pytorch widedeep
mps backend support and more rec models
Un paquete flexible para el aprendizaje multimodal de profundidad para combinar datos tabulares con texto e imágenes utilizando modelos amplios y profundos en Pytorch
Documentación: https://pytorch-widedeep.readthedocs.io
Publicaciones y tutoriales complementarios: Infinitoml
Experimentos y comparación con LightGBM : Tabulardl vs LightGBM
Slack : si quieres contribuir o simplemente quieres chatear con nosotros, únete a Slack
El contenido de este documento se organiza de la siguiente manera:
deeptabularrec pytorch-widedeep se basa en el algoritmo amplio y profundo de Google, ajustado para conjuntos de datos multimodales.
En términos generales, pytorch-widedeep es un paquete para usar el aprendizaje profundo con datos tabulares. En particular, está destinado a facilitar la combinación de texto e imágenes con datos tabulares correspondientes utilizando modelos amplios y profundos. Con eso en mente, hay una serie de arquitecturas que se pueden implementar con la biblioteca. Los componentes principales de esas arquitecturas se muestran en la figura a continuación:
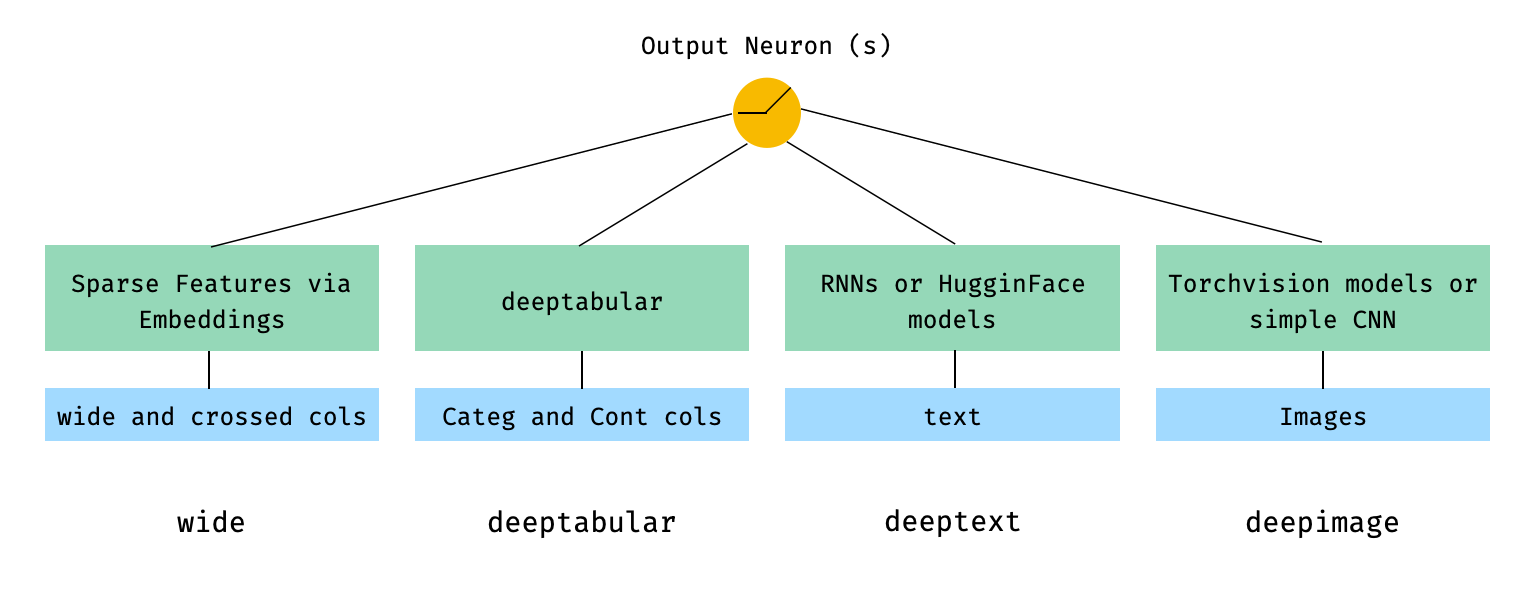
En términos matemáticos, y después de la notación en el documento, la expresión de la arquitectura sin un componente deephead puede formularse como:
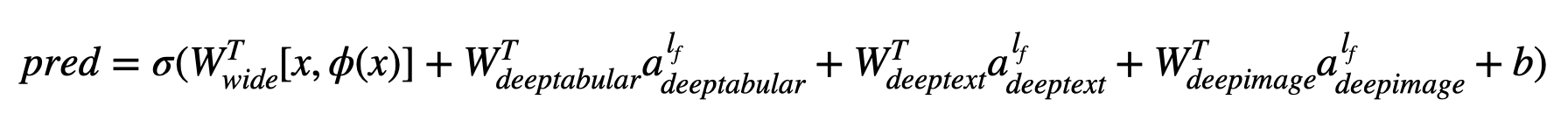
Donde σ es la función sigmoide, 'W' son las matrices de peso aplicadas al modelo amplio y a las activaciones finales de los modelos profundos, 'A' son estas activaciones finales, φ (x) son las transformaciones de productos cruzados de las características originales 'X' , y 'B' es el término de sesgo. En caso de que se pregunte cuáles son las "transformaciones de productos cruzados" , aquí hay una cita tomada directamente del documento: "Para las características binarias, una transformación de productos cruzados (por ejemplo," y (género = femenino, lenguaje = en) ") es 1 si y solo si las características constituyentes (" género = femenino "y" lenguaje = en ") son todos 1 y 0 de otra manera".
