pytorch widedeep
mps backend support and more rec models
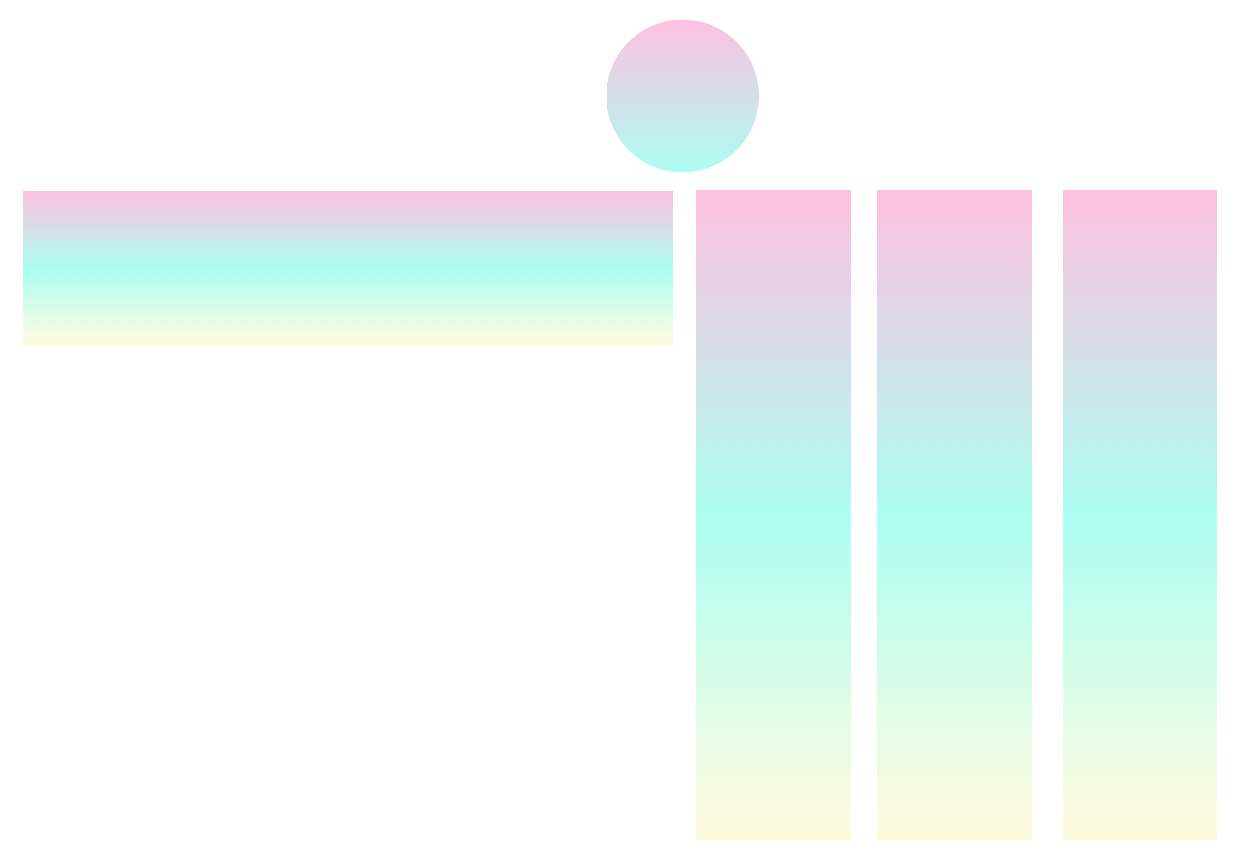
Ein flexibles Paket für multimodal-tiefe Lern, um tabellarische Daten mit Text und Bildern mit breiten und tiefen Modellen in Pytorch zu kombinieren
Dokumentation: https://pytorch-wideep.readthedocs.io
Begleitposts und Tutorials: Infinitoml
Experimente und Vergleich mit LightGBM : Tabulardl vs LightGBM
Slack : Wenn Sie einen Beitrag leisten oder nur mit uns chatten möchten, schließen Sie sich Slack bei
Der Inhalt dieses Dokuments ist wie folgt organisiert:
deeptabular Komponenterec -Modul pytorch-widedeep basiert auf dem breiten und tiefen Algorithmus von Google, der für multimodale Datensätze angepasst ist.
