pytorch widedeep
mps backend support and more rec models
แพ็คเกจที่ยืดหยุ่นสำหรับการเรียนรู้แบบหลายรูปแบบเพื่อรวมข้อมูลตารางกับข้อความและรูปภาพโดยใช้โมเดลที่กว้างและลึกใน Pytorch
เอกสาร: https://pytorch-veredeep.readthedocs.io
โพสต์สหายและบทเรียน: infinitoml
การทดลองและการเปรียบเทียบกับ LightGBM : Tabulardl vs LightGBM
Slack : หากคุณต้องการมีส่วนร่วมหรือเพียงแค่ต้องการแชทกับเราเข้าร่วม Slack
เนื้อหาของเอกสารนี้มีการจัดระเบียบดังนี้:
deeptabularrec pytorch-widedeep ขึ้นอยู่กับอัลกอริทึมที่กว้างและลึกของ Google ซึ่งปรับสำหรับชุดข้อมูลหลายรูปแบบ
โดยทั่วไปแล้ว pytorch-widedeep เป็นแพ็คเกจที่จะใช้การเรียนรู้อย่างลึกซึ้งกับข้อมูลแบบตาราง โดยเฉพาะอย่างยิ่งมีจุดประสงค์เพื่ออำนวยความสะดวกในการรวมกันของข้อความและรูปภาพกับข้อมูลตารางที่สอดคล้องกันโดยใช้แบบจำลองที่กว้างและลึก โดยที่ในใจมีสถาปัตยกรรมจำนวนมากที่สามารถนำไปใช้กับห้องสมุด องค์ประกอบหลักของสถาปัตยกรรมเหล่านั้นแสดงในรูปด้านล่าง:
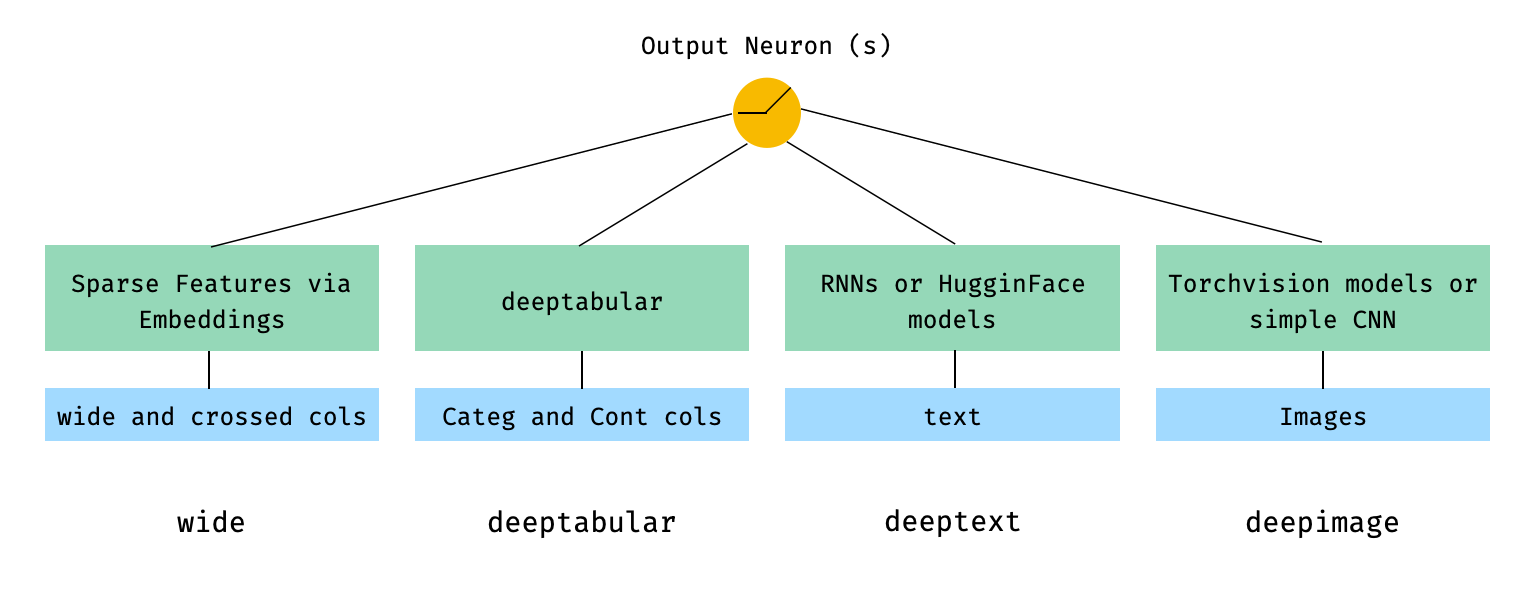
ในแง่ของคณิตศาสตร์และการติดตามสัญลักษณ์ในกระดาษการแสดงออกของสถาปัตยกรรมที่ไม่มีส่วนประกอบ deephead สามารถกำหนดเป็น:
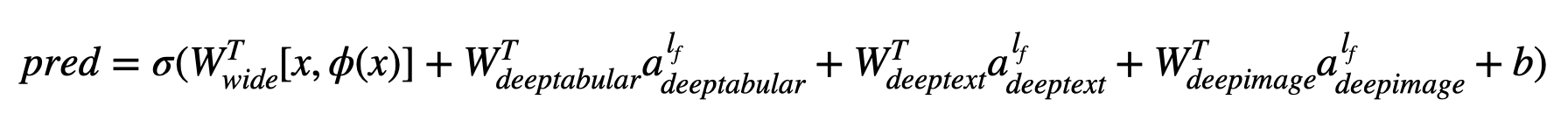
โดยที่σคือฟังก์ชั่น sigmoid 'w' เป็นเมทริกซ์น้ำหนักที่ใช้กับโมเดลกว้างและการเปิดใช้งานขั้นสุดท้ายของแบบจำลองลึก 'a' คือการเปิดใช้งานสุดท้ายเหล่านี้φ (x) คือการแปลงผลิตภัณฑ์ข้ามของคุณสมบัติดั้งเดิม 'x' และและ 'B' เป็นคำอคติ ในกรณีที่คุณสงสัยว่าอะไรคือ "การแปลงผลิตภัณฑ์ข้าม" นี่คือคำพูดที่นำมาโดยตรงจากกระดาษ: "สำหรับคุณสมบัติไบนารีการเปลี่ยนแปลงข้ามผลิตภัณฑ์ (เช่น" และ (เพศ = หญิง, ภาษา = en) ") คือ 1 ถ้าคุณลักษณะที่เป็นส่วนประกอบ (" เพศหญิง "และ" ภาษา = en ")
เป็นไปได้อย่างสมบูรณ์แบบที่จะใช้โมเดลที่กำหนดเอง (และไม่จำเป็นต้องใช้ในไลบรารี) ตราบใดที่โมเดลที่กำหนดเองมีคุณสมบัติที่เรียกว่า output_dim ที่มีขนาดของเลเยอร์สุดท้ายของการเปิดใช้งานเพื่อให้สามารถสร้าง WideDeep ได้ ตัวอย่างเกี่ยวกับวิธีการใช้ส่วนประกอบที่กำหนดเองสามารถพบได้ในโฟลเดอร์ตัวอย่างและส่วนด้านล่าง
ห้องสมุด pytorch-widedeep มีสถาปัตยกรรมที่แตกต่างกันจำนวนมาก ในส่วนนี้เราจะแสดงบางส่วนของพวกเขาในรูปแบบที่ง่ายที่สุดของพวกเขา (เช่นที่มีค่าพารามิเตอร์เริ่มต้นในกรณีส่วนใหญ่) ด้วยตัวอย่างโค้ดที่เกี่ยวข้อง โปรดทราบว่าตัวอย่าง ทั้งหมด ด้านล่าง Shoud Run ในพื้นที่ สำหรับคำอธิบายโดยละเอียดเพิ่มเติมเกี่ยวกับส่วนประกอบที่แตกต่างกันและพารามิเตอร์ของพวกเขาโปรดดูเอกสารประกอบ