Es perfectamente posible usar modelos personalizados (y no necesariamente los de la biblioteca) siempre que los modelos personalizados tengan una propiedad llamada output_dim con el tamaño de la última capa de activaciones, de modo que se pueda construir WideDeep . Se pueden encontrar ejemplos sobre cómo usar componentes personalizados en la carpeta de ejemplos y la sección a continuación.
La biblioteca pytorch-widedeep ofrece una serie de arquitecturas diferentes. En esta sección mostraremos algunos de ellos en su forma más simple (es decir, con valores de parámetro predeterminado en la mayoría de los casos) con sus fragmentos de código correspondientes. Tenga en cuenta que todos los fragmentos a continuación se ejecutan localmente. Para obtener una explicación más detallada de los diferentes componentes y sus parámetros, consulte la documentación.
Para los ejemplos a continuación, utilizaremos un conjunto de datos de juguete generado de la siguiente manera:
import os
import random
import numpy as np
import pandas as pd
from PIL import Image
from faker import Faker
def create_and_save_random_image ( image_number , size = ( 32 , 32 )):
if not os . path . exists ( "images" ):
os . makedirs ( "images" )
array = np . random . randint ( 0 , 256 , ( size [ 0 ], size [ 1 ], 3 ), dtype = np . uint8 )
image = Image . fromarray ( array )
image_name = f"image_ { image_number } .png"
image . save ( os . path . join ( "images" , image_name ))
