pytorch widedeep
mps backend support and more rec models
멀티 모달-깊은 학습을위한 유연한 패키지, 표식 데이터를 텍스트 및 이미지를 Pytorch의 넓고 깊은 모델을 사용하여 텍스트 및 이미지와 결합합니다.
문서 : https://pytorch-widepeep.readthedocs.io
동반자 게시물 및 튜토리얼 : Infinitoml
LightGBM 과의 실험 및 비교 : Tabulardl vs LightgBM
Slack : 기여하고 싶거나 우리와 채팅하고 싶다면 Slack에 가입하십시오.
이 문서의 내용은 다음과 같이 구성됩니다.
deeptabular 성분rec 모듈 pytorch-widedeep 멀티 모달 데이터 세트에 맞게 조정 된 Google의 넓고 깊은 알고리즘을 기반으로합니다.
일반적으로 pytorch-widedeep 표 형성 데이터와 함께 딥 러닝을 사용하는 패키지입니다. 특히, 넓고 깊은 모델을 사용하여 텍스트와 이미지의 조합을 해당 테이블 데이터와 조합하기위한 것입니다. 이를 염두에두고 라이브러리와 함께 구현할 수있는 많은 아키텍처가 있습니다. 해당 아키텍처의 주요 구성 요소는 아래 그림에 나와 있습니다.
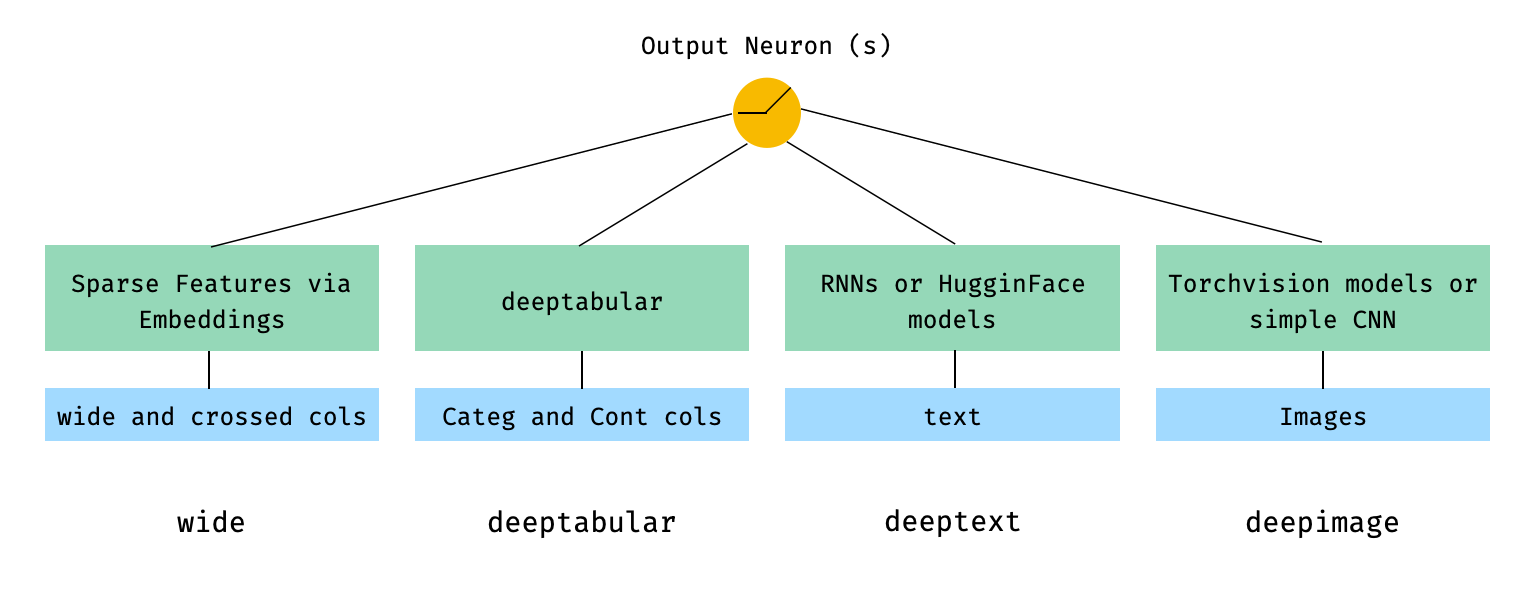
수학 용어와 논문의 표기법에 따라 deephead 구성 요소가없는 아키텍처 표현식은 다음과 같이 공식화 될 수 있습니다.