Im Allgemeinen ist pytorch-widedeep ein Paket, das Deep Learning mit tabellarischen Daten verwendet. Insbesondere soll die Kombination von Text und Bildern mit entsprechenden tabellarischen Daten mit breiten und tiefen Modellen erleichtert werden. Vor diesem Hintergrund gibt es eine Reihe von Architekturen, die mit der Bibliothek implementiert werden können. Die Hauptkomponenten dieser Architekturen sind in der folgenden Abbildung dargestellt:
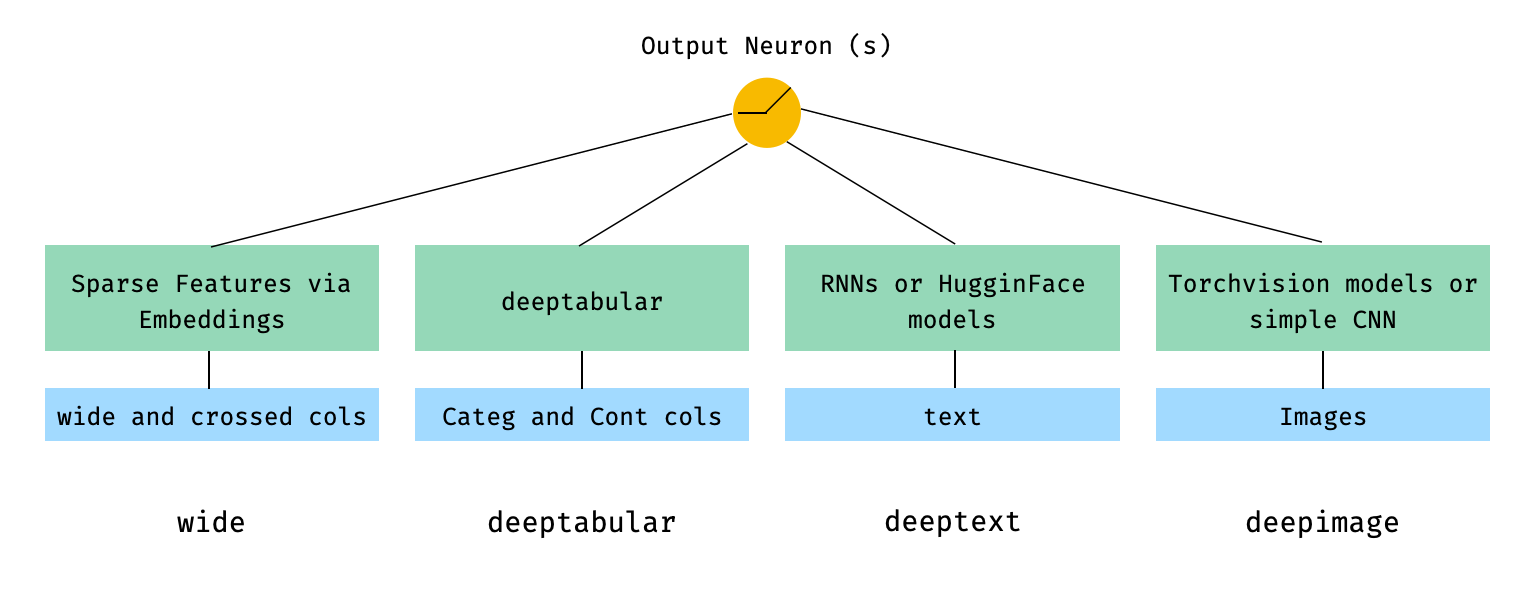
In mathematischen Begriffen und nach der Notation im Papier kann der Ausdruck für die Architektur ohne deephead -Komponente formuliert werden wie:
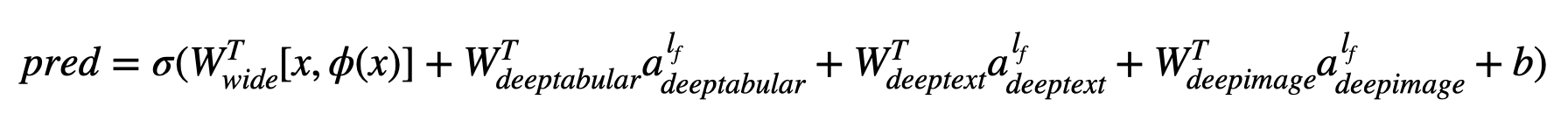
Wenn σ die Sigmoidfunktion ist, sind 'W' die auf das breiten Modell angewendeten Gewichtsmatrizen und die endgültigen Aktivierungen der tiefen Modelle "A" sind diese endgültigen Aktivierungen, φ (x) sind die Querprodukttransformationen der ursprünglichen Merkmale "x" und "B" ist der BIAS -Term. Wenn Sie sich fragen, was "Cross-Produkt-Transformationen" sind, ist hier ein Zitat, das direkt aus dem Papier entnommen wird: "Für binäre Merkmale ist eine Querprodukt-Transformation (z. B." und (Geschlecht = weiblich, Sprache = en) ") 1, wenn und nur dann, wenn die konstituierenden Merkmale (" Geschlecht = weiblich "und" Sprache = EN ") alle 1 und 0 sind, und 0, anderweitig."
Es ist durchaus möglich, benutzerdefinierte Modelle (und nicht unbedingt die in der Bibliothek) zu verwenden, solange die benutzerdefinierten Modelle eine Eigenschaft namens output_dim mit der Größe der letzten Aktivierungsschicht haben, sodass WideDeep konstruiert werden kann. Beispiele zur Verwendung benutzerdefinierter Komponenten finden Sie im Beispieleordner und im folgenden Abschnitt.
Die pytorch-widedeep -Bibliothek bietet eine Reihe verschiedener Architekturen. In diesem Abschnitt zeigen wir einige von ihnen in ihrer einfachsten Form (dh in den meisten Fällen mit Standardparamwerten) mit ihren entsprechenden Code -Snippets. Beachten Sie, dass alle Snippets unten vor Ort laufen. Eine detailliertere Erläuterung der verschiedenen Komponenten und ihrer Parameter finden Sie in der Dokumentation.
Für die folgenden Beispiele werden wir einen wie folgt generierten Spielzeugdatensatz verwenden:
import os
import random
import numpy as np
import pandas as pd
from PIL import Image
from faker import Faker
def create_and_save_random_image ( image_number , size = ( 32 , 32 )):
if not os . path . exists ( "images" ):
os . makedirs ( "images" )
array = np . random . randint ( 0 , 256 , ( size [ 0 ], size [ 1 ], 3 ), dtype = np . uint8 )
image = Image . fromarray ( array )
image_name = f"image_ { image_number } .png"
image . save ( os . path . join ( "images" , image_name ))
return image_name
fake = Faker ()
cities = [ "New York" , "Los Angeles" , "Chicago" , "Houston" ]
names = [ "Alice" , "Bob" , "Charlie" , "David" , "Eva" ]
data = {
"city" : [ random . choice ( cities ) for _ in range ( 100 )],
"name" : [ random . choice ( names ) for _ in range ( 100 )],
"age" : [ random . uniform ( 18 , 70 ) for _ in range ( 100 )],
"height" : [ random . uniform ( 150 , 200 ) for _ in range ( 100 )],
"sentence" : [ fake . sentence () for _ in range ( 100 )],
"other_sentence" : [ fake . sentence () for _ in range ( 100 )],
"image_name" : [ create_and_save_random_image ( i ) for i in range ( 100 )],
"target" : [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )],
}
df = pd . DataFrame ( data ) Dadurch werden in Ihrem lokalen Ordner ein 100 -Zeilen -Datenframe und ein Dire erstellt, das als images mit 100 zufälligen Bildern (oder Bildern mit nur Rauschen) bezeichnet wird.