return image_name
fake = Faker ()
cities = [ "New York" , "Los Angeles" , "Chicago" , "Houston" ]
names = [ "Alice" , "Bob" , "Charlie" , "David" , "Eva" ]
data = {
"city" : [ random . choice ( cities ) for _ in range ( 100 )],
"name" : [ random . choice ( names ) for _ in range ( 100 )],
"age" : [ random . uniform ( 18 , 70 ) for _ in range ( 100 )],
"height" : [ random . uniform ( 150 , 200 ) for _ in range ( 100 )],
"sentence" : [ fake . sentence () for _ in range ( 100 )],
"other_sentence" : [ fake . sentence () for _ in range ( 100 )],
"image_name" : [ create_and_save_random_image ( i ) for i in range ( 100 )],
"target" : [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )],
}
df = pd . DataFrame ( data ) Esto creará un marcador de datos de 100 filas y un Dir en su carpeta local, llamadas images con 100 imágenes aleatorias (o imágenes con solo ruido).
Quizás la arquitectura más simple sería solo un componente, wide , deeptabular , deeptext o deepimage por su cuenta, lo cual también es posible, pero comencemos los ejemplos con una arquitectura amplia y profunda estándar. A partir de ahí, cómo construir un modelo compuesto solo por un componente será sencillo.
Tenga en cuenta que los ejemplos que se muestran a continuación serían casi idénticos utilizando cualquiera de los modelos disponibles en la biblioteca. Por ejemplo, TabMlp se puede reemplazar por TabResnet , TabNet , TabTransformer , etc. De manera similar, BasicRNN puede ser reemplazado por AttentiveRNN , StackedAttentiveRNN o HFModel con sus parámetros y preprocesador correspondientes en el caso de los modelos de abrazaderas.
1. Componente amplio y tabular (también conocido como DeepTabular)
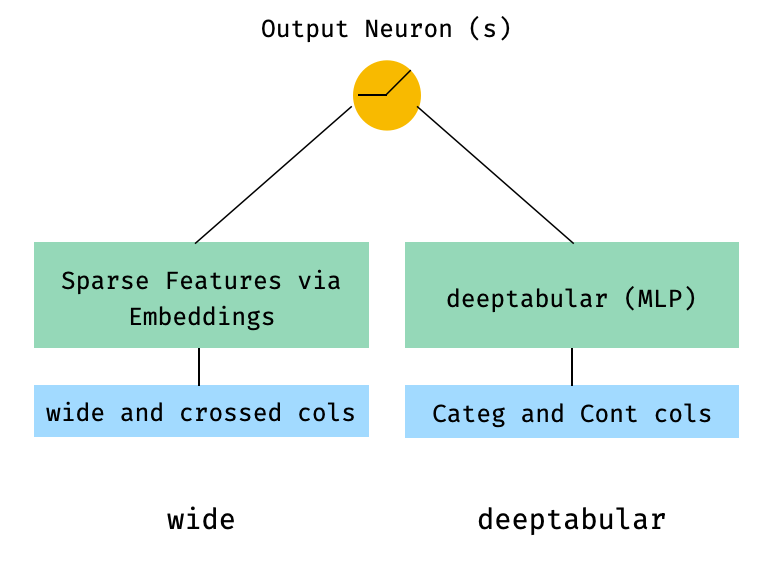
from pytorch_widedeep . preprocessing import TabPreprocessor , WidePreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . training import Trainer
# Wide
wide_cols = [ "city" ]
crossed_cols = [( "city" , "name" )]
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df )
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ])
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# WideDeep
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)2. Datos tabulares y de texto
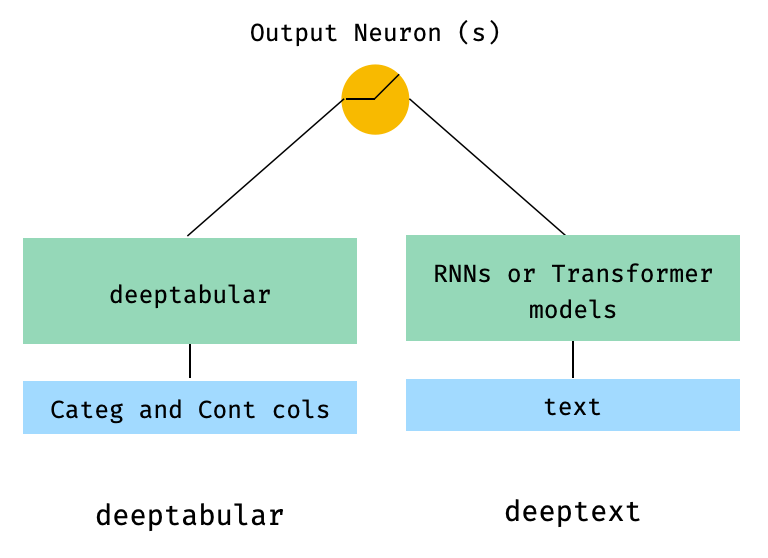
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 3. Tabular y texto con una cabeza FC en la parte superior a través del parámetro head_hidden_dims en WideDeep
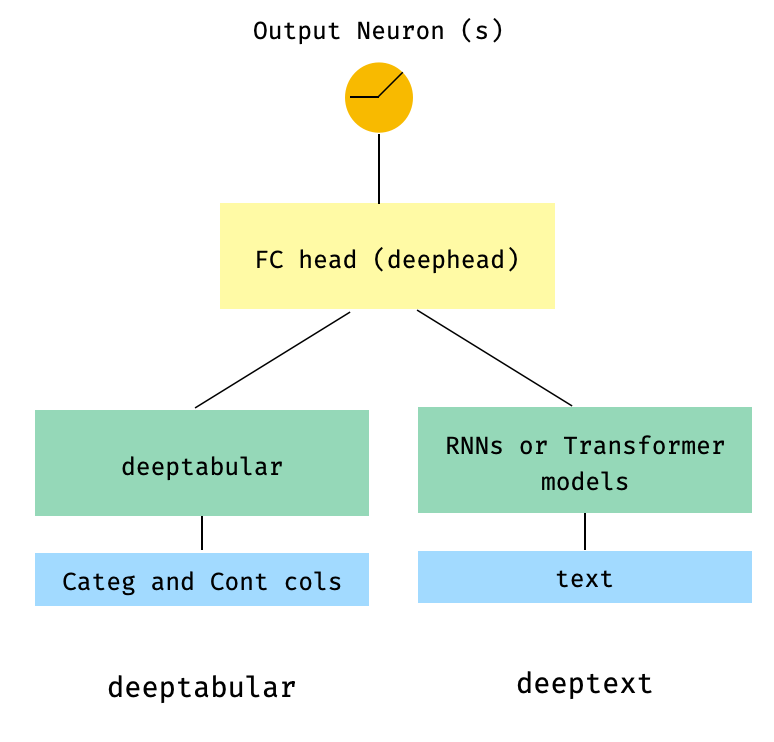
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn , head_hidden_dims = [ 32 , 16 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 4. Tabular y múltiples columnas de texto que se pasan directamente a WideDeep
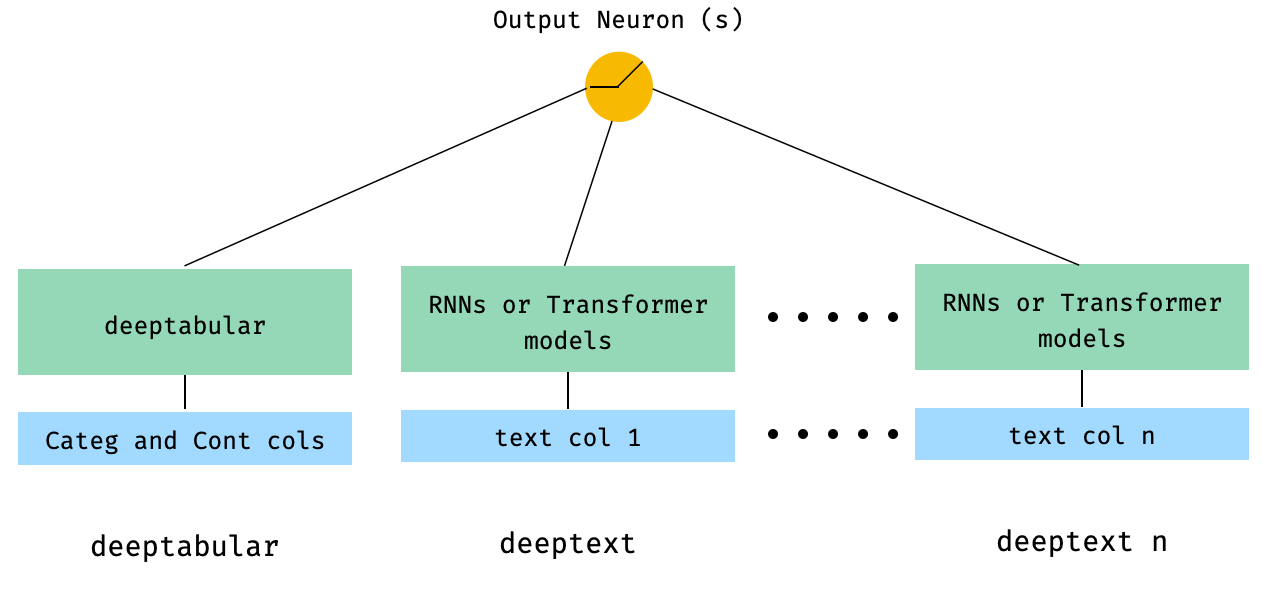
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = [ rnn_1 , rnn_2 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 5. Datos tabulares y múltiples columnas de texto que se fusionan a través de la clase ModelFuser de la biblioteca