สำหรับตัวอย่างด้านล่างเราจะใช้ชุดข้อมูลของเล่นที่สร้างขึ้นดังนี้:
import os
import random
import numpy as np
import pandas as pd
from PIL import Image
from faker import Faker
def create_and_save_random_image ( image_number , size = ( 32 , 32 )):
if not os . path . exists ( "images" ):
os . makedirs ( "images" )
array = np . random . randint ( 0 , 256 , ( size [ 0 ], size [ 1 ], 3 ), dtype = np . uint8 )
image = Image . fromarray ( array )
image_name = f"image_ { image_number } .png"
image . save ( os . path . join ( "images" , image_name ))
return image_name
fake = Faker ()
cities = [ "New York" , "Los Angeles" , "Chicago" , "Houston" ]
names = [ "Alice" , "Bob" , "Charlie" , "David" , "Eva" ]
data = {
"city" : [ random . choice ( cities ) for _ in range ( 100 )],
"name" : [ random . choice ( names ) for _ in range ( 100 )],
"age" : [ random . uniform ( 18 , 70 ) for _ in range ( 100 )],
"height" : [ random . uniform ( 150 , 200 ) for _ in range ( 100 )],
"sentence" : [ fake . sentence () for _ in range ( 100 )],
"other_sentence" : [ fake . sentence () for _ in range ( 100 )],
"image_name" : [ create_and_save_random_image ( i ) for i in range ( 100 )],
"target" : [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )],
}
df = pd . DataFrame ( data ) สิ่งนี้จะสร้าง dataframe 100 แถวและ DIR ในโฟลเดอร์ท้องถิ่นของคุณที่เรียกว่า images ด้วยภาพสุ่ม 100 ภาพ (หรือรูปภาพที่มีสัญญาณรบกวนเพียง)
บางทีสถาปัตยกรรมที่ง่ายที่สุดอาจเป็นเพียงองค์ประกอบเดียว wide , deeptabular , deeptext หรือ deepimage ด้วยตัวเองซึ่งเป็นไปได้เช่นกัน แต่เรามาเริ่มต้นตัวอย่างด้วยสถาปัตยกรรมที่กว้างและลึกมาตรฐาน จากนั้นวิธีการสร้างโมเดลประกอบด้วยองค์ประกอบเดียวเท่านั้นที่จะตรงไปตรงมา
โปรดทราบว่าตัวอย่างที่แสดงด้านล่างเกือบจะเหมือนกันโดยใช้โมเดลใด ๆ ที่มีอยู่ในห้องสมุด ตัวอย่างเช่น TabMlp สามารถแทนที่ด้วย TabResnet , TabNet , TabTransformer ฯลฯ ในทำนองเดียวกันสามารถแทนที่ BasicRNN ได้ด้วย AttentiveRNN , StackedAttentiveRNN หรือ HFModel ด้วยพารามิเตอร์ที่เกี่ยวข้องและ preprocessor ในกรณีของแบบจำลองใบหน้ากอด
1. ส่วนประกอบกว้างและตาราง (aka deeptabular)
