgenden Regeln:
class x_center y_center width height def convert ( size , box ):
'''
将标注的xml文件标注转换为darknet形的坐标
'''
dw = 1. / ( size [ 0 ])
dh = 1. / ( size [ 1 ])
x = ( box [ 0 ] + box [ 1 ]) / 2.0 - 1
y = ( box [ 2 ] + box [ 3 ]) / 2.0 - 1
w = box [ 1 ] - box [ 0 ]
h = box [ 3 ] - box [ 2 ]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return ( x , y , w , h ) Jede Annotation *.txt -Datei wird in einem Dateiverzeichnis gespeichert, das dem Bild ähnelt. Sie müssen nur /images/*.jpg durch /lables/*.txt ersetzen (diese interne Code -Verarbeitung ist beim Laden von Daten wie diese. Sie können diese am VOC -Datenformat zum Laden ändern).
Zum Beispiel:
datasets/score/images/train/000000109622.jpg # image
datasets/score/labels/train/000000109622.txt # label
Wenn eine Etikettendatei 5 Personenkategorien enthält (Person ist die erste Kategorie im Coco -Datensatz, also ist der Index 0):
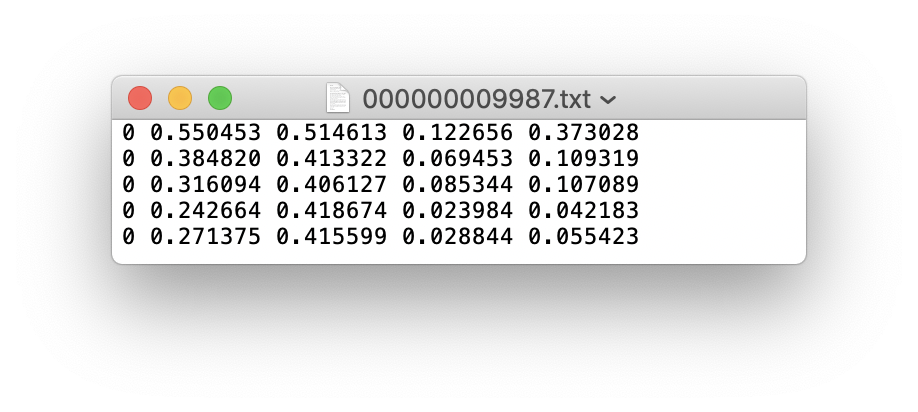
Speichern Sie die Ordner der Bilder und Beschriftungen des Trainingssatzes und der Überprüfungsset Val wie folgt

Zu diesem Zeitpunkt wurde die Datenvorbereitungsphase abgeschlossen. Während des Prozesses gehen wir davon aus, dass der Datenreinigungs- und Datensatzabteilungsprozess des Algorithmus -Ingenieurs selbst abgeschlossen wurde.
Wählen Sie ein Modell aus, das im Ordner des ./models geschult werden muss. Hier wählen wir yolov5x.yaml, das größte Modell für das Training. Siehe die Tabelle im offiziellen Readme, um die Größe und Inferenzgeschwindigkeit verschiedener Modelle zu verstehen. Wenn Sie ein Modell ausgewählt haben, müssen Sie die dem Modell entsprechende yaml -Datei ändern
# parameters
nc : 3 # number of classes <------------------ UPDATE to match your dataset
depth_multiple : 1.33 # model depth multiple
width_multiple : 1.25 # layer channel multiple
# anchors
anchors :
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov5 backbone
backbone :
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 1-P1/2
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]], # 10
]
# yolov5 head
head :
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# Train yolov5x on score for 300 epochs
$ python3 train.py --img-size 640 --batch-size 16 --epochs 300 --data ./data/score.yaml --cfg ./models/score/yolov5x.yaml --weights weights/yolov5x.pt
Überprüfen Sie nach dem Training train*.jpg Image, um Schulungsdaten, Beschriftungen und Datenverbesserungen anzuzeigen. Wenn in Ihrem Bild Beschriftungen oder Datenverbesserungen falsch angezeigt werden, sollten Sie prüfen, ob ein Problem mit dem Konstruktionsprozess Ihres Datensatzes vorliegt.