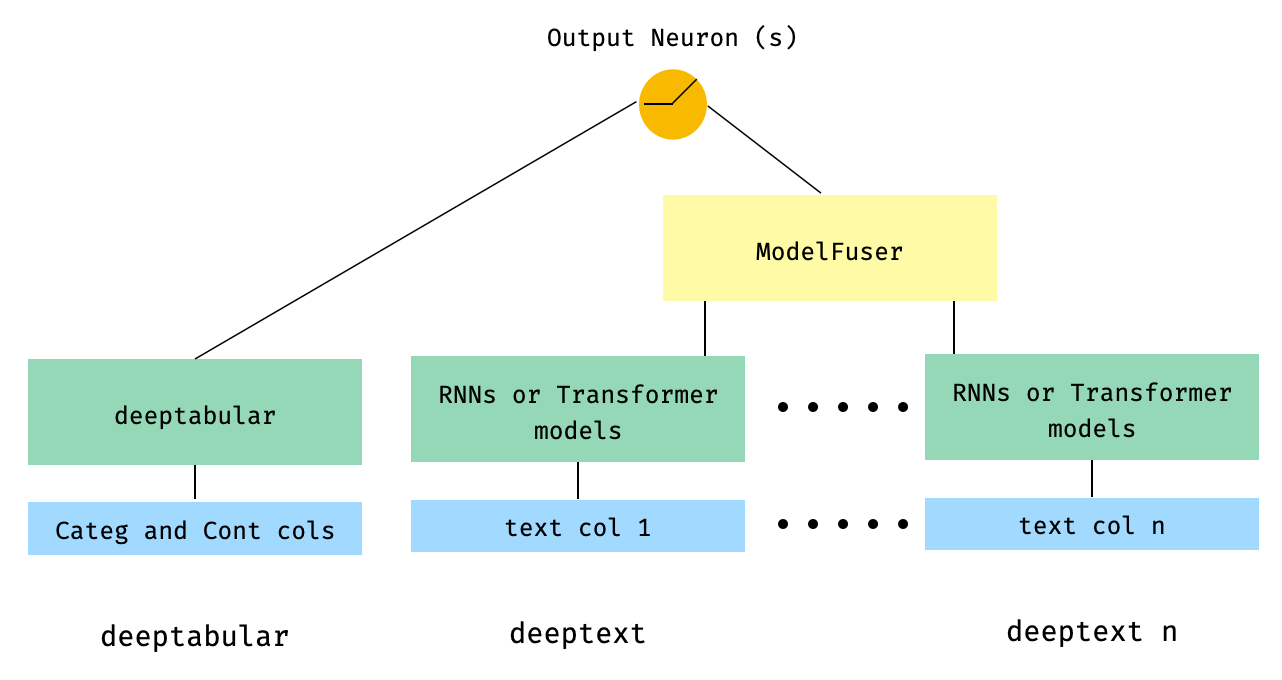
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser ( models = [ rnn_1 , rnn_2 ], fusion_method = "mult" )
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = models_fuser )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
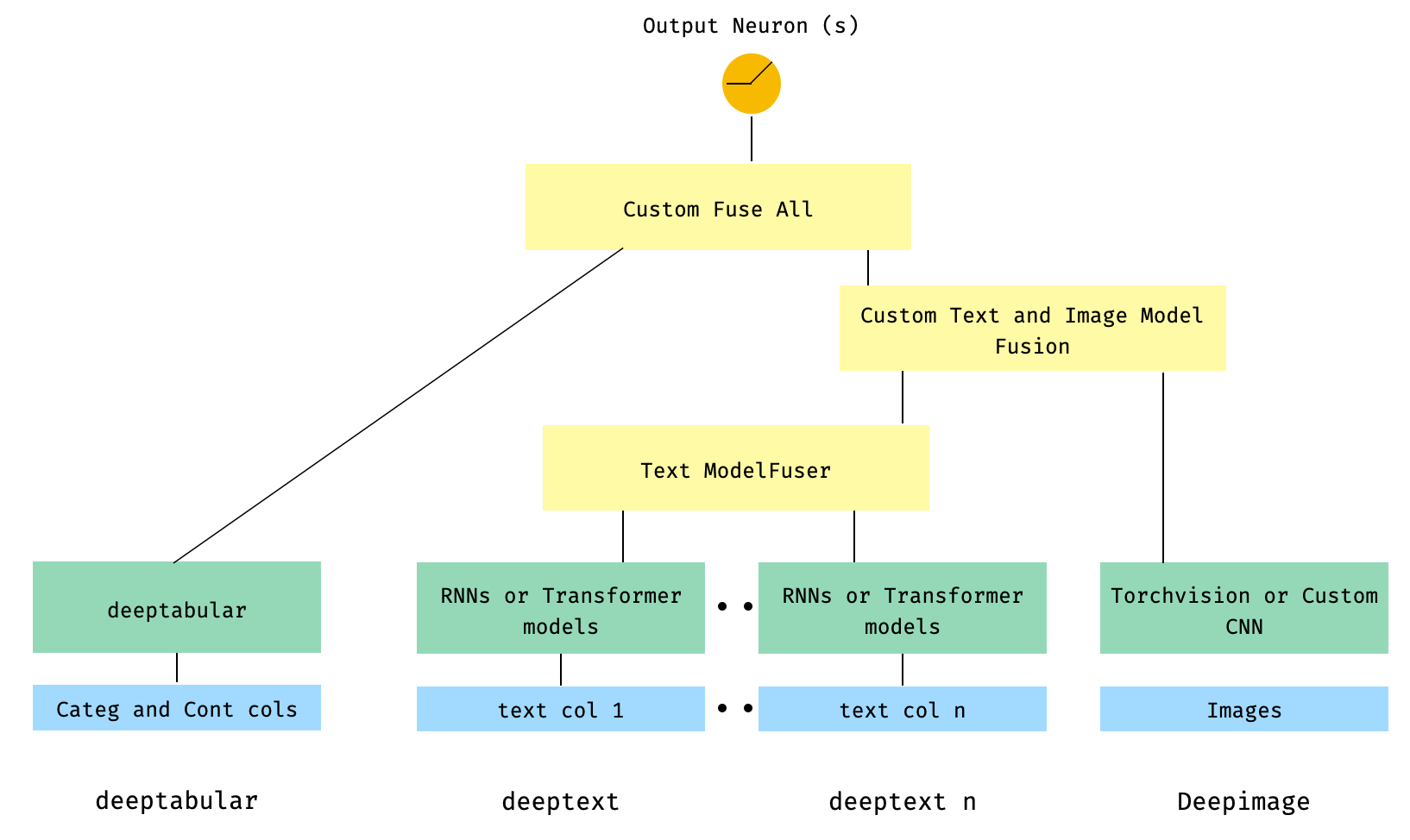
) 6. columnas de texto tabulares y múltiples, con una columna de imagen. Las columnas de texto se fusionan a través del ModelFuser de la biblioteca y luego todas se fusionan a través del Paramenter Deephead en WideDeep , que es un ModelFuser personalizado codificado por el usuario
Esta es quizás la solución menos elegante, ya que implica un componente personalizado por parte del usuario y cortando el tensor 'entrante'. En el futuro, incluiremos un TextAndImageModelFuser para que este proceso sea más sencillo. Aún así, no es realmente complicado y es un buen ejemplo de cómo usar componentes personalizados en pytorch-widedeep .
Tenga en cuenta que el único requisito para el componente personalizado es que tiene una propiedad llamada output_dim que devuelve el tamaño de la última capa de activaciones. En otras palabras, no necesita heredar de BaseWDModelComponent . Esta clase base simplemente verifica la existencia de dicha propiedad y evita algunos errores de escritura internamente.
