YOLO v5
1.0.0
? ?現在、Yolov5はバージョン6.0に更新されましたが、そのトレーニング方法はこのレポと同じです。対応するバージョンに従って、対応するPython環境をインストールするだけです。データセット、構成ファイルの変更、トレーニング方法などの構築は、このレポと完全に一致しています!
? ? Yolov5 Tensort CallsとInt8 Quantized C ++およびPythonコードを提供します(Tensort Acceleration Methodは、このレポで提供されるTensort Callsとは異なります)。困っている大物は問題にメッセージを残すことができます!
Xu Jing
バックボーンの調整とYolo V5の公式バージョンのいくつかのパラメーターのために、多くの友人が最新の公式事前訓練モデルをダウンロードしており、利用できません。ここでは、元のYolo V5事前訓練モデルのBaidu Cloud Diskダウンロードアドレスを提供します。
リンク:https://pan.baidu.com/s/1sdwp6i_mnrlk45qdb3-ynw抽出コード:423j
Yolov4はまだ沈静化しておらず、Yolov5はリリースされました!
6月9日、Ultralyticsは、最後のYolov4が放出されてから50日以内にYolov5の源を開設しました。そして今回は、Yolov5はPytorchに基づいて完全に実装されています!
Yolo V5への主な貢献者は、Yolo V4で強調されたモザイクデータ強化の著者です

このプロジェクトでは、独自のデータセットに基づいてYolo V5をトレーニングする方法について説明します
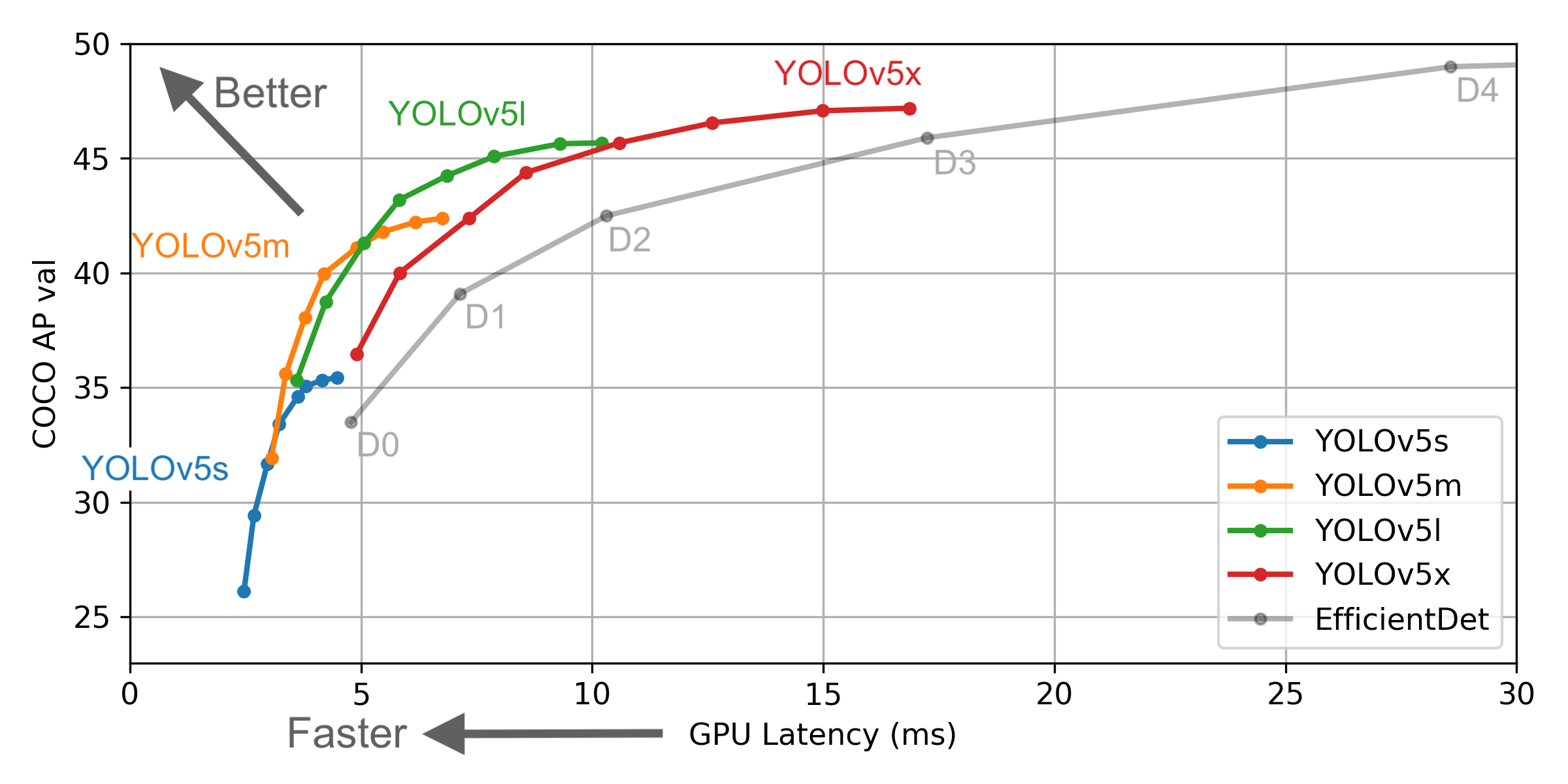
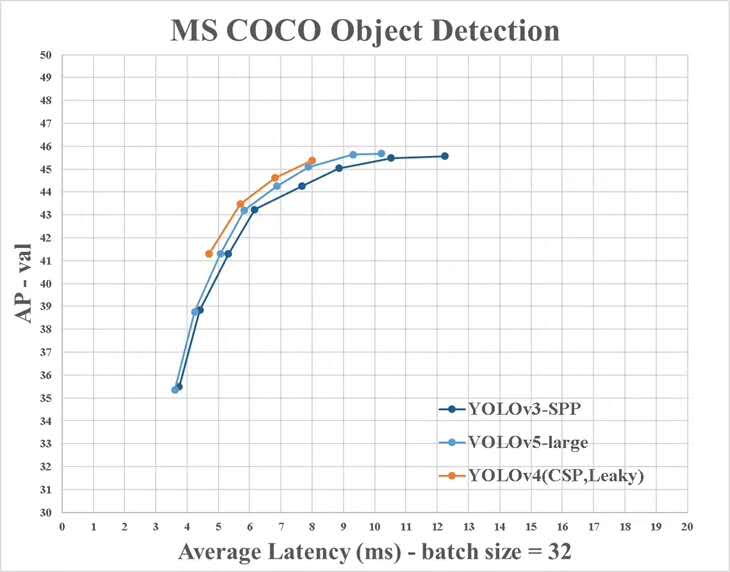
ただし、Yolo V4から提供された情報と公式の情報にはいくつかの違いがあります。
必要なPythonパッケージをインストールし、関連する環境を構成します
# python3.6
# torch==1.3.0
# torchvision==0.4.1
# git clone yolo v5 repo
git clone https://github.com/ultralytics/yolov5 # clone repo
# 下载官方的样例数据(这一步可以省略)
python3 -c "from yolov5.utils.google_utils import gdrive_download; gdrive_download('1n_oKgR81BJtqk75b00eAjdv03qVCQn2f','coco128.zip')" # download dataset
cd yolov5
# 安装必要的package
pip3 install -U -r requirements.txt