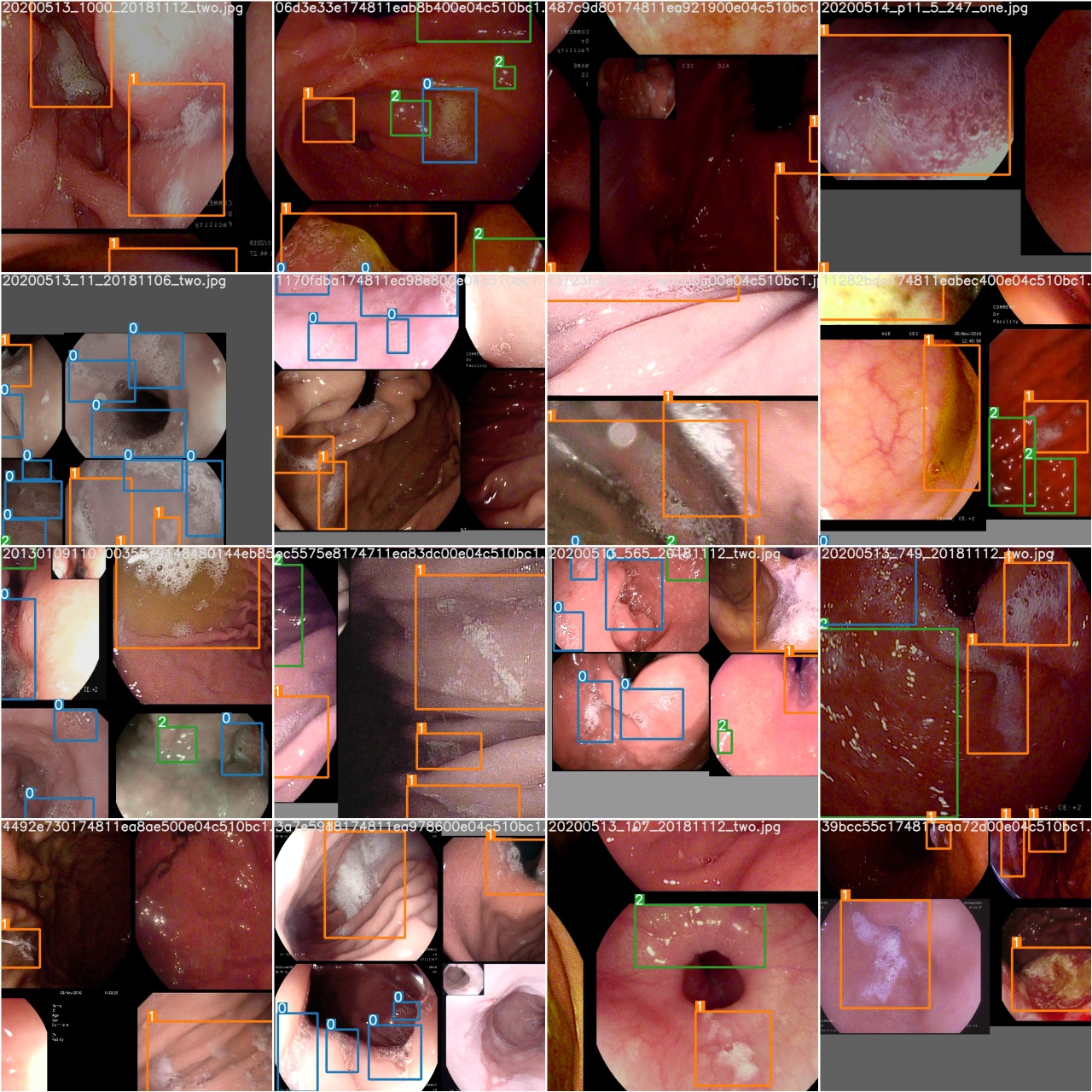
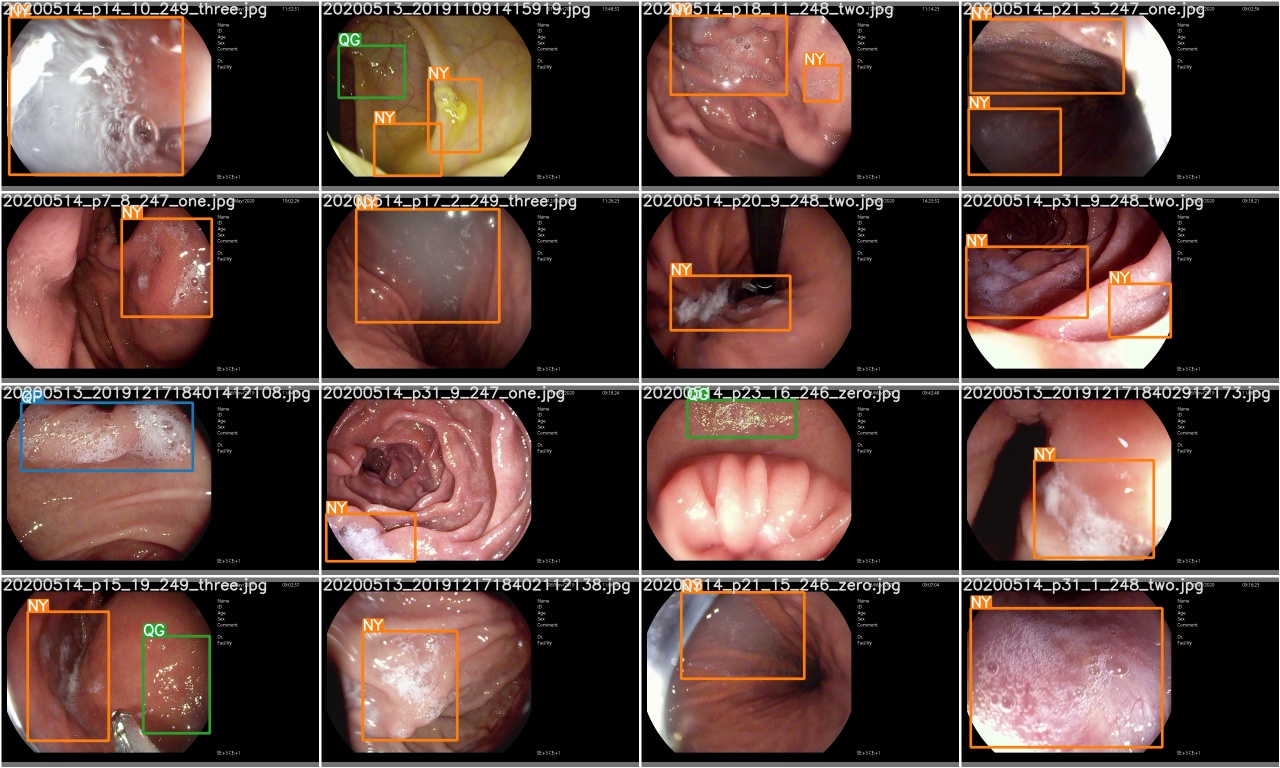
Überprüfen Sie nach Abschluss einer Trainings -Epoche test_batch0_gt.jpg , um die Etiketten von Batch 0 Bodenwahrheit anzuzeigen
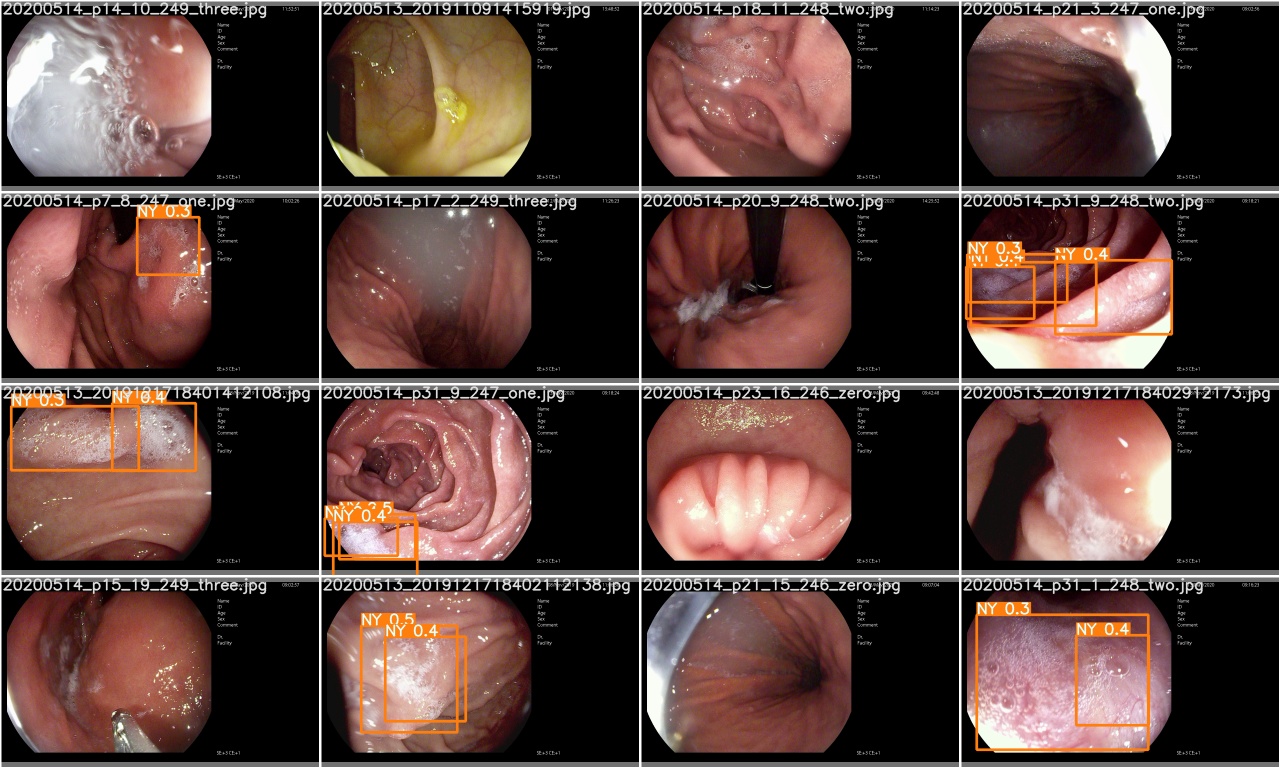
Überprüfen Sie test_batch0_pred.jpg um die Vorhersage von Test -Stapel 0 anzuzeigen.