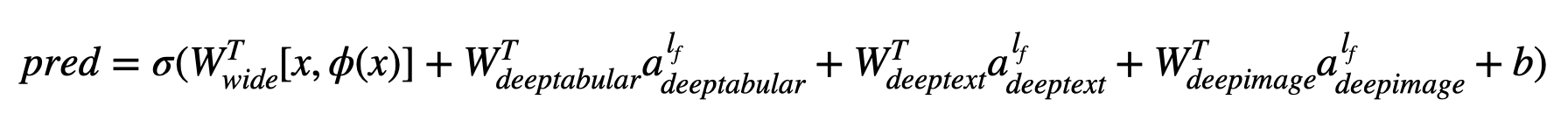
σ가 시그 모이 드 함수 인 경우, 'w' 는 넓은 모델과 깊은 모델 의 최종 활성화 에 적용되는 중량 행렬입니다. "크로스 제품 변환" 이 무엇인지 궁금해하는 경우, 여기에 논문에서 직접 인용 한 인용문 이 있습니다. "이진 기능의 경우"교차 제품 변환 ( "및 (gender = female, langu
사용자 정의 모델이 마지막 활성화 계층의 크기를 가진 output_dim WideDeep 속성을 갖는 한 사용자 정의 모델 (반드시 라이브러리의 것은 아님)을 사용하는 것이 완벽하게 가능합니다. 사용자 정의 구성 요소 사용 방법에 대한 예는 예제 폴더와 아래 섹션에서 찾을 수 있습니다.
pytorch-widedeep 라이브러리는 여러 가지 다른 아키텍처를 제공합니다. 이 섹션에서는 해당 코드 스 니펫으로 가장 간단한 형태 (예 : 대부분의 경우 기본 매개 변수 값이있는)로 일부를 표시합니다. Shoud 아래의 모든 스 니펫은 로컬로 실행됩니다. 다른 구성 요소와 그 매개 변수에 대한 자세한 설명은 문서를 참조하십시오.
아래 예제의 경우 다음과 같이 생성 된 장난감 데이터 세트를 사용합니다.
import os
import random
import numpy as np
import pandas as pd
from PIL import Image
from faker import Faker
def create_and_save_random_image ( image_number , size = ( 32 , 32 )):
if not os . path . exists ( "images" ):
os . makedirs ( "images" )
array = np . random . randint ( 0 , 256 , ( size [ 0 ], size [ 1 ], 3 ), dtype = np . uint8 )
image = Image . fromarray ( array )
image_name = f"image_ { image_number } .png"
image . save ( os . path . join ( "images" , image_name ))
return image_name
fake = Faker ()
cities = [ "New York" , "Los Angeles" , "Chicago" , "Houston" ]
names = [ "Alice" , "Bob" , "Charlie" , "David" , "Eva" ]
data = {
"city" : [ random . choice ( cities ) for _ in range ( 100 )],
"name" : [ random . choice ( names ) for _ in range ( 100 )],
"age" : [ random . uniform ( 18 , 70 ) for _ in range ( 100 )],
"height" : [ random . uniform ( 150 , 200 ) for _ in range ( 100 )],
"sentence" : [ fake . sentence () for _ in range ( 100 )],
"other_sentence" : [ fake . sentence () for _ in range ( 100 )],
"image_name" : [ create_and_save_random_image ( i ) for i in range ( 100 )],
"target" : [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )],
}
df = pd . DataFrame ( data ) 이렇게하면 100 개의 행 데이터 프레임과 로컬 폴더의 DIR을 생성합니다. images 는 100 개의 임의의 이미지 (또는 소음이있는 이미지)를 가진 이미지를 만듭니다.