dataset.yamlを作成しますdata/coco128.yamlは、CoCo Train2017データセットの最初の128のトレーニング画像から来ています。このYAMLに基づいて、独自のデータセットのyamlファイルを変更できますyaml
# train and val datasets (image directory or *.txt file with image paths)
train: ./datasets/score/images/train/
val: ./datasets/score/images/val/
# number of classes
nc: 3
# class names
names: ['QP', 'NY', 'QG']
Labelimg、Labme、Labelbox、およびCVATを使用して、データをラベル付けできます。ターゲット検出のために、境界ボックスにラベルを付ける必要があります。次に、アノテーションをDarkNet形式と同じアノテーションフォームに変換する必要があり、各画像は*.txtアノテーションファイルを生成します(画像にアノテーションターゲットがない場合、 *.txtファイルを作成する必要はありません)。作成された*.txtファイルは、次のルールに従います。
class x_center y_center width height含まれています def convert ( size , box ):
'''
将标注的xml文件标注转换为darknet形的坐标
'''
dw = 1. / ( size [ 0 ])
dh = 1. / ( size [ 1 ])
x = ( box [ 0 ] + box [ 1 ]) / 2.0 - 1
y = ( box [ 2 ] + box [ 3 ]) / 2.0 - 1
w = box [ 1 ] - box [ 0 ]
h = box [ 3 ] - box [ 2 ]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return ( x , y , w , h )各注釈*.txtファイルは、画像と同様のファイルディレクトリに保存されます。 /images/*.jpg /lables/*.txtに置き換えるだけです(このコード内部処理はデータを読み込むときにこのようなものです。ロードのためにVOCデータ形式に変更できます)
例えば:
datasets/score/images/train/000000109622.jpg # image
datasets/score/labels/train/000000109622.txt # label
ラベルファイルに5人のカテゴリが含まれている場合(人がCOCOデータセットの最初のカテゴリであるため、インデックスは0です):