Die Trainingsverluste und Bewertungsmetriken werden im Tensorboard und results.txt gespeichert. results.txt wird so visualisiert wie results.png nach dem Training ist abgeschlossen
> >> from utils . utils import plot_results
> >> plot_results ()
# 如果你是用远程连接请安装配置Xming: https://blog.csdn.net/akuoma/article/details/82182913 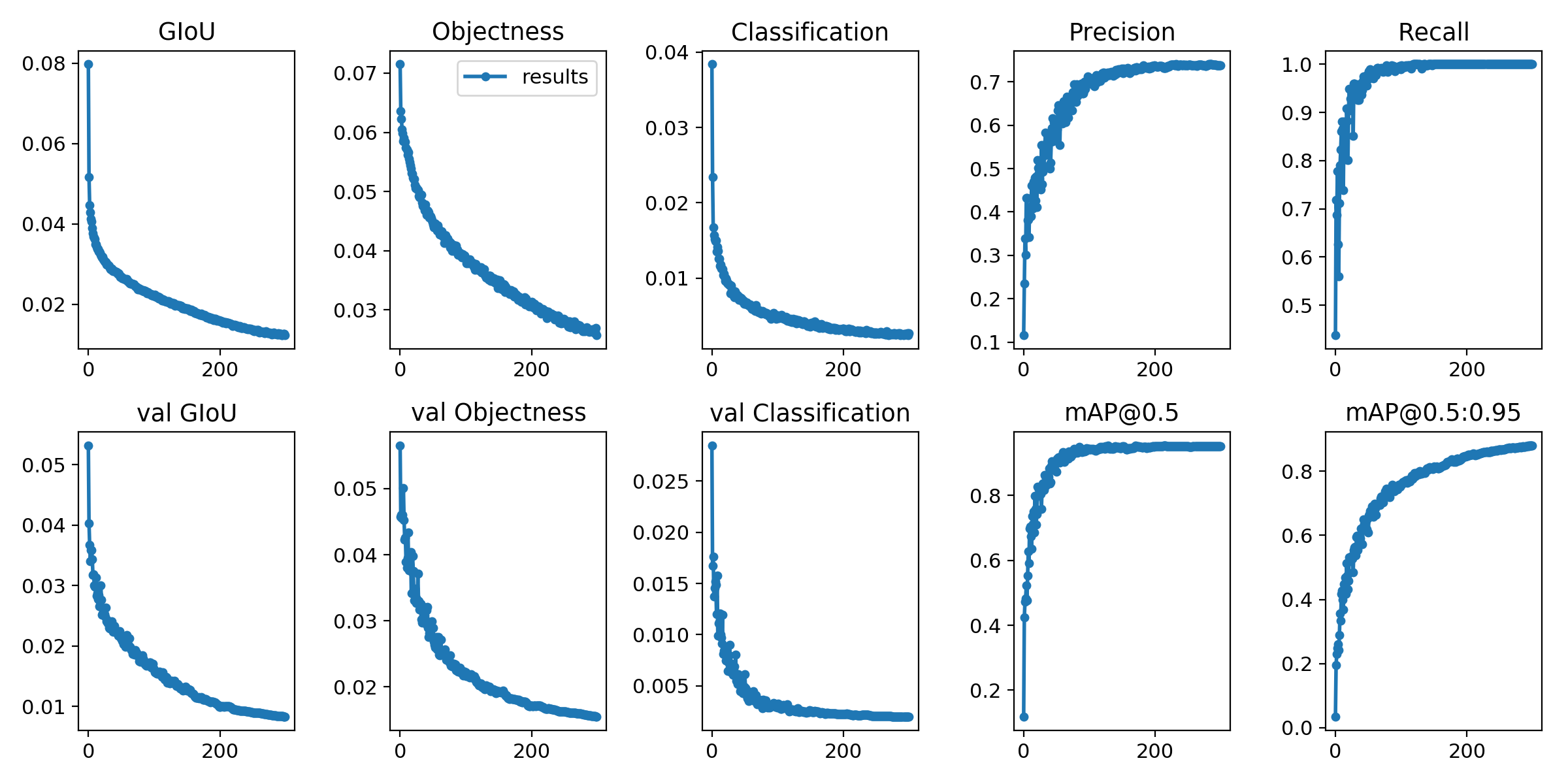
$ python3 detect . py - - source file . jpg # image
file . mp4 # video
. / dir # directory
0 # webcam
rtsp : // 170.93 . 143.139 / rtplive / 470011e600 ef003a004ee33696235daa # rtsp stream
http : // 112.50 . 