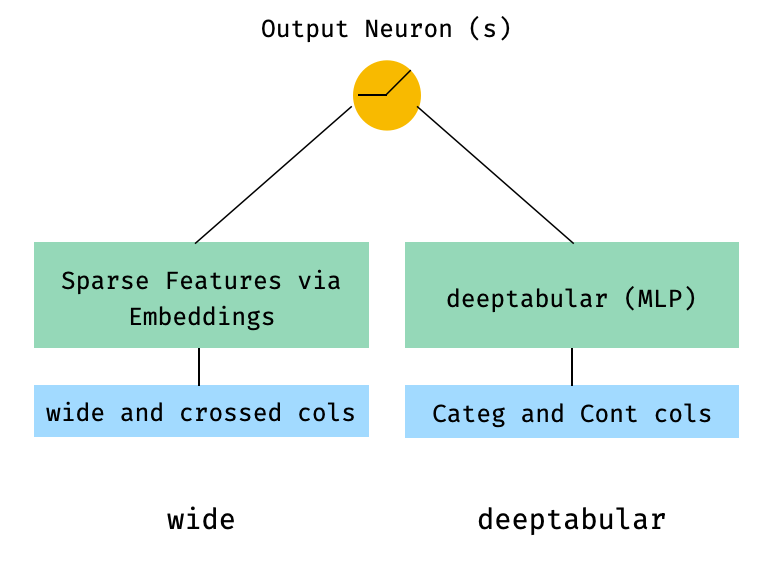
from pytorch_widedeep . preprocessing import TabPreprocessor , WidePreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . training import Trainer
# Wide
wide_cols = [ "city" ]
crossed_cols = [( "city" , "name" )]
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df )
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ])
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# WideDeep
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)2. ข้อมูลตารางและข้อความ
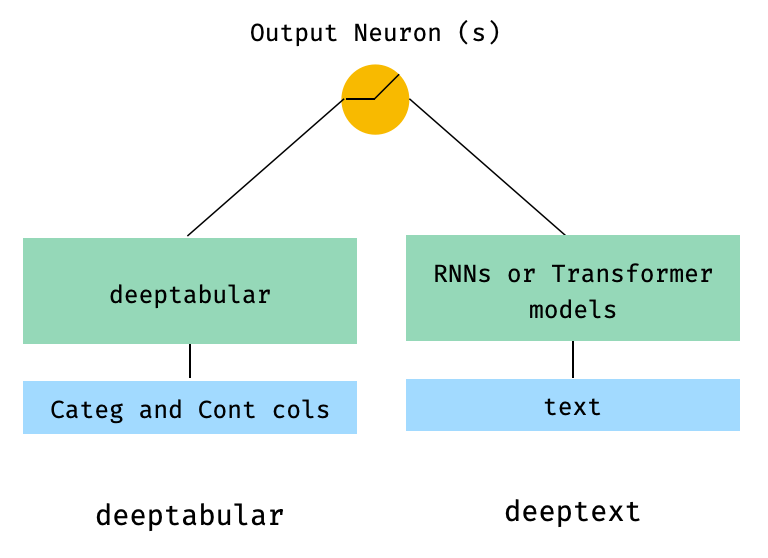
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 3. ตารางและข้อความที่มีหัว FC อยู่ด้านบนผ่านพารามิเตอร์ head_hidden_dims ใน WideDeep
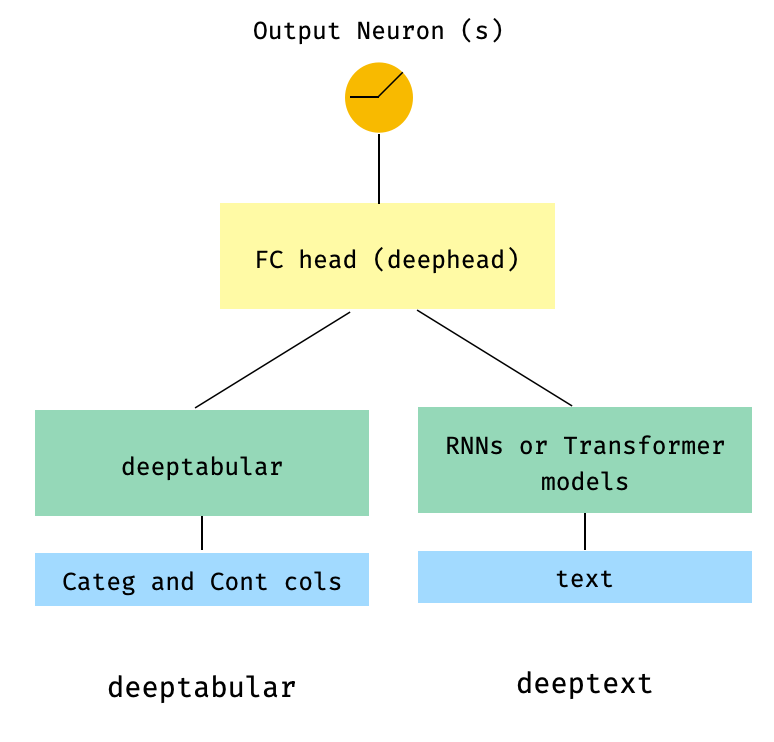
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn , head_hidden_dims = [ 32 , 16 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 4. คอลัมน์แบบตารางและหลายคอลัมน์ที่ส่งผ่านไปยัง WideDeep โดยตรง
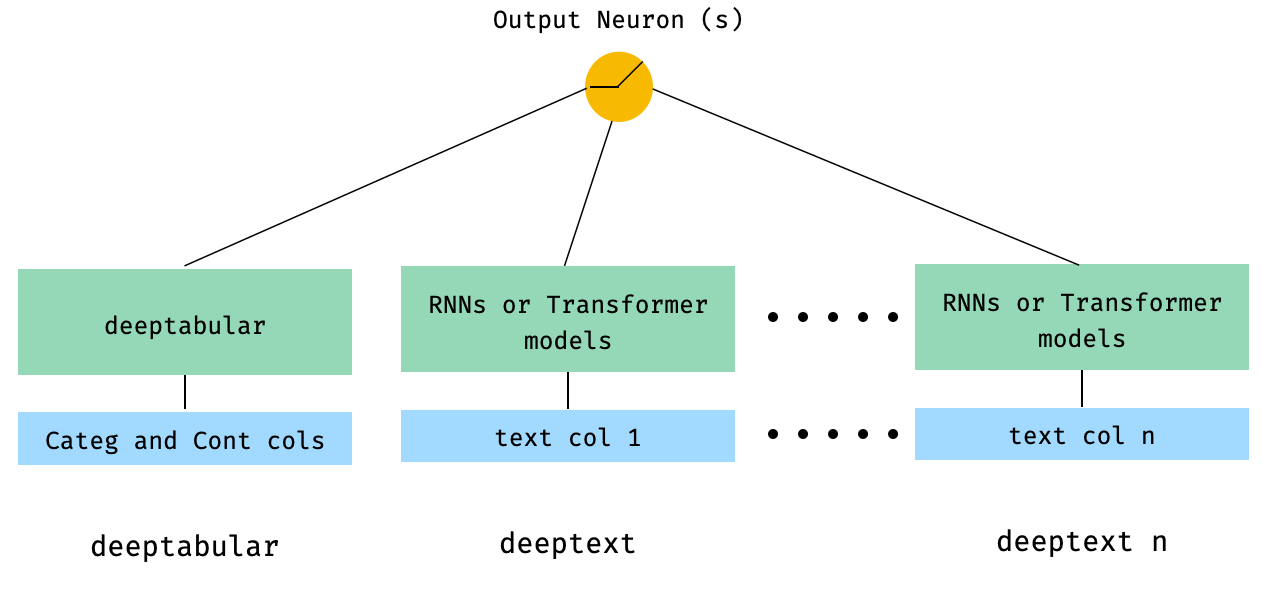
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = [ rnn_1 , rnn_2 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 5. ข้อมูลแบบตารางและคอลัมน์ข้อความหลายคอลัมน์ที่หลอมรวมผ่านคลาส ModelFuser ของไลบรารี
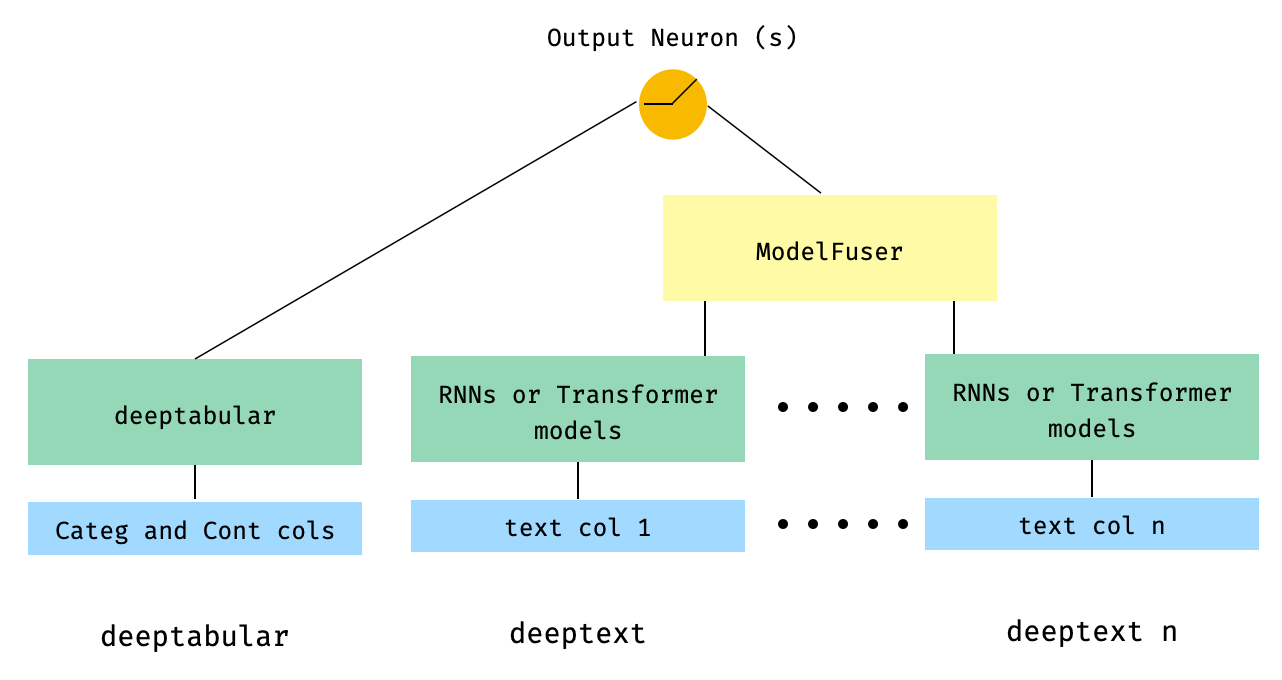
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser ( models = [ rnn_1 , rnn_2 ], fusion_method = "mult" )
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = models_fuser )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
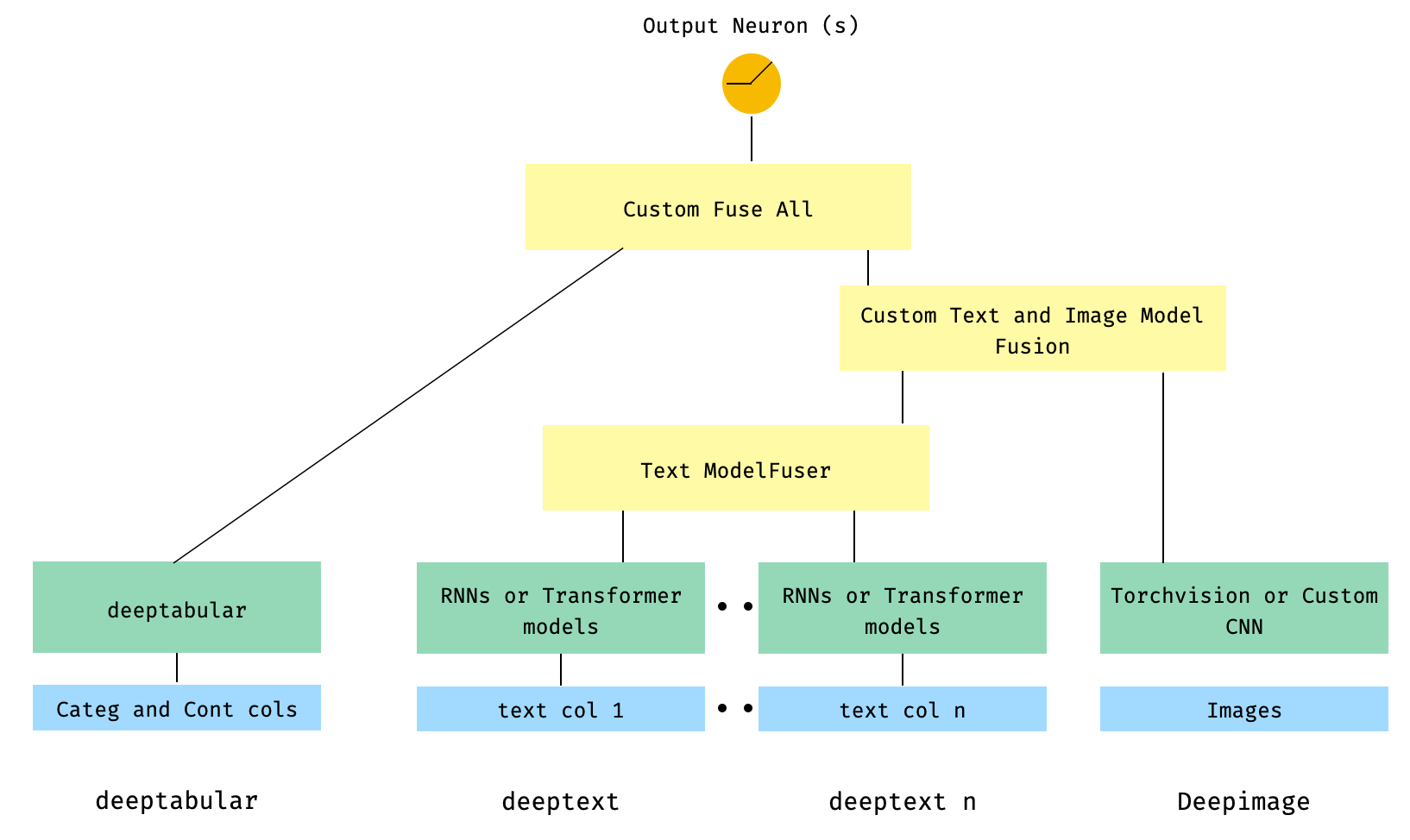
) 6. คอลัมน์แบบตารางและหลายคอลัมน์พร้อมคอลัมน์รูปภาพ คอลัมน์ข้อความจะถูกหลอมรวมผ่าน ModelFuser ของห้องสมุดจากนั้นทั้งหมดจะถูกหลอมรวมผ่านผู้ดูแล Deephead ใน WideDeep ซึ่งเป็น ModelFuser แบบกำหนดเองที่รหัสโดยผู้ใช้
นี่อาจเป็นโซลูชันที่สง่างามน้อยกว่าเนื่องจากเกี่ยวข้องกับองค์ประกอบที่กำหนดเองโดยผู้ใช้และแบ่งเทนเซอร์ 'เข้ามา' ในอนาคตเราจะรวม TextAndImageModelFuser เพื่อให้กระบวนการนี้ตรงไปตรงมามากขึ้น ถึงกระนั้นก็ยังไม่ซับซ้อนจริงๆและเป็นตัวอย่างที่ดีของวิธีการใช้ส่วนประกอบที่กำหนดเองใน pytorch-widedeep