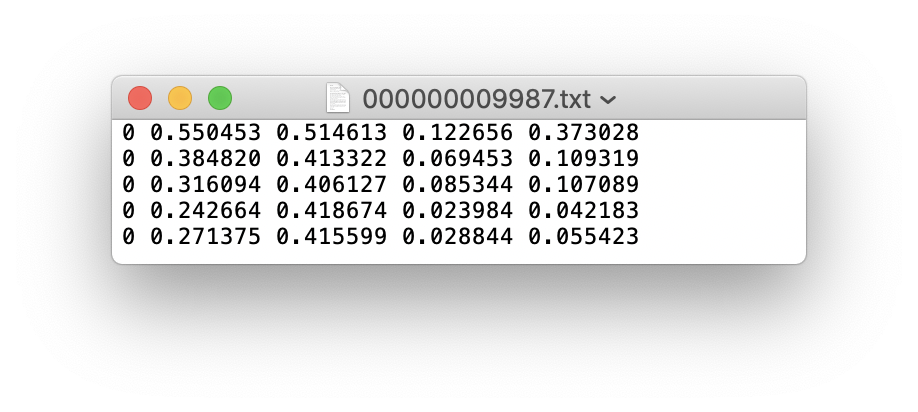
トレーニングセットトレインと検証セットVALの画像とラベルフォルダーを次のように保存します

この時点で、データ準備フェーズが完了しました。プロセス中に、アルゴリズムエンジニアのデータクリーニングとデータセット部門プロセスが単独で完了したと想定しています。
プロジェクトでトレーニングする必要があるモデルを選択します./modelsフォルダー。ここでは、トレーニングの最大のモデルであるYolov5x.yamlを選択します。異なるモデルのサイズと推論速度を理解するには、公式のREADMEのテーブルを参照してください。モデルを選択した場合、モデルに対応するyamlファイルを変更する必要があります
# parameters
nc : 3 # number of classes <------------------ UPDATE to match your dataset
depth_multiple : 1.33 # model depth multiple
width_multiple : 1.25 # layer channel multiple
# anchors
anchors :
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov5 backbone
backbone :