243.8 / PLTV / 88888888 / 224 / 3221225900 / 1. m3u8 # http stream # inference /home/myuser/xujing/EfficientDet-Pytorch/dataset/test/ 文件夹下的图像
$ python3 detect . py - - source / home / myuser / xujing / EfficientDet - Pytorch / dataset / test / - - weights weights / best . pt - - conf 0.1
$ python3 detect . py - - source . / inference / images / - - weights weights / yolov5x . pt - - conf 0.5
# inference 视频
$ python3 detect . py - - source test . mp4 - - weights weights / yolov5x . pt - - conf 0.4 
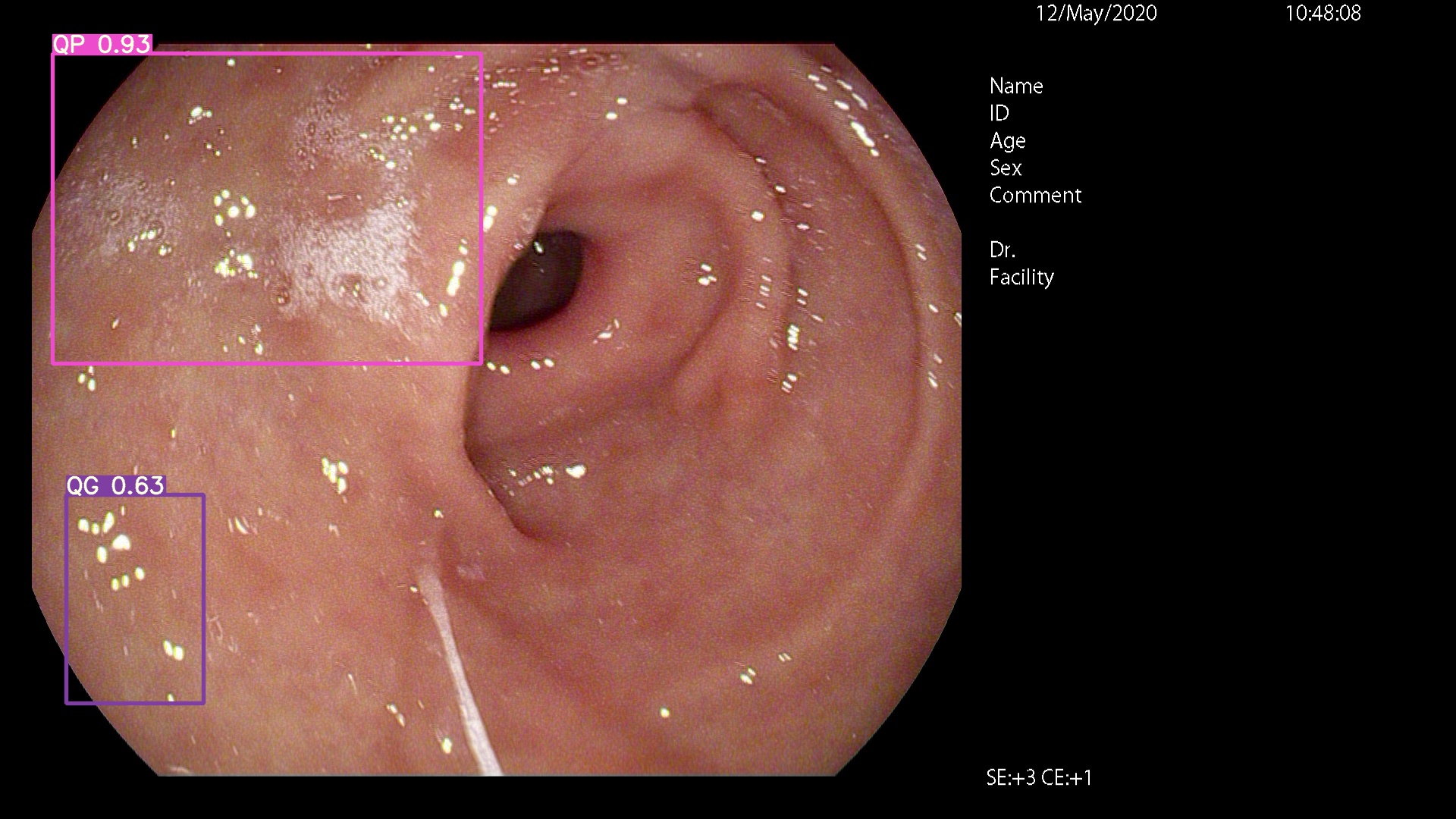
Bitte komm her
Referenz
[1] .https: //github.com/ultralytics/yolov5
[2] .https: //github.com/ultralytics/yolov5/wiki/train-custom-data