โปรดทราบว่าข้อกำหนดเพียงอย่างเดียวสำหรับส่วนประกอบที่กำหนดเองคือมันมีคุณสมบัติที่เรียกว่า output_dim ที่ส่งคืนขนาดของการเปิดใช้งานเลเยอร์สุดท้าย กล่าวอีกนัยหนึ่งไม่จำเป็นต้องสืบทอดจาก BaseWDModelComponent คลาสฐานนี้เพียงตรวจสอบการมีอยู่ของคุณสมบัติดังกล่าวและหลีกเลี่ยงข้อผิดพลาดการพิมพ์บางอย่างภายใน
import torch
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 16 , 8 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser (
models = [ rnn_1 , rnn_2 ],
fusion_method = "mult" ,
)
# Image
image_preprocessor = ImagePreprocessor ( img_col = "image_name" , img_path = "images" )
X_img = image_preprocessor . fit_transform ( df )
vision = Vision ( pretrained_model_setup = "resnet18" , head_hidden_dims = [ 16 , 8 ])
# deephead (custom model fuser)
class MyModelFuser ( BaseWDModelComponent ):
"""
Simply a Linear + Relu sequence on top of the text + images followed by a
Linear -> Relu -> Linear for the concatenation of tabular slice of the
tensor and the output of the text and image sequential model
"""
def __init__ (
self ,
tab_incoming_dim : int ,
text_incoming_dim : int ,
image_incoming_dim : int ,
output_units : int ,
):
super ( MyModelFuser , self ). __init__ ()
self . tab_incoming_dim = tab_incoming_dim
self . text_incoming_dim = text_incoming_dim
self . image_incoming_dim = image_incoming_dim
self . output_units = output_units
self . text_and_image_fuser = torch . nn . Sequential (
torch . nn . Linear ( text_incoming_dim + image_incoming_dim , output_units ),
torch . nn . ReLU (),
)
self . out = torch . nn . Sequential (
torch . nn . Linear ( output_units + tab_incoming_dim , output_units * 4 ),
torch . nn . ReLU (),
torch . nn . Linear ( output_units * 4 , output_units ),
)
def forward ( self , X : torch . Tensor ) -> torch . Tensor :
tab_slice = slice ( 0 , self . tab_incoming_dim )
text_slice = slice (
self . tab_incoming_dim , self . tab_incoming_dim + self . text_incoming_dim
)
image_slice = slice (
self . tab_incoming_dim + self . text_incoming_dim ,
self . tab_incoming_dim + self . text_incoming_dim + self . image_incoming_dim ,
)
X_tab = X [:, tab_slice ]
X_text = X [:, text_slice ]
X_img = X [:, image_slice ]
X_text_and_image = self . text_and_image_fuser ( torch . cat ([ X_text , X_img ], dim = 1 ))