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 1-P1/2
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]], # 10
]
# yolov5 head
head :
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# Train yolov5x on score for 300 epochs
$ python3 train.py --img-size 640 --batch-size 16 --epochs 300 --data ./data/score.yaml --cfg ./models/score/yolov5x.yaml --weights weights/yolov5x.pt
トレーニングを開始した後、 train*.jpg画像をチェックして、トレーニングデータ、ラベル、データの強化を表示します。画像がラベルまたはデータの強化が正しくない場合、データセットの構築プロセスに問題があるかどうかを確認する必要があります。
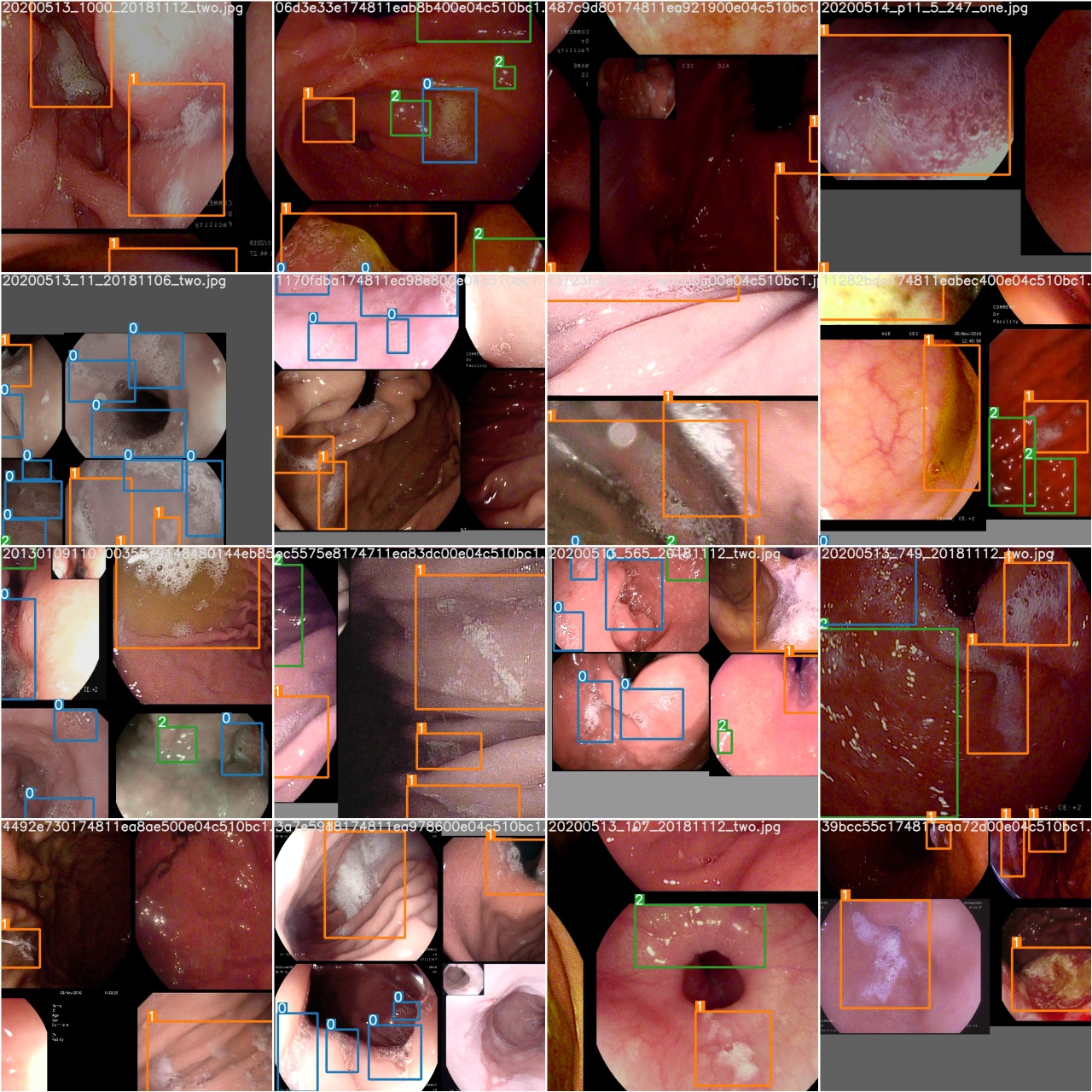
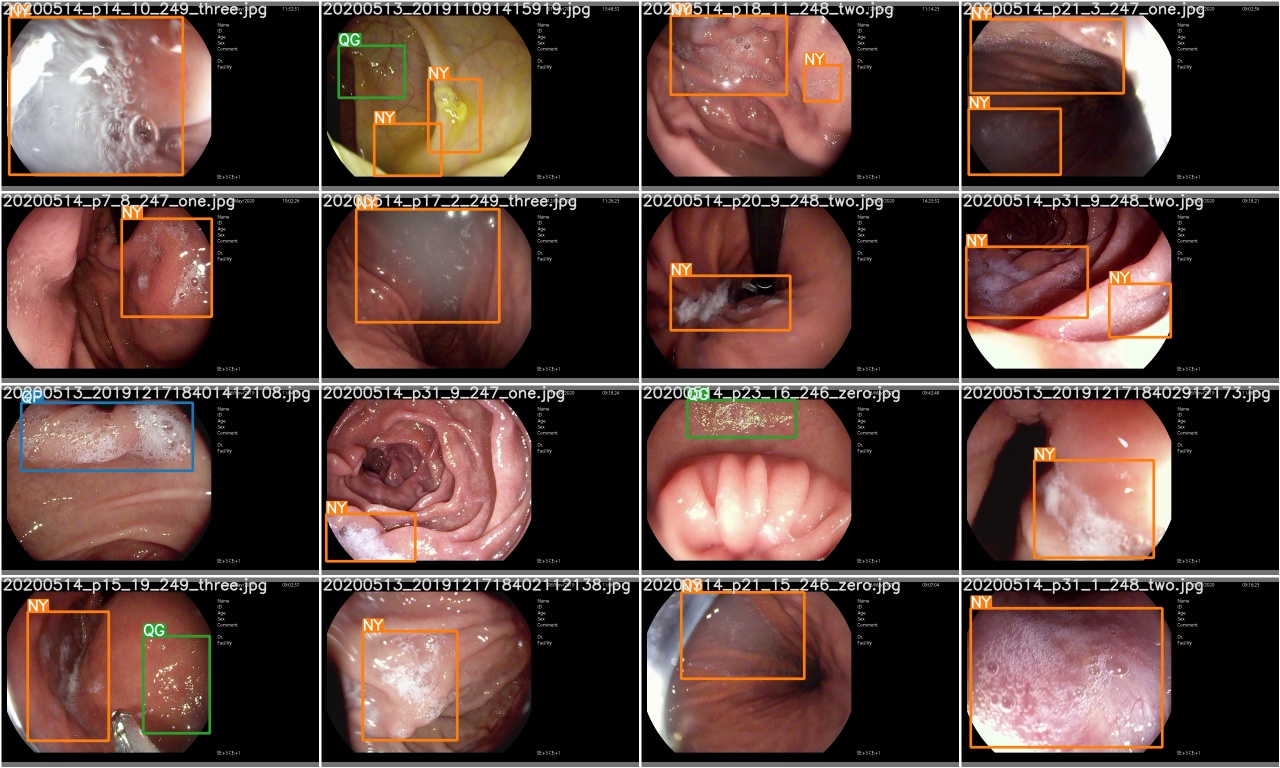
トレーニングエポックが完了した後、 test_batch0_gt.jpgをチェックしてバッチ0グラウンドトゥルースのラベルを確認します