Vielleicht wäre die einfachste Architektur nur eine Komponente, wide , deeptabular , deeptext oder deepimage allein, was ebenfalls möglich ist, aber beginnen wir die Beispiele mit einer Standard -Breite und tiefen Architektur. Von dort aus ist das Erstellen eines Modells, das nur eine Komponente besteht, unkompliziert.
Beachten Sie, dass die unten gezeigten Beispiele mit einem der in der Bibliothek verfügbaren Modelle nahezu identisch sind. Beispielsweise kann TabMlp durch TabResnet , TabNet , TabTransformer usw. ersetzt werden. In ähnlicher Weise kann BasicRNN durch AttentiveRNN , StackedAttentiveRNN oder HFModel durch ihre entsprechenden Parameter und Vorverarbeitete ersetzt werden.
1. Breite und tabellarische Komponente (auch bekannt als Deeptabular)
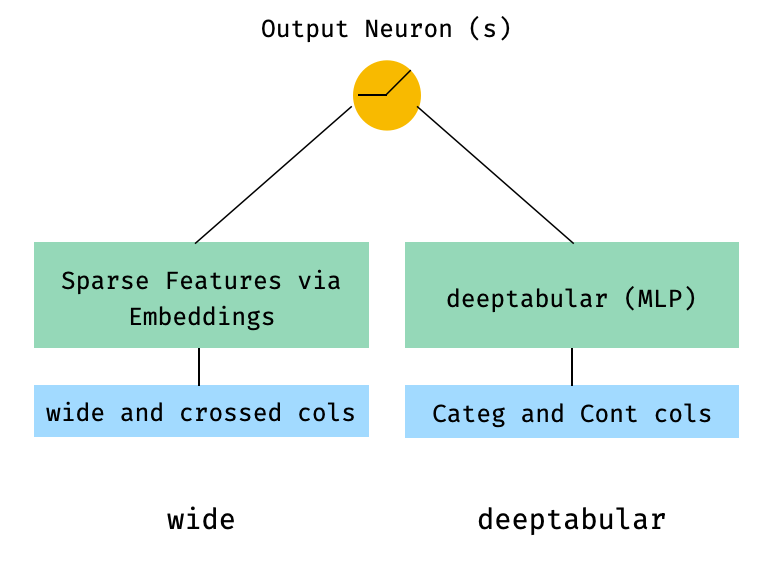
from pytorch_widedeep . preprocessing import TabPreprocessor , WidePreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . training import Trainer
# Wide
wide_cols = [ "city" ]
crossed_cols = [( "city" , "name" )]
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df )
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ])