return self . out ( torch . cat ([ X_tab , X_text_and_image ], dim = 1 ))
@ property
def output_dim ( self ):
return self . output_units
deephead = MyModelFuser (
tab_incoming_dim = tab_mlp . output_dim ,
text_incoming_dim = models_fuser . output_dim ,
image_incoming_dim = vision . output_dim ,
output_units = 8 ,
)
# WideDeep
model = WideDeep (
deeptabular = tab_mlp ,
deeptext = models_fuser ,
deepimage = vision ,
deephead = deephead ,
)
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
X_img = X_img ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)7. รุ่นสองหอ
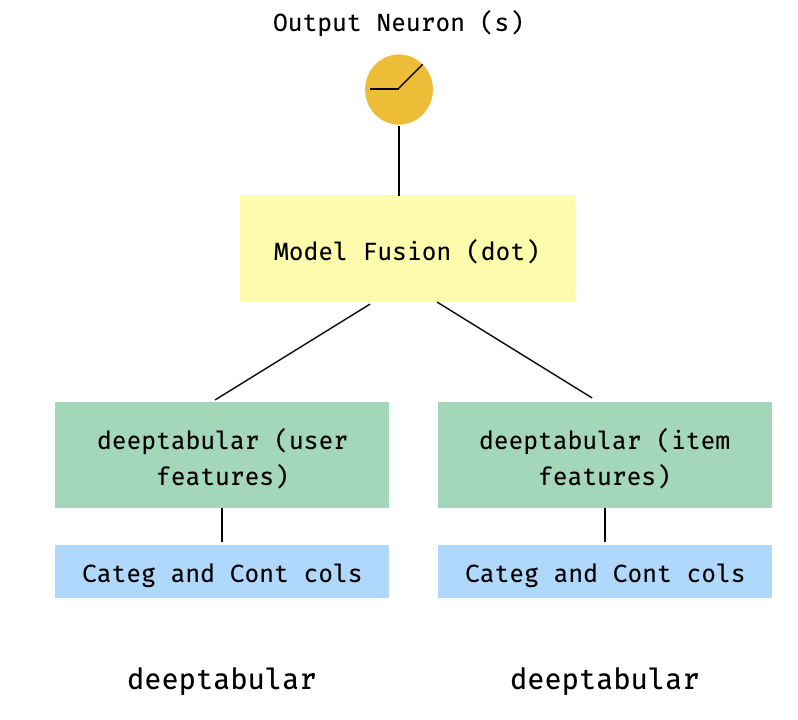
นี่เป็นรูปแบบยอดนิยมในบริบทของระบบแนะนำ สมมติว่าเรามีชุดข้อมูลแบบตารางสร้างอเนกประสงค์ของฉัน (คุณสมบัติผู้ใช้คุณสมบัติรายการเป้าหมาย) เราสามารถสร้างโมเดลสองหอซึ่งคุณสมบัติของผู้ใช้และรายการจะถูกส่งผ่านสองรุ่นแยกต่างหากจากนั้น "หลอมรวม" ผ่านผลิตภัณฑ์ DOT
import numpy as np
import pandas as pd
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import TabPreprocessor
from pytorch_widedeep . models import TabMlp , WideDeep , ModelFuser
# Let's create the interaction dataset
# user_features dataframe
np . random . seed ( 42 )
user_ids = np . arange ( 1 , 101 )
ages = np . random . randint ( 18 , 60 , size = 100 )
genders = np . random . choice ([ "male" , "female" ], size = 100 )
locations = np . random . choice ([ "city_a" , "city_b" , "city_c" , "city_d" ], size = 100 )
user_features = pd . DataFrame (
{ "id" : user_ids , "age" : ages , "gender" : genders , "location" : locations }
)
# item_features dataframe
item_ids = np . arange ( 1 , 101 )
prices = np . random . uniform ( 10 , 500 , size = 100 ). round ( 2 )
colors = np . random . choice ([ "red" , "blue" , "green" , "black" ], size = 100 )
categories = np . random . choice ([ "electronics" , "clothing" , "home" , "toys" ], size = 100 )
item_features = pd . DataFrame (
{ "id" : item_ids , "price" : prices , "color" : colors , "category" : categories }
)
# Interactions dataframe
interaction_user_ids = np . random . choice ( user_ids , size = 1000 )
interaction_item_ids = np . random . choice ( item_ids , size = 1000 )