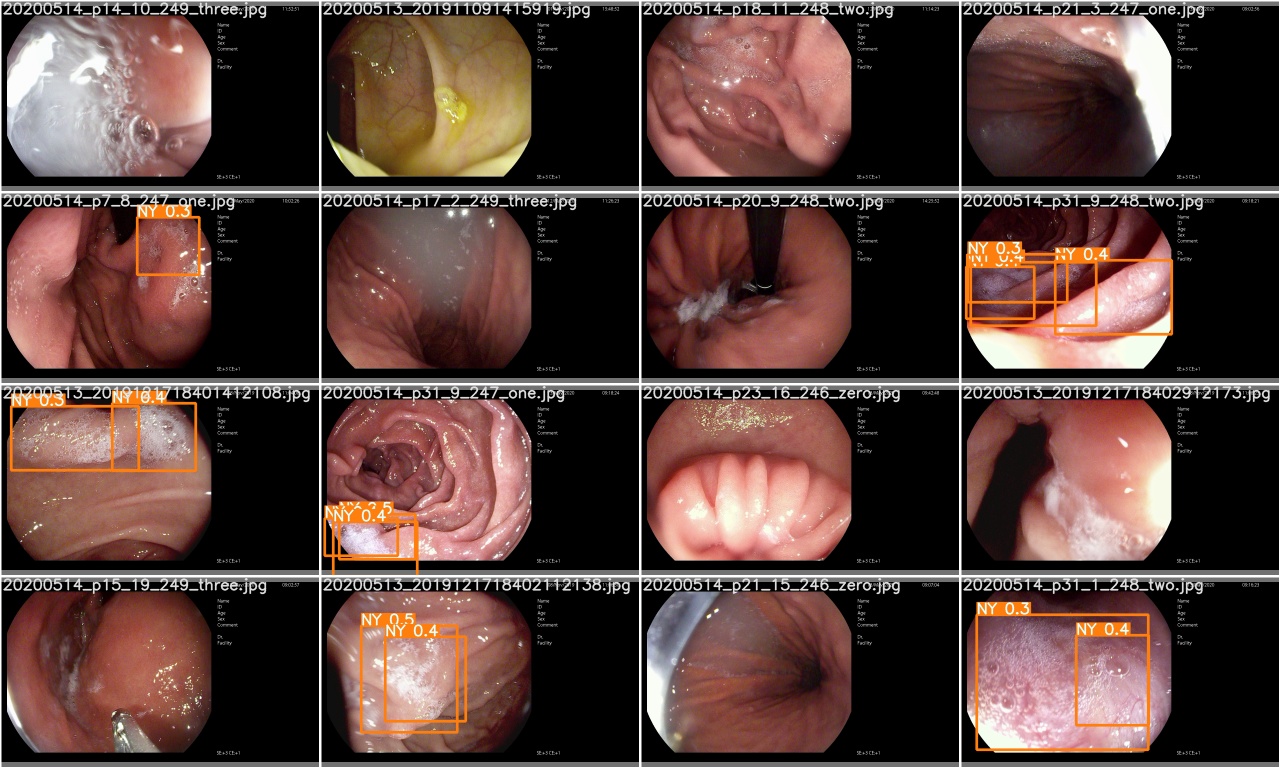
test_batch0_pred.jpgを確認して、テストバッチの予測を確認します0
トレーニングの損失と評価メトリックは、Tensorboardとresults.txtログファイルに保存されます。 results.txt results.pngとして視覚化されますトレーニングが終了した後
> >> from utils . utils import plot_results
> >> plot_results ()
# 如果你是用远程连接请安装配置Xming: https://blog.csdn.net/akuoma/article/details/82182913 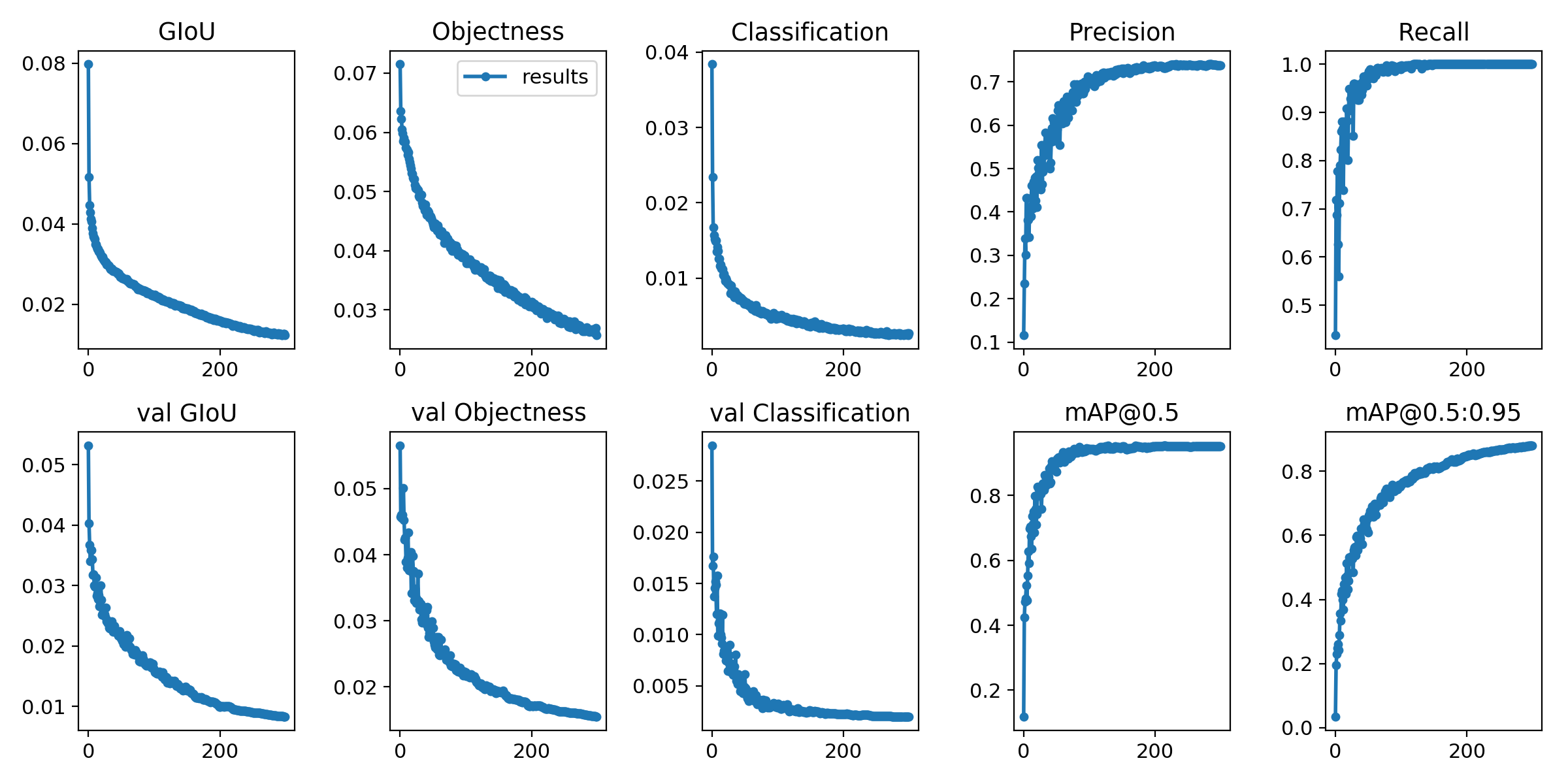
$ python3 detect . py - - source file . jpg # image
file . mp4 # video
. / dir # directory
0 # webcam
rtsp : // 170.93 . 143.139 / rtplive / 470011e600 ef003a004ee33696235daa # rtsp stream