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# WideDeep
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)2. Tabelle und Textdaten
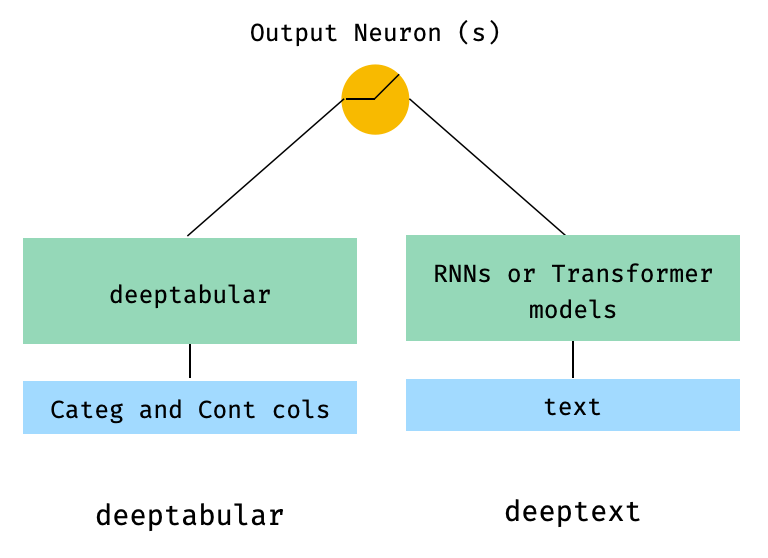
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 3.. Tabelle und Text mit einem FC -Kopf darüber über den Param head_hidden_dims in WideDeep
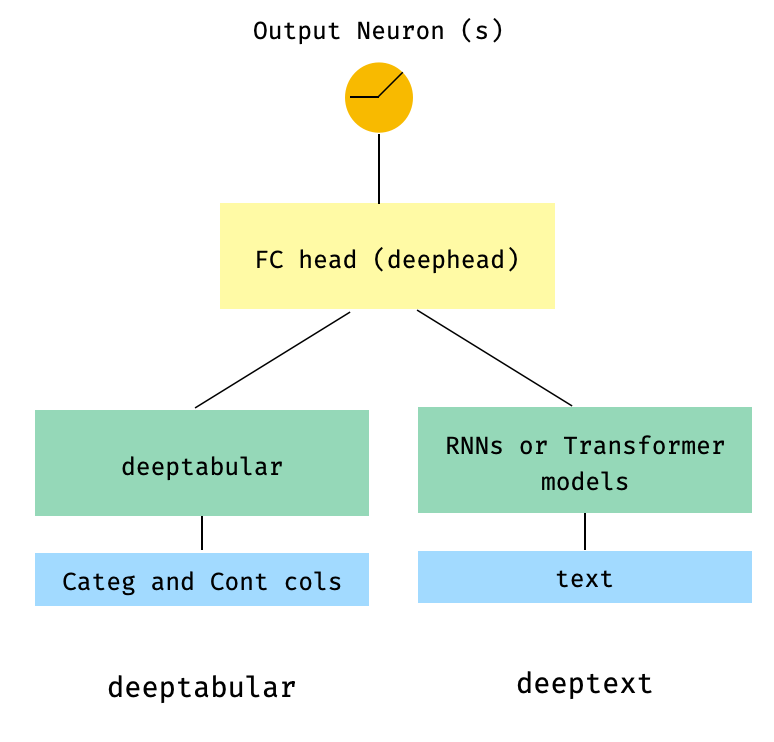
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn , head_hidden_dims = [ 32 , 16 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 4. Tabelle und mehrere Textspalten, die direkt an WideDeep übergeben werden
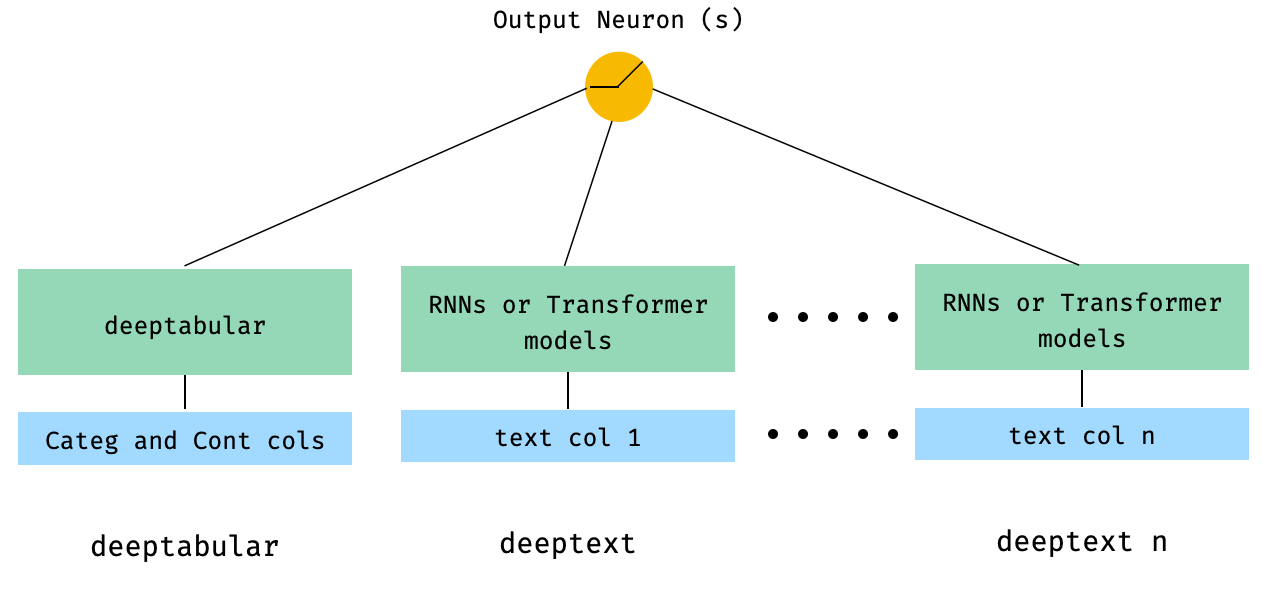
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = [ rnn_1 , rnn_2 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 5. Tabulärdaten und mehrere Textspalten, die über eine ModelFuser -Klasse der Bibliothek verschmolzen sind
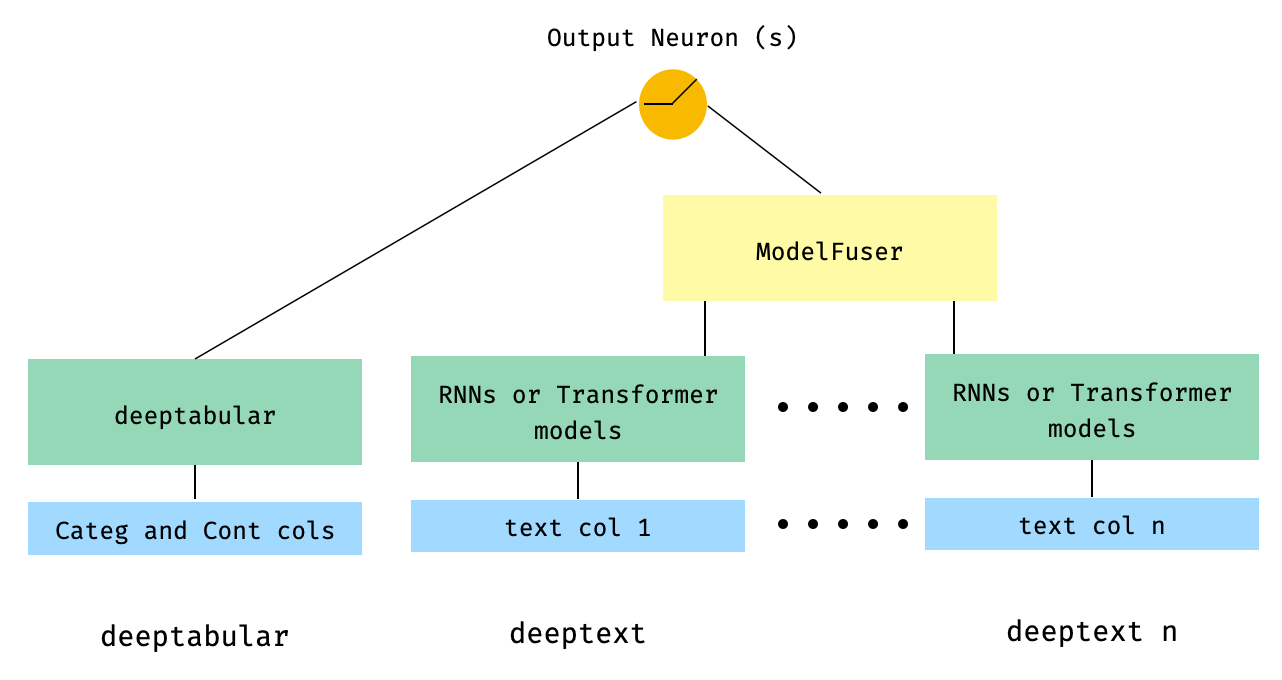
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser ( models = [ rnn_1 , rnn_2 ], fusion_method = "mult" )
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = models_fuser )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