purchased = np . random . choice ([ 0 , 1 ], size = 1000 , p = [ 0.7 , 0.3 ])
interactions = pd . DataFrame (
{
"user_id" : interaction_user_ids ,
"item_id" : interaction_item_ids ,
"purchased" : purchased ,
}
)
user_item_purchased = interactions . merge (
user_features , left_on = "user_id" , right_on = "id"
). merge ( item_features , left_on = "item_id" , right_on = "id" )
# Users
tab_preprocessor_user = TabPreprocessor (
cat_embed_cols = [ "gender" , "location" ],
continuous_cols = [ "age" ],
)
X_user = tab_preprocessor_user . fit_transform ( user_item_purchased )
tab_mlp_user = TabMlp (
column_idx = tab_preprocessor_user . column_idx ,
cat_embed_input = tab_preprocessor_user . cat_embed_input ,
continuous_cols = [ "age" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
# Items
tab_preprocessor_item = TabPreprocessor (
cat_embed_cols = [ "color" , "category" ],
continuous_cols = [ "price" ],
)
X_item = tab_preprocessor_item . fit_transform ( user_item_purchased )
tab_mlp_item = TabMlp (
column_idx = tab_preprocessor_item . column_idx ,
cat_embed_input = tab_preprocessor_item . cat_embed_input ,
continuous_cols = [ "price" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
two_tower_model = ModelFuser ([ tab_mlp_user , tab_mlp_item ], fusion_method = "dot" )
model = WideDeep ( deeptabular = two_tower_model )
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = [ X_user , X_item ],
target = interactions . purchased . values ,
n_epochs = 1 ,
batch_size = 32 ,
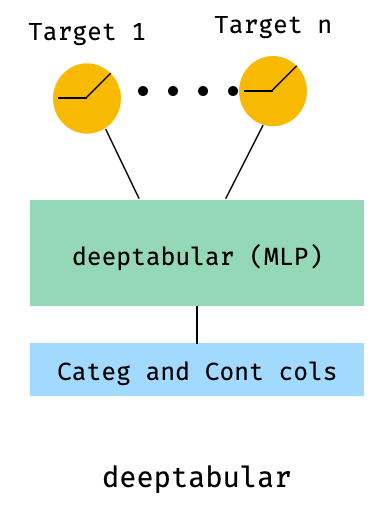
)8. ตารางที่มีการสูญเสียหลายเป้าหมาย
อันนี้คือ "โบนัส" เพื่อแสดงให้เห็นถึงการใช้การสูญเสียหลายเป้าหมายมากกว่าสถาปัตยกรรมที่แตกต่างกัน
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . losses_multitarget import MultiTargetClassificationLoss
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# let's add a second target to the dataframe
df [ "target2" ] = [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )]
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# 'pred_dim=2' because we have two binary targets. For other types of targets,
# please, see the documentation
model = WideDeep ( deeptabular = tab_mlp , pred_dim = 2 ).