http : // 112.50 . 243.8 / PLTV / 88888888 / 224 / 3221225900 / 1. m3u8 # http stream # inference /home/myuser/xujing/EfficientDet-Pytorch/dataset/test/ 文件夹下的图像
$ python3 detect . py - - source / home / myuser / xujing / EfficientDet - Pytorch / dataset / test / - - weights weights / best . pt - - conf 0.1
$ python3 detect . py - - source . / inference / images / - - weights weights / yolov5x . pt - - conf 0.5
# inference 视频
$ python3 detect . py - - source test . mp4 - - weights weights / yolov5x . pt - - conf 0.4 
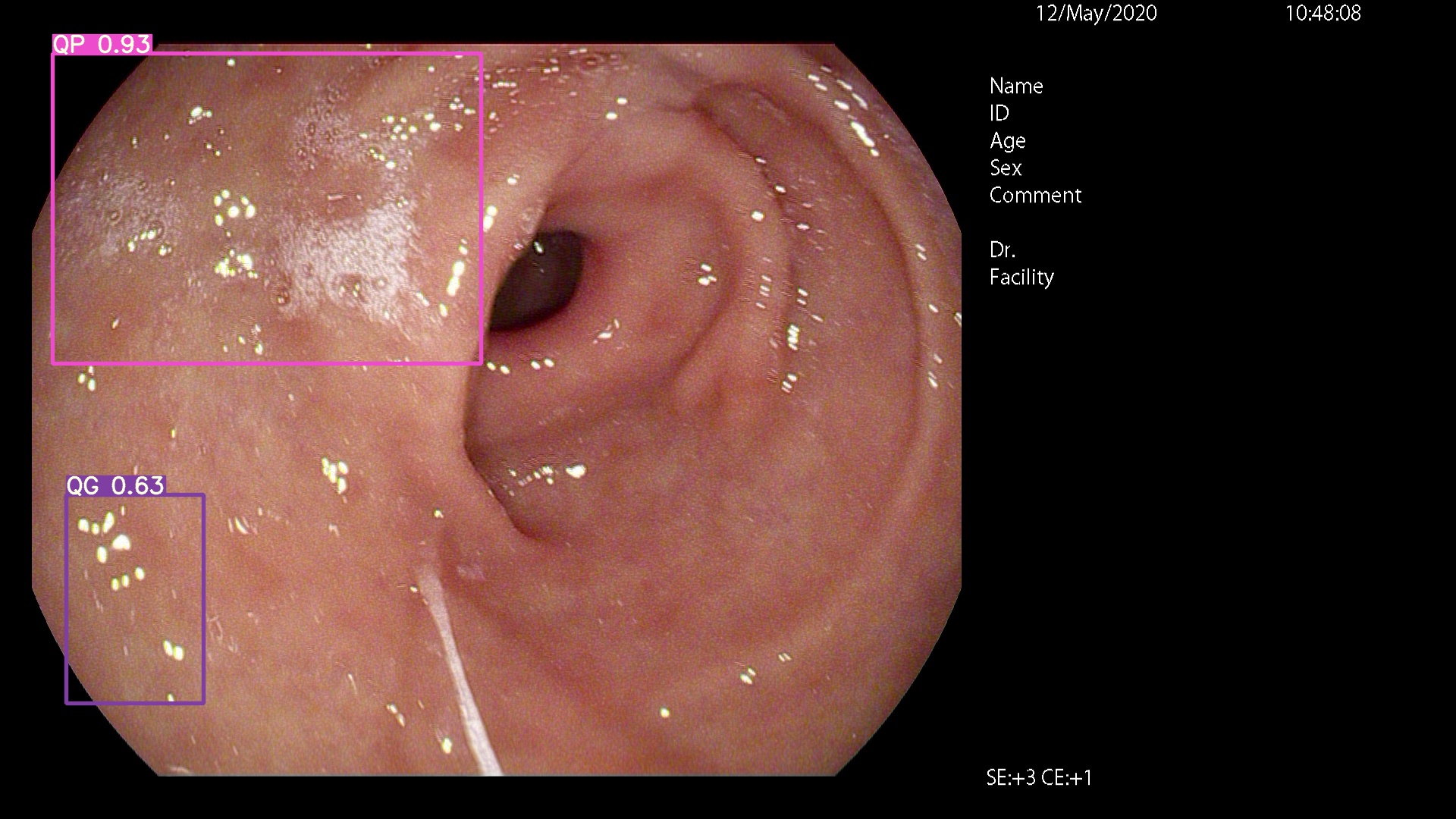
ここに来てください
参照
[1] .https://github.com/ultralytics/yolov5
[2] .https://github.com/ultralytics/yolov5/wiki/train-custom-data