import torch
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 16 , 8 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser (
models = [ rnn_1 , rnn_2 ],
fusion_method = "mult" ,
)
# Image
image_preprocessor = ImagePreprocessor ( img_col = "image_name" , img_path = "images" )
X_img = image_preprocessor . fit_transform ( df )
vision = Vision ( pretrained_model_setup = "resnet18" , head_hidden_dims = [ 16 , 8 ])
# deephead (custom model fuser)
class MyModelFuser ( BaseWDModelComponent ):
"""
Simply a Linear + Relu sequence on top of the text + images followed by a
Linear -> Relu -> Linear for the concatenation of tabular slice of the
tensor and the output of the text and image sequential model
"""
def __init__ (
self ,
tab_incoming_dim : int ,
text_incoming_dim : int ,
image_incoming_dim : int ,
output_units : int ,
):
super ( MyModelFuser , self ). __init__ ()
self . tab_incoming_dim = tab_incoming_dim
self . text_incoming_dim = text_incoming_dim
self . image_incoming_dim = image_incoming_dim
self . output_units = output_units
self . text_and_image_fuser = torch . nn . Sequential (
torch . nn . Linear ( text_incoming_dim + image_incoming_dim , output_units ),
torch . nn . ReLU (),
)
self . out = torch . nn . Sequential (
torch . nn . Linear ( output_units + tab_incoming_dim , output_units * 4 ),
torch . nn . ReLU (),
torch . nn . Linear ( output_units * 4 , output_units ),
)
def forward ( self , X : torch . Tensor ) -> torch . Tensor :
tab_slice = slice ( 0 , self . tab_incoming_dim )
text_slice = slice (
self . tab_incoming_dim , self . tab_incoming_dim + self . text_incoming_dim
)
image_slice = slice (
self . tab_incoming_dim + self . text_incoming_dim ,
self . tab_incoming_dim + self . text_incoming_dim + self . image_incoming_dim ,
)
X_tab = X [:, tab_slice ]
X_text = X [:, text_slice ]
X_img = X [:, image_slice ]
X_text_and_image = self . text_and_image_fuser ( torch . cat ([ X_text , X_img ], dim = 1 ))
return self . out ( torch . cat ([ X_tab , X_text_and_image ], dim = 1 ))
@ property
def output_dim ( self ):
return self . output_units
deephead = MyModelFuser (
tab_incoming_dim = tab_mlp . output_dim ,
text_incoming_dim = models_fuser . output_dim ,
image_incoming_dim = vision . output_dim ,
output_units = 8 ,
)
# WideDeep
model = WideDeep (
deeptabular = tab_mlp ,
deeptext = models_fuser ,
deepimage = vision ,
deephead = deephead ,
)
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
X_img = X_img ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
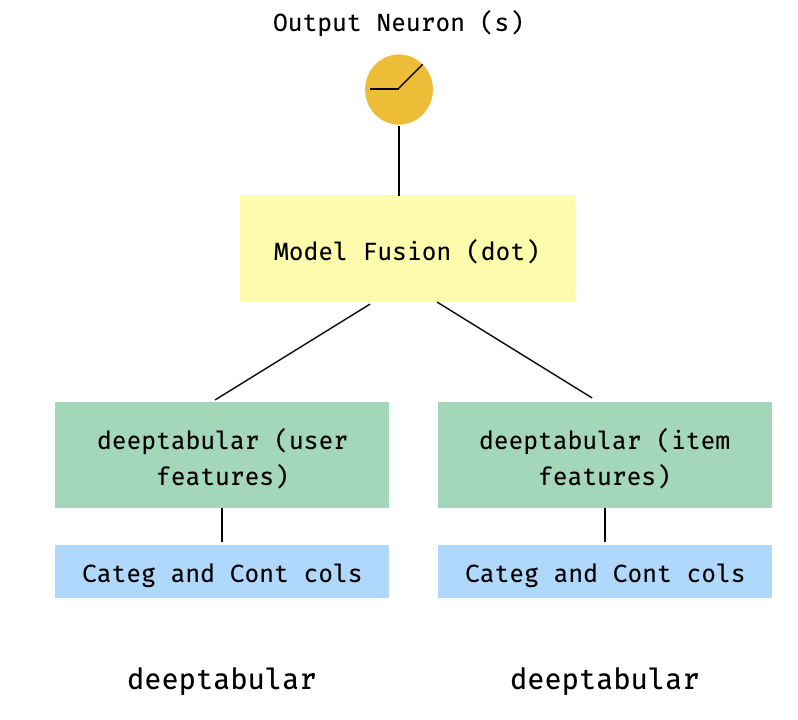
)7. Un modelo de dos torres
Este es un modelo popular en el contexto de los sistemas de recomendación. Digamos que tenemos un conjunto de datos tabular formado mis triples (características del usuario, características del elemento, objetivo). Podemos crear un modelo de dos torres donde el usuario y las características del elemento pasan a través de dos modelos separados y luego "fusionados" a través de un producto DOT.
import numpy as np
import pandas as pd
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import TabPreprocessor
from pytorch_widedeep . models import TabMlp , WideDeep , ModelFuser
# Let's create the interaction dataset
# user_features dataframe
np . random . seed ( 42 )
user_ids = np . arange ( 1 , 101 )
ages = np . random . randint ( 18 , 60 , size = 100 )
genders = np . random . choice ([ "male" , "female" ], size = 100 )
locations = np . random . choice ([ "city_a" , "city_b" , "city_c" , "city_d" ], size = 100 )
user_features = pd . DataFrame (
{ "id" : user_ids , "age" : ages , "gender" : genders , "location" : locations }
)
# item_features dataframe
item_ids = np . arange ( 1 , 101 )
prices = np . random . uniform ( 10 , 500 , size = 100 ). round ( 2 )
colors = np . random . choice ([ "red" , "blue" , "green" , "black" ], size = 100 )
categories = np . random . choice ([ "electronics" , "clothing" , "home" , "toys" ], size = 100 )
item_features = pd . DataFrame (
{ "id" : item_ids , "price" : prices , "color" : colors , "category" : categories }
)
# Interactions dataframe
interaction_user_ids = np . random . choice ( user_ids , size = 1000 )
interaction_item_ids = np . random . choice ( item_ids , size = 1000 )
purchased = np . random . choice ([ 0 , 1 ], size = 1000 , p = [ 0.7 , 0.3 ])
interactions = pd . DataFrame (
{
"user_id" : interaction_user_ids ,
"item_id" : interaction_item_ids ,
"purchased" : purchased ,
}
)
user_item_purchased = interactions . merge (
user_features , left_on = "user_id" , right_on = "id"
). merge ( item_features , left_on = "item_id" , right_on = "id" )
# Users
tab_preprocessor_user = TabPreprocessor (
cat_embed_cols = [ "gender" , "location" ],
continuous_cols = [ "age" ],
)