loss = MultiTargetClassificationLoss ( binary_config = [ 0 , 1 ], reduction = "mean" )
# When a multi-target loss is used, 'custom_loss_function' must not be None.
# See the docs
trainer = Trainer ( model , objective = "multitarget" , custom_loss_function = loss )
trainer . fit (
X_tab = X_tab ,
target = df [[ "target" , "target2" ]]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)deeptabular มันเป็นสิ่งสำคัญที่จะเน้นอีกครั้งว่า แต่ละองค์ประกอบ wide , deeptabular , deeptext และ deepimage สามารถใช้อย่างอิสระ และแยกออกจากกัน ตัวอย่างเช่นหนึ่งสามารถใช้ wide เท่านั้นซึ่งเป็นเพียงแบบจำลองเชิงเส้น ในความเป็นจริงหนึ่งในฟังก์ชั่นที่น่าสนใจที่สุดใน pytorch-widedeep คือการใช้องค์ประกอบ deeptabular ด้วยตัวเองเช่นสิ่งที่คน ๆ หนึ่งอาจอ้างถึงการเรียนรู้อย่างลึกซึ้งสำหรับข้อมูลตาราง ปัจจุบัน pytorch-widedeep เสนอรุ่นที่แตกต่างกันต่อไปนี้สำหรับส่วนประกอบนั้น:
สองรุ่นที่ใช้ความสนใจง่ายกว่าที่เราเรียกว่า:
ตระกูล Tabformer เช่น Transformers สำหรับข้อมูลตาราง:
และโมเดล DL ที่น่าจะเป็นสำหรับข้อมูลตารางตามความไม่แน่นอนของน้ำหนักในเครือข่ายประสาท:
WideTabMlpโปรดทราบว่าในขณะที่มีสิ่งพิมพ์ทางวิทยาศาสตร์สำหรับ tabtransformer, Saint และ FT-transformer, tabfasfformer และ tabperceiver เป็นการปรับอัลกอริทึมของเราเองสำหรับข้อมูลตาราง
นอกจากนี้การฝึกอบรมก่อนการดูแลตนเองสามารถใช้สำหรับแบบจำลอง deeptabular ทั้งหมดยกเว้น TabPerceiver การฝึกอบรมก่อนการดูแลตนเองสามารถใช้งานได้ผ่านสองวิธีหรือกิจวัตรที่เราอ้างถึงเป็น: วิธีการเข้ารหัสและวิธีการกำหนดข้อ จำกัด โปรดดูเอกสารและตัวอย่างสำหรับรายละเอียดเกี่ยวกับฟังก์ชั่นนี้และตัวเลือกอื่น ๆ ทั้งหมดในห้องสมุด
recโมดูลนี้ได้รับการแนะนำเป็นส่วนขยายไปยังส่วนประกอบที่มีอยู่ในห้องสมุดตอบคำถามและปัญหาที่เกี่ยวข้องกับระบบแนะนำ ในขณะที่ยังอยู่ภายใต้การพัฒนาที่ใช้งานอยู่ในปัจจุบันมีจำนวนรูปแบบการแนะนำที่มีประสิทธิภาพเลือก
เป็นที่น่าสังเกตว่าห้องสมุดนี้สนับสนุนการใช้อัลกอริธึมคำแนะนำที่หลากหลายแล้วโดยใช้ส่วนประกอบที่มีอยู่แล้ว ตัวอย่างเช่นแบบจำลองเช่นการกรองแบบกว้างและลึกสองหอหรือการกรองความร่วมมือทางประสาทสามารถสร้างขึ้นได้โดยใช้ฟังก์ชันหลักของห้องสมุด
อัลกอริทึมคำแนะนำในโมดูล rec คือ:
ดูตัวอย่างสำหรับรายละเอียดเกี่ยวกับวิธีการใช้โมเดลเหล่านี้
สำหรับส่วนประกอบข้อความ deeptext ไลบรารีเสนอรุ่นต่อไปนี้:
สำหรับส่วนประกอบของภาพ deepimage ห้องสมุดรองรับโมเดลจากครอบครัวต่อไปนี้: 'resnet', 'shufflenet', 'resnext', 'wide_resnet', 'regnet', 'densenet', 'mobilenetv3', 'mobilenetv2', 'mnasnet' สิ่งเหล่านี้มีให้ผ่าน torchvision และห่อหุ้มในชั้นเรียน Vision
ติดตั้งโดยใช้ PIP:
pip install pytorch-widedeepหรือติดตั้งโดยตรงจาก gitHub
pip install git+https://github.com/jrzaurin/pytorch-widedeep.git # Clone the repository
git clone https://github.com/jrzaurin/pytorch-widedeep
cd pytorch-widedeep
# Install in dev mode
pip install -e . นี่คือตัวอย่างแบบ end-to-end ของการจำแนกไบนารีกับชุดข้อมูลสำหรับผู้ใหญ่โดยใช้การตั้งค่า Wide และ DeepDense และเริ่มต้น
การสร้างแบบกว้าง (เชิงเส้น) และแบบจำลองลึกด้วย pytorch-widedeep :
import numpy as np
import torch
from sklearn . model_selection import train_test_split
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import WidePreprocessor , TabPreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . metrics import Accuracy
from pytorch_widedeep . datasets import load_adult
df = load_adult ( as_frame = True )
df [ "income_label" ] = ( df [ "income" ]. apply ( lambda x : ">50K" in x )). astype ( int )
df . drop ( "income" , axis = 1 , inplace = True )
df_train , df_test = train_test_split ( df , test_size = 0.2 , stratify = df . income_label )
# Define the 'column set up'
wide_cols = [
"education" ,
"relationship" ,
"workclass" ,
"occupation" ,
"native-country" ,
"gender" ,
]