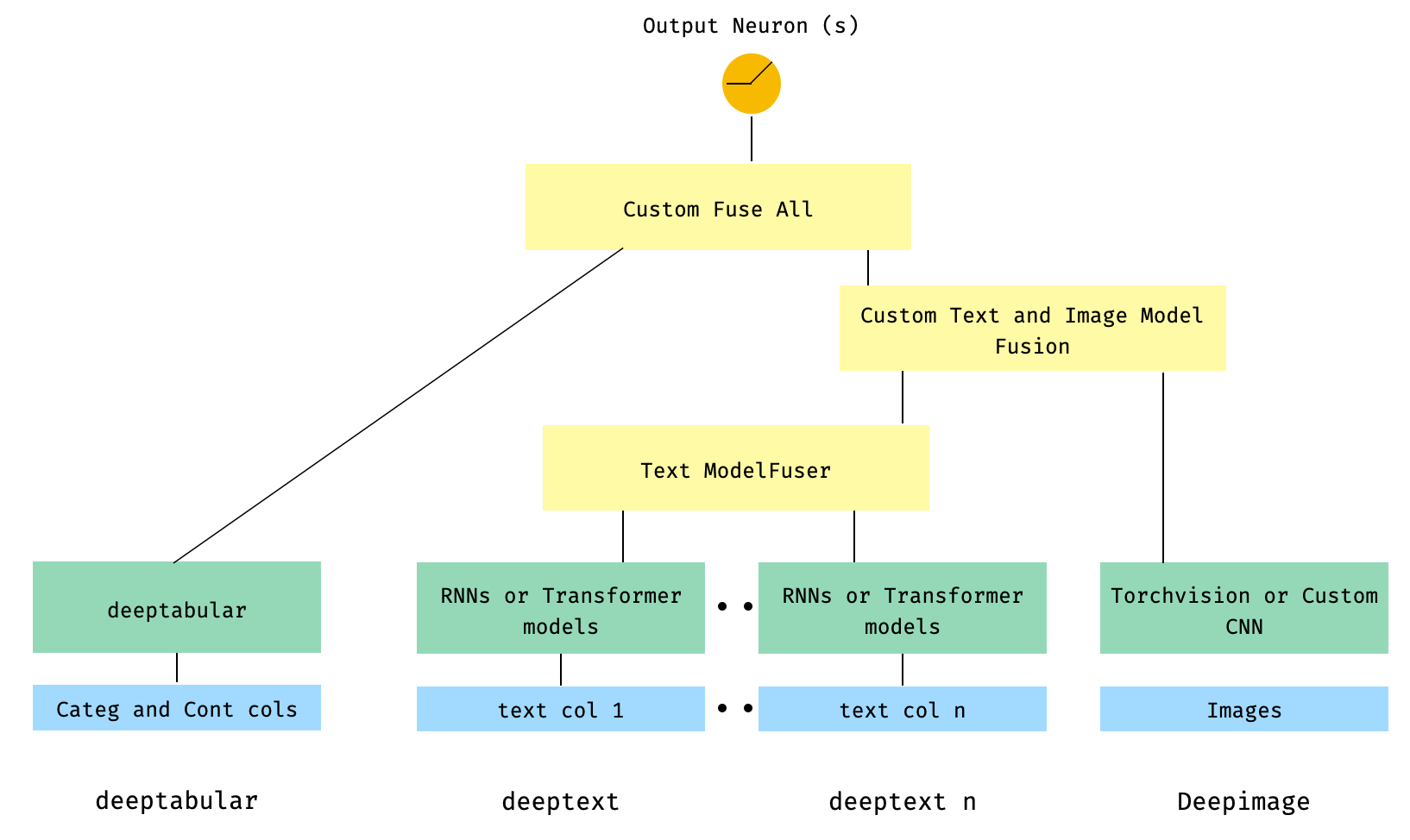
) 6. Tabelle und mehrere Textspalten mit einer Bildspalte. Die Textspalten werden über den ModelFuser der Bibliothek und dann alle über den Deephead -Paramator in WideDeep verschmolzen, ein benutzerdefinierter ModelFuser der vom Benutzer codiert wird
Dies ist möglicherweise die weniger elegante Lösung, da sie eine benutzerdefinierte Komponente des Benutzers und den Tensor "eingehender" Tensor umfasst. In Zukunft werden wir einen TextAndImageModelFuser aufnehmen, um diesen Prozess einfacher zu machen. Trotzdem ist es nicht wirklich kompliziert und es ist ein gutes Beispiel dafür, wie benutzerdefinierte Komponenten in pytorch-widedeep verwendet werden können.
Beachten Sie, dass die einzige Anforderung für die benutzerdefinierte Komponente darin besteht, dass sie eine Eigenschaft namens output_dim enthält, die die Größe der letzten Aktivierungsschicht zurückgibt. Mit anderen Worten, es muss nicht von BaseWDModelComponent erben. Diese Basisklasse überprüft lediglich das Vorhandensein einer solchen Eigenschaft und vermeidet einige typisierende Fehler intern.