X_user = tab_preprocessor_user . fit_transform ( user_item_purchased )
tab_mlp_user = TabMlp (
column_idx = tab_preprocessor_user . column_idx ,
cat_embed_input = tab_preprocessor_user . cat_embed_input ,
continuous_cols = [ "age" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
# Items
tab_preprocessor_item = TabPreprocessor (
cat_embed_cols = [ "color" , "category" ],
continuous_cols = [ "price" ],
)
X_item = tab_preprocessor_item . fit_transform ( user_item_purchased )
tab_mlp_item = TabMlp (
column_idx = tab_preprocessor_item . column_idx ,
cat_embed_input = tab_preprocessor_item . cat_embed_input ,
continuous_cols = [ "price" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
two_tower_model = ModelFuser ([ tab_mlp_user , tab_mlp_item ], fusion_method = "dot" )
model = WideDeep ( deeptabular = two_tower_model )
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = [ X_user , X_item ],
target = interactions . purchased . values ,
n_epochs = 1 ,
batch_size = 32 ,
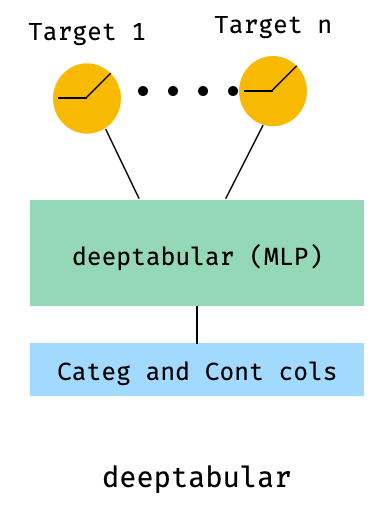
)8. Tabular con una pérdida multi-objetivo
Este es "una ventaja" para ilustrar el uso de pérdidas de objetivos múltiples, más que una arquitectura diferente.
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . losses_multitarget import MultiTargetClassificationLoss
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# let's add a second target to the dataframe
df [ "target2" ] = [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )]
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# 'pred_dim=2' because we have two binary targets. For other types of targets,
# please, see the documentation
model = WideDeep ( deeptabular = tab_mlp , pred_dim = 2 ).
loss = MultiTargetClassificationLoss ( binary_config = [ 0 , 1 ], reduction = "mean" )
# When a multi-target loss is used, 'custom_loss_function' must not be None.
# See the docs
trainer = Trainer ( model , objective = "multitarget" , custom_loss_function = loss )
trainer . fit (
X_tab = X_tab ,
target = df [[ "target" , "target2" ]]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)deeptabular Es importante enfatizar nuevamente que cada componente individual, wide , deeptabular , deeptext y deepimage , se puede usar de forma independiente y de forma aislada. Por ejemplo, uno podría usar solo wide , que es simplemente un modelo lineal. De hecho, una de las funcionalidades más interesantes en pytorch-widedeep sería el uso del componente deeptabular por sí solo, es decir, lo que se podría referir normalmente como aprendizaje profundo para los datos tabulares. Actualmente, pytorch-widedeep ofrece los siguientes modelos diferentes para ese componente:
Dos modelos basados en la atención más simples que llamamos:
La familia Tabformer , es decir, transformadores para datos tabulares:
Y modelos DL probabilísticos para datos tabulares basados en la incertidumbre de peso en las redes neuronales:
Wide .TabMlpTenga en cuenta que si bien hay publicaciones científicas para el TabTransformer, Saint y FT-Transformer, TabfasFafmer y TabPerceiver son nuestra propia adaptación de esos algoritmos para datos tabulares.
Además, el pre-entrenador auto-supervisado se puede utilizar para todos los modelos deeptabular , con la excepción del TabPerceiver . El pretrabenorable auto-supervisado se puede utilizar a través de dos métodos o rutinas que referimos como: método del decodificador del codificador y método de denegación de construcción. Por favor, consulte la documentación y los ejemplos para obtener detalles sobre esta funcionalidad, y todas las demás opciones en la biblioteca.
recEste módulo se introdujo como una extensión de los componentes existentes en la biblioteca, abordando preguntas y problemas relacionados con los sistemas de recomendación. Mientras aún está en desarrollo activo, actualmente incluye un número selecto de potentes modelos de recomendación.
Vale la pena señalar que esta biblioteca ya admitió la implementación de varios algoritmos de recomendación utilizando componentes existentes. Por ejemplo, modelos como el filtrado de colaboración de dos torres, de dos torres o neurales podrían construirse utilizando las funcionalidades centrales de la biblioteca.
Los algoritmos de recomendación en el módulo rec son:
Consulte los ejemplos para obtener detalles sobre cómo usar estos modelos.
Para el componente de texto, deeptext , la biblioteca ofrece los siguientes modelos:
Para el componente de imagen, deepimage , la biblioteca admite modelos de las siguientes familias: 'resnet', 'shufflenet', 'resnext', 'wide_resnet', 'regnet', 'densenet', 'mobileNetv3', 'mobileNetv2', 'mNASNET', 'EfficeMnet' y 'Squeezenet'. Estos se ofrecen a través de torchvision y envueltos en la clase Vision .