crossed_cols = [( "education" , "occupation" ), ( "native-country" , "occupation" )]
cat_embed_cols = [
"workclass" ,
"education" ,
"marital-status" ,
"occupation" ,
"relationship" ,
"race" ,
"gender" ,
"capital-gain" ,
"capital-loss" ,
"native-country" ,
]
continuous_cols = [ "age" , "hours-per-week" ]
target = "income_label"
target = df_train [ target ]. values
# prepare the data
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df_train )
tab_preprocessor = TabPreprocessor (
cat_embed_cols = cat_embed_cols , continuous_cols = continuous_cols # type: ignore[arg-type]
)
X_tab = tab_preprocessor . fit_transform ( df_train )
# build the model
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ], pred_dim = 1 )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = continuous_cols ,
)
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# train and validate
trainer = Trainer ( model , objective = "binary" , metrics = [ Accuracy ])
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = target ,
n_epochs = 5 ,
batch_size = 256 ,
)
# predict on test
X_wide_te = wide_preprocessor . transform ( df_test )
X_tab_te = tab_preprocessor . transform ( df_test )
preds = trainer . predict ( X_wide = X_wide_te , X_tab = X_tab_te )
# Save and load
# Option 1: this will also save training history and lr history if the
# LRHistory callback is used
trainer . save ( path = "model_weights" , save_state_dict = True )
# Option 2: save as any other torch model
torch . save ( model . state_dict (), "model_weights/wd_model.pt" )
# From here in advance, Option 1 or 2 are the same. I assume the user has
# prepared the data and defined the new model components:
# 1. Build the model
model_new = WideDeep ( wide = wide , deeptabular = tab_mlp )
model_new . load_state_dict ( torch . load ( "model_weights/wd_model.pt" ))
# 2. Instantiate the trainer
trainer_new = Trainer ( model_new , objective = "binary" )
# 3. Either start the fit or directly predict
preds = trainer_new . predict ( X_wide = X_wide , X_tab = X_tab , batch_size = 32 )แน่นอนว่าเราสามารถทำอะไร ได้มากกว่านี้ ดูโฟลเดอร์ตัวอย่างเอกสารหรือโพสต์สหายเพื่อความเข้าใจที่ดีขึ้นเกี่ยวกับเนื้อหาของแพ็คเกจและฟังก์ชันการทำงาน
pytest tests
ตรวจสอบหน้าการบริจาค
ห้องสมุดนี้มาจากชุดของห้องสมุดอื่น ๆ ดังนั้นฉันคิดว่ามันยุติธรรมที่จะพูดถึงพวกเขาที่นี่ใน readMe (การกล่าวถึงเฉพาะรวมอยู่ในรหัส)
โครงสร้าง Callbacks และ Initializers และรหัสได้รับแรงบันดาลใจจากห้องสมุด torchsample ซึ่งเป็นแรงบันดาลใจบางส่วนจาก Keras
คลาส TextProcessor ในไลบรารีนี้ใช้ Tokenizer และ Vocab ของ fastai รหัสที่ utils.fastai_transforms เป็นการปรับตัวเล็กน้อยของรหัสของพวกเขาดังนั้นจึงใช้งานได้ภายในไลบรารีนี้ จากประสบการณ์ของฉัน Tokenizer ของพวกเขานั้นดีที่สุดในชั้นเรียน
คลาส ImageProcessor ในห้องสมุดนี้ใช้รหัสจากการเรียนรู้ที่ลึกล้ำสำหรับการมองเห็นคอมพิวเตอร์ (DL4CV) โดย Adrian Rosebrock
งานนี้ได้รับใบอนุญาตคู่ภายใต้ Apache 2.0 และ MIT (หรือเวอร์ชันใหม่ ๆ ) คุณสามารถเลือกระหว่างหนึ่งในนั้นหากคุณใช้งานนี้
SPDX-License-Identifier: Apache-2.0 AND MIT
@article{Zaurin_pytorch-widedeep_A_flexible_2023,
author = {Zaurin, Javier Rodriguez and Mulinka, Pavol},
doi = {10.21105/joss.05027},
journal = {Journal of Open Source Software},
month = jun,
number = {86},
pages = {5027},
title = {{pytorch-widedeep: A flexible package for multimodal deep learning}},
url = {https://joss.theoj.org/papers/10.21105/joss.05027},
volume = {8},
year = {2023}
}
Zaurin, J. R., & Mulinka, P. (2023). pytorch-widedeep: A flexible package for
multimodal deep learning. Journal of Open Source Software, 8(86), 5027.
https://doi.org/10.21105/joss.05027