import torch
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 16 , 8 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser (
models = [ rnn_1 , rnn_2 ],
fusion_method = "mult" ,
)
# Image
image_preprocessor = ImagePreprocessor ( img_col = "image_name" , img_path = "images" )
X_img = image_preprocessor . fit_transform ( df )
vision = Vision ( pretrained_model_setup = "resnet18" , head_hidden_dims = [ 16 , 8 ])
# deephead (custom model fuser)
class MyModelFuser ( BaseWDModelComponent ):
"""
Simply a Linear + Relu sequence on top of the text + images followed by a
Linear -> Relu -> Linear for the concatenation of tabular slice of the
tensor and the output of the text and image sequential model
"""
def __init__ (
self ,
tab_incoming_dim : int ,
text_incoming_dim : int ,
image_incoming_dim : int ,
output_units : int ,
):
super ( MyModelFuser , self ). __init__ ()
self . tab_incoming_dim = tab_incoming_dim
self . text_incoming_dim = text_incoming_dim
self . image_incoming_dim = image_incoming_dim
self . output_units = output_units
self . text_and_image_fuser = torch . nn . Sequential (
torch . nn . Linear ( text_incoming_dim + image_incoming_dim , output_units ),
torch . nn . ReLU (),
)
self . out = torch . nn . Sequential (
torch . nn . Linear ( output_units + tab_incoming_dim , output_units * 4 ),
torch . nn . ReLU (),
torch . nn . Linear ( output_units * 4 , output_units ),
)
def forward ( self , X : torch . Tensor ) -> torch . Tensor :
tab_slice = slice ( 0 , self . tab_incoming_dim )
text_slice = slice (
self . tab_incoming_dim , self . tab_incoming_dim + self . text_incoming_dim
)
image_slice = slice (
self . tab_incoming_dim + self . text_incoming_dim ,
self . tab_incoming_dim + self . text_incoming_dim + self . image_incoming_dim ,
)
X_tab = X [:, tab_slice ]
X_text = X [:, text_slice ]
X_img = X [:, image_slice ]
X_text_and_image = self . text_and_image_fuser ( torch . cat ([ X_text , X_img ], dim = 1 ))
return self . out ( torch . cat ([ X_tab , X_text_and_image ], dim = 1 ))
@ property
def output_dim ( self ):
return self . output_units
deephead = MyModelFuser (
tab_incoming_dim = tab_mlp . output_dim ,
text_incoming_dim = models_fuser . output_dim ,
image_incoming_dim = vision . output_dim ,
output_units = 8 ,
)
# WideDeep
model = WideDeep (
deeptabular = tab_mlp ,
deeptext = models_fuser ,
deepimage = vision ,
deephead = deephead ,
)
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
X_img = X_img ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
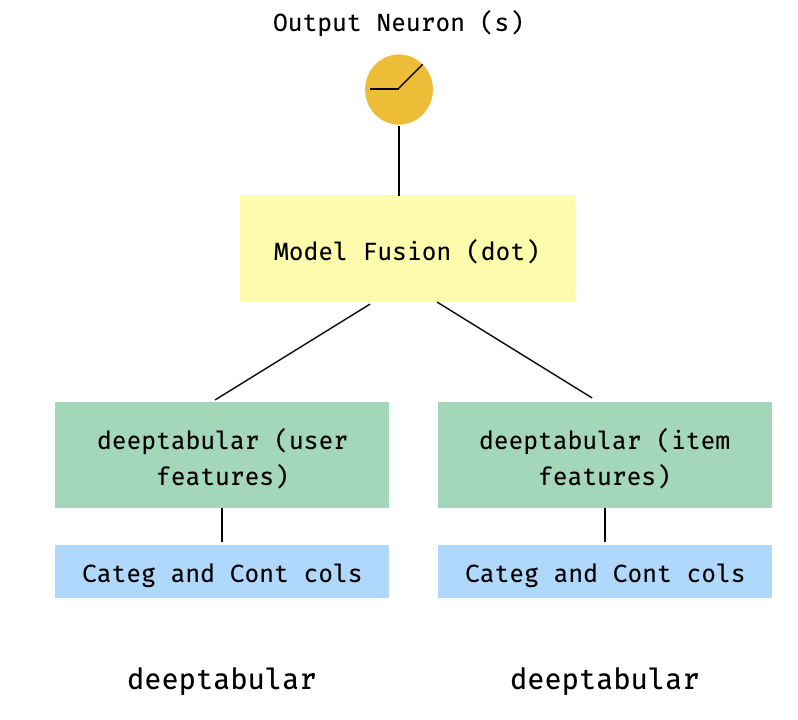
)7. Ein Zwei-Turm-Modell
Dies ist ein beliebtes Modell im Kontext von Empfehlungssystemen. Nehmen wir an, wir haben einen tabellarischen Datensatz, der meine Dreifachs gebildet hat (Benutzerfunktionen, Elementfunktionen, Ziel). Wir können ein Zwei-Turm-Modell erstellen, bei dem die Benutzer- und Elementfunktionen durch zwei separate Modelle geleitet und dann über ein Punktprodukt "verschmolzen" werden.