Instalar usando PIP:
pip install pytorch-widedeepO instalar directamente desde Github
pip install git+https://github.com/jrzaurin/pytorch-widedeep.git # Clone the repository
git clone https://github.com/jrzaurin/pytorch-widedeep
cd pytorch-widedeep
# Install in dev mode
pip install -e . Aquí hay un ejemplo de extremo a extremo de una clasificación binaria con el conjunto de datos para adultos utilizando la configuración Wide and DeepDense y predeterminadas.
Construyendo un modelo amplio (lineal) y profundo con pytorch-widedeep :
import numpy as np
import torch
from sklearn . model_selection import train_test_split
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import WidePreprocessor , TabPreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . metrics import Accuracy
from pytorch_widedeep . datasets import load_adult
df = load_adult ( as_frame = True )
df [ "income_label" ] = ( df [ "income" ]. apply ( lambda x : ">50K" in x )). astype ( int )
df . drop ( "income" , axis = 1 , inplace = True )
df_train , df_test = train_test_split ( df , test_size = 0.2 , stratify = df . income_label )
# Define the 'column set up'
wide_cols = [
"education" ,
"relationship" ,
"workclass" ,
"occupation" ,
"native-country" ,
"gender" ,
]
crossed_cols = [( "education" , "occupation" ), ( "native-country" , "occupation" )]
cat_embed_cols = [
"workclass" ,
"education" ,
"marital-status" ,
"occupation" ,
"relationship" ,
"race" ,
"gender" ,
"capital-gain" ,
"capital-loss" ,
"native-country" ,
]
continuous_cols = [ "age" , "hours-per-week" ]
target = "income_label"
target = df_train [ target ]. values
# prepare the data
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df_train )
tab_preprocessor = TabPreprocessor (
cat_embed_cols = cat_embed_cols , continuous_cols = continuous_cols # type: ignore[arg-type]
)
X_tab = tab_preprocessor . fit_transform ( df_train )
# build the model
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ], pred_dim = 1 )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = continuous_cols ,
)
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# train and validate
trainer = Trainer ( model , objective = "binary" , metrics = [ Accuracy ])
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = target ,
n_epochs = 5 ,
batch_size = 256 ,
)
# predict on test
X_wide_te = wide_preprocessor . transform ( df_test )
X_tab_te = tab_preprocessor . transform ( df_test )
preds = trainer . predict ( X_wide = X_wide_te , X_tab = X_tab_te )
# Save and load
# Option 1: this will also save training history and lr history if the
# LRHistory callback is used
trainer . save ( path = "model_weights" , save_state_dict = True )
# Option 2: save as any other torch model
torch . save ( model . state_dict (), "model_weights/wd_model.pt" )
# From here in advance, Option 1 or 2 are the same. I assume the user has
# prepared the data and defined the new model components:
# 1. Build the model
model_new = WideDeep ( wide = wide , deeptabular = tab_mlp )
model_new . load_state_dict ( torch . load ( "model_weights/wd_model.pt" ))
# 2. Instantiate the trainer
trainer_new = Trainer ( model_new , objective = "binary" )
# 3. Either start the fit or directly predict
preds = trainer_new . predict ( X_wide = X_wide , X_tab = X_tab , batch_size = 32 )Por supuesto, uno puede hacer mucho más . Consulte la carpeta de ejemplos, la documentación o las publicaciones complementarias para una mejor comprensión del contenido del paquete y sus funcionalidades.
pytest tests
Verifique la página contribuyente.
Esta biblioteca toma de una serie de otras bibliotecas, por lo que creo que es justo mencionarlas aquí en el ReadMe (las menciones específicas también se incluyen en el código).
La estructura y el código Callbacks y Initializers está inspirado en la biblioteca torchsample , que en sí misma inspirada parcialmente en Keras .
La clase TextProcessor en esta biblioteca utiliza el Tokenizer y Vocab de fastai . El código en utils.fastai_transforms es una adaptación menor de su código, por lo que funciona dentro de esta biblioteca. Para mi experiencia, su Tokenizer es el mejor en clase.
La clase ImageProcessor en esta biblioteca utiliza el código del fantástico libro de aprendizaje profundo para la visión por computadora (DL4CV) de Adrian Rosebrock.
Este trabajo es de doble licencia bajo Apache 2.0 y MIT (o cualquier versión posterior). Puede elegir entre uno de ellos si usa este trabajo.
SPDX-License-Identifier: Apache-2.0 AND MIT
@article{Zaurin_pytorch-widedeep_A_flexible_2023,
author = {Zaurin, Javier Rodriguez and Mulinka, Pavol},
doi = {10.21105/joss.05027},
journal = {Journal of Open Source Software},
month = jun,
number = {86},
pages = {5027},
title = {{pytorch-widedeep: A flexible package for multimodal deep learning}},
url = {https://joss.theoj.org/papers/10.21105/joss.05027},
volume = {8},
year = {2023}
}
Zaurin, J. R., & Mulinka, P. (2023). pytorch-widedeep: A flexible package for
multimodal deep learning. Journal of Open Source Software, 8(86), 5027.
https://doi.org/10.21105/joss.05027