import numpy as np
import pandas as pd
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import TabPreprocessor
from pytorch_widedeep . models import TabMlp , WideDeep , ModelFuser
# Let's create the interaction dataset
# user_features dataframe
np . random . seed ( 42 )
user_ids = np . arange ( 1 , 101 )
ages = np . random . randint ( 18 , 60 , size = 100 )
genders = np . random . choice ([ "male" , "female" ], size = 100 )
locations = np . random . choice ([ "city_a" , "city_b" , "city_c" , "city_d" ], size = 100 )
user_features = pd . DataFrame (
{ "id" : user_ids , "age" : ages , "gender" : genders , "location" : locations }
)
# item_features dataframe
item_ids = np . arange ( 1 , 101 )
prices = np . random . uniform ( 10 , 500 , size = 100 ). round ( 2 )
colors = np . random . choice ([ "red" , "blue" , "green" , "black" ], size = 100 )
categories = np . random . choice ([ "electronics" , "clothing" , "home" , "toys" ], size = 100 )
item_features = pd . DataFrame (
{ "id" : item_ids , "price" : prices , "color" : colors , "category" : categories }
)
# Interactions dataframe
interaction_user_ids = np . random . choice ( user_ids , size = 1000 )
interaction_item_ids = np . random . choice ( item_ids , size = 1000 )
purchased = np . random . choice ([ 0 , 1 ], size = 1000 , p = [ 0.7 , 0.3 ])
interactions = pd . DataFrame (
{
"user_id" : interaction_user_ids ,
"item_id" : interaction_item_ids ,
"purchased" : purchased ,
}
)
user_item_purchased = interactions . merge (
user_features , left_on = "user_id" , right_on = "id"
). merge ( item_features , left_on = "item_id" , right_on = "id" )
# Users
tab_preprocessor_user = TabPreprocessor (
cat_embed_cols = [ "gender" , "location" ],
continuous_cols = [ "age" ],
)
X_user = tab_preprocessor_user . fit_transform ( user_item_purchased )
tab_mlp_user = TabMlp (
column_idx = tab_preprocessor_user . column_idx ,
cat_embed_input = tab_preprocessor_user . cat_embed_input ,
continuous_cols = [ "age" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
# Items
tab_preprocessor_item = TabPreprocessor (
cat_embed_cols = [ "color" , "category" ],
continuous_cols = [ "price" ],
)
X_item = tab_preprocessor_item . fit_transform ( user_item_purchased )
tab_mlp_item = TabMlp (
column_idx = tab_preprocessor_item . column_idx ,
cat_embed_input = tab_preprocessor_item . cat_embed_input ,
continuous_cols = [ "price" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
two_tower_model = ModelFuser ([ tab_mlp_user , tab_mlp_item ], fusion_method = "dot" )
model = WideDeep ( deeptabular = two_tower_model )
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = [ X_user , X_item ],
target = interactions . purchased . values ,
n_epochs = 1 ,
batch_size = 32 ,
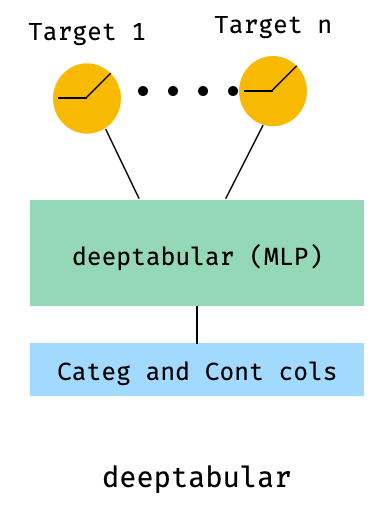
)8. tabellarisch mit einem Multi-Ziel-Verlust
Dieser ist "ein Bonus", um die Verwendung von Multi-Ziel-Verlusten zu veranschaulichen, mehr als tatsächlich eine andere Architektur.
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . losses_multitarget import MultiTargetClassificationLoss
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# let's add a second target to the dataframe
df [ "target2" ] = [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )]
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# 'pred_dim=2' because we have two binary targets. For other types of targets,
# please, see the documentation
model = WideDeep ( deeptabular = tab_mlp , pred_dim = 2 ).
loss = MultiTargetClassificationLoss ( binary_config = [ 0 , 1 ], reduction = "mean" )
# When a multi-target loss is used, 'custom_loss_function' must not be None.
# See the docs
trainer = Trainer ( model , objective = "multitarget" , custom_loss_function = loss )
trainer . fit (
X_tab = X_tab ,
target = df [[ "target" , "target2" ]]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)deeptabular Komponente Es ist wichtig zu betonen, dass jede einzelne Komponente, wide , deeptabular , deeptext und deepimage , unabhängig und isoliert verwendet werden können . Zum Beispiel könnte man nur wide verwenden, was einfach in einem linearen Modell ist. Tatsächlich wäre eine der interessantesten Funktionen in pytorch-widedeep die Verwendung der deeptabular Komponente selbst, dh das, was man normalerweise als tiefes Lernen für tabuläre Daten bezeichnen könnte. Derzeit bietet pytorch-widedeep die folgenden Modelle für diese Komponente an:
Zwei einfachere aufmerksamkeitsbasierte Modelle, die wir nennen:
Die Tabformer -Familie, dh Transformatoren für tabellarische Daten:
Und probabilistische DL -Modelle für tabellarische Daten basierend auf Gewichtsunsicherheit in neuronalen Netzwerken:
Wide Modells.TabMlp -ModellsBeachten Sie, dass es zwar wissenschaftliche Veröffentlichungen für den Tabransformer, Saint und FT-Transformer gibt, der Tabfasfformer und Tabperceiver unsere eigene Anpassung dieser Algorithmen für tabellische Daten sind.
Darüber hinaus kann selbstbeschäftigte Vortraining für alle deeptabular Modelle verwendet werden, mit Ausnahme des TabPerceiver . Selbsterbetrages Vorverbrauch kann über zwei Methoden oder Routinen verwendet werden, die wir als: Encoder-Decoder-Methode und konstruktionsbekennende Methode bezeichnen. Bitte siehe die Dokumentation und die Beispiele für Einzelheiten zu dieser Funktionalität und alle anderen Optionen in der Bibliothek.
rec -ModulDieses Modul wurde als Erweiterung der vorhandenen Komponenten in der Bibliothek eingeführt, in der Fragen und Probleme im Zusammenhang mit Empfehlungssystemen behandelt wurden. Während es noch unter aktiver Entwicklung ist, enthält es derzeit eine ausgewählte Anzahl leistungsstarker Empfehlungsmodelle.
Es ist erwähnenswert, dass diese Bibliothek die Implementierung verschiedener Empfehlungsalgorithmen mithilfe vorhandener Komponenten bereits unterstützte. Beispielsweise könnten Modelle wie breite und tiefe, zweizählige oder neuronale kollaborative Filterung unter Verwendung der Kernfunktionen der Bibliothek konstruiert werden.
Die Empfehlungsalgorithmen im rec -Modul sind:
In den Beispielen finden Sie Details zur Verwendung dieser Modelle.
Für die Textkomponente deeptext bietet die Bibliothek die folgenden Modelle:
Für die Bildkomponente deepimage unterstützt die Bibliothek Modelle aus den folgenden Familien: 'resnet', 'shufflenet', 'resnext', 'wide_resnet', 'Regnet', 'Densenet', 'Mobilenetv3', 'Mobilenetv2', 'Mnasnet', 'EfficieneTv3' und 'Squeezenet' und 'Squeezenet' und 'Squeezenet' und 'Squeezenet' und 'Squeezenet' und 'Squeezenet' und 'Squeezenet' und 'Squeezenet'. Diese werden über torchvision angeboten und in die Vision eingewickelt.
Mit PIP installieren:
pip install pytorch-widedeepOder direkt von Github installieren
pip install git+https://github.com/jrzaurin/pytorch-widedeep.git # Clone the repository
git clone https://github.com/jrzaurin/pytorch-widedeep
cd pytorch-widedeep
# Install in dev mode
pip install -e . Hier ist ein End-to-End-Beispiel für eine binäre Klassifizierung mit dem Datensatz für Erwachsene mit Wide und DeepDense und Standardeinstellungen.
Aufbau eines breiten (linearen) und tiefen Modells mit pytorch-widedeep :
import numpy as np
import torch
from sklearn . model_selection import train_test_split
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import WidePreprocessor , TabPreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . metrics import Accuracy
from pytorch_widedeep . datasets import load_adult
df = load_adult ( as_frame = True )
df [ "income_label" ] = ( df [ "income" ]. apply ( lambda x : ">50K" in x )). astype ( int )
df . drop ( "income" , axis = 1 , inplace = True )
df_train , df_test = train_test_split ( df , test_size = 0.2 , stratify = df . income_label )
# Define the 'column set up'
wide_cols = [
"education" ,
"relationship" ,
"workclass" ,
"occupation" ,
"native-country" ,
"gender" ,
]
crossed_cols = [( "education" , "occupation" ), ( "native-country" , "occupation" )]
cat_embed_cols = [
"workclass" ,
"education" ,
"marital-status" ,
"occupation" ,
"relationship" ,
"race" ,
"gender" ,
"capital-gain" ,
"capital-loss" ,
"native-country" ,
]
continuous_cols = [ "age" , "hours-per-week" ]
target = "income_label"
target = df_train [ target ]. values
# prepare the data
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df_train )
tab_preprocessor = TabPreprocessor (
cat_embed_cols = cat_embed_cols , continuous_cols = continuous_cols # type: ignore[arg-type]
)
X_tab = tab_preprocessor . fit_transform ( df_train )
# build the model
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ], pred_dim = 1 )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = continuous_cols ,
)
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# train and validate
trainer = Trainer ( model , objective = "binary" , metrics = [ Accuracy ])
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = target ,
n_epochs = 5 ,
batch_size = 256 ,
)
# predict on test
X_wide_te = wide_preprocessor . transform ( df_test )
X_tab_te = tab_preprocessor . transform ( df_test )
preds = trainer . predict ( X_wide = X_wide_te , X_tab = X_tab_te )
# Save and load
# Option 1: this will also save training history and lr history if the
# LRHistory callback is used
trainer . save ( path = "model_weights" , save_state_dict = True )
# Option 2: save as any other torch model
torch . save ( model . state_dict (), "model_weights/wd_model.pt" )
# From here in advance, Option 1 or 2 are the same. I assume the user has
# prepared the data and defined the new model components:
# 1. Build the model
model_new = WideDeep ( wide = wide , deeptabular = tab_mlp )
model_new . load_state_dict ( torch . load ( "model_weights/wd_model.pt" ))
# 2. Instantiate the trainer
trainer_new = Trainer ( model_new , objective = "binary" )
# 3. Either start the fit or directly predict
preds = trainer_new . predict ( X_wide = X_wide , X_tab = X_tab , batch_size = 32 )Natürlich kann man viel mehr tun. Siehe den Beispiele -Ordner, die Dokumentation oder die Begleitposts, um den Inhalt des Pakets und seiner Funktionen besser zu verstehen.
pytest tests
Überprüfen Sie die beitragende Seite.
Diese Bibliothek stammt aus einer Reihe anderer Bibliotheken, daher denke ich, dass es einfach fair ist, sie hier im Readme zu erwähnen (spezifische Erwähnungen sind auch im Code enthalten).
Die Struktur und Code in Callbacks und Initializers sind von der torchsample -Bibliothek inspiriert, die an sich teilweise von Keras inspiriert ist.
Die TextProcessor in dieser Bibliothek verwendet den fastai Tokenizer und Vocab . Der Code bei utils.fastai_transforms ist eine geringfügige Anpassung ihres Codes, sodass er in dieser Bibliothek funktioniert. Nach meiner Erfahrung ist ihr Tokenizer der beste der Unterricht.
Die ImageProcessor -Klasse in dieser Bibliothek verwendet Code aus dem Fantastic Deep Learning for Computer Vision (DL4CV) -Buch von Adrian Rosebrock.
Diese Arbeit ist unter Apache 2.0 und MIT (oder einer beliebigen späteren Version) doppelt lizenziert. Sie können zwischen einem von ihnen wählen, wenn Sie diese Arbeit verwenden.
SPDX-License-Identifier: Apache-2.0 AND MIT
@article{Zaurin_pytorch-widedeep_A_flexible_2023,
author = {Zaurin, Javier Rodriguez and Mulinka, Pavol},
doi = {10.21105/joss.05027},
journal = {Journal of Open Source Software},
month = jun,
number = {86},
pages = {5027},
title = {{pytorch-widedeep: A flexible package for multimodal deep learning}},
url = {https://joss.theoj.org/papers/10.21105/joss.05027},
volume = {8},
year = {2023}
}
Zaurin, J. R., & Mulinka, P. (2023). pytorch-widedeep: A flexible package for
multimodal deep learning. Journal of Open Source Software, 8(86), 5027.
https://doi.org/10.21105/joss.05027