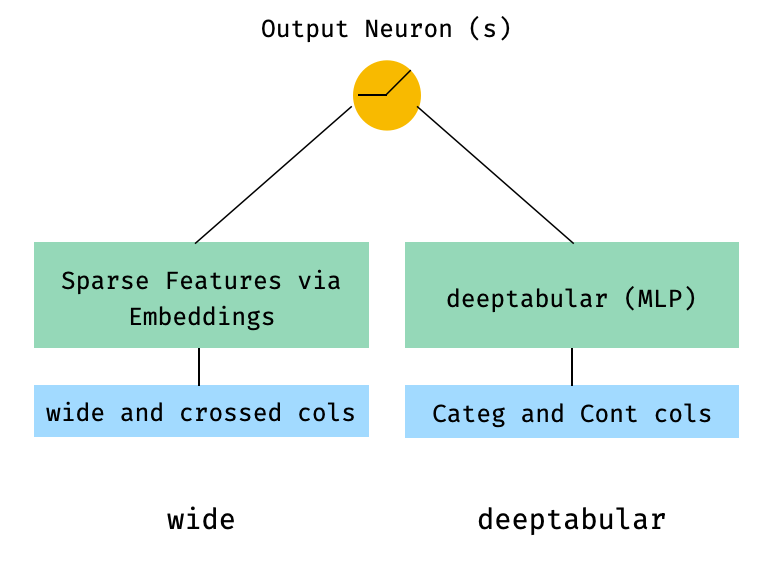
아마도 가장 간단한 아키텍처는 하나의 구성 요소 일 뿐이며, wide , deeptabular , deeptext 또는 deepimage 자체 일 뿐이므로, 또한 가능하지만 표준 넓고 깊은 아키텍처로 예제를 시작합시다. 거기에서 하나의 구성 요소로만 구성된 모델을 구축하는 방법은 간단합니다.
아래에 표시된 예제는 라이브러리에서 사용 가능한 모든 모델을 사용하여 거의 동일합니다. 예를 들어, TabMlp TabResnet , TabNet , TabTransformer 등으로 대체 할 수 있습니다. 마찬가지로, BasicRNN Heenging Face 모델의 경우 해당 매개 변수 및 전처리로 AttentiveRNN , StackedAttentiveRNN 또는 HFModel 로 대체 될 수 있습니다.
1. 넓고 표 성 구성 요소 (일명 심해)
from pytorch_widedeep . preprocessing import TabPreprocessor , WidePreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . training import Trainer
# Wide
wide_cols = [ "city" ]
crossed_cols = [( "city" , "name" )]
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df )
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ])
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# WideDeep
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)2. 표 및 텍스트 데이터
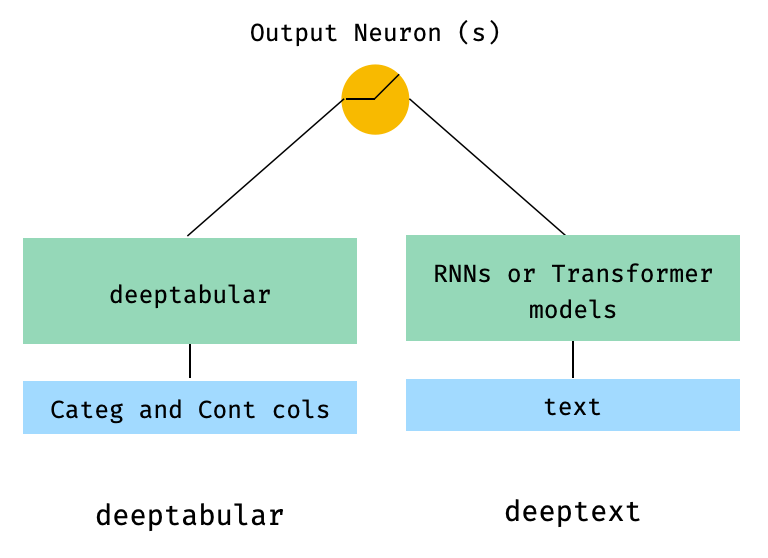
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 3. WideDeep 의 head_hidden_dims Param을 통해 FC 헤드가있는 표 및 텍스트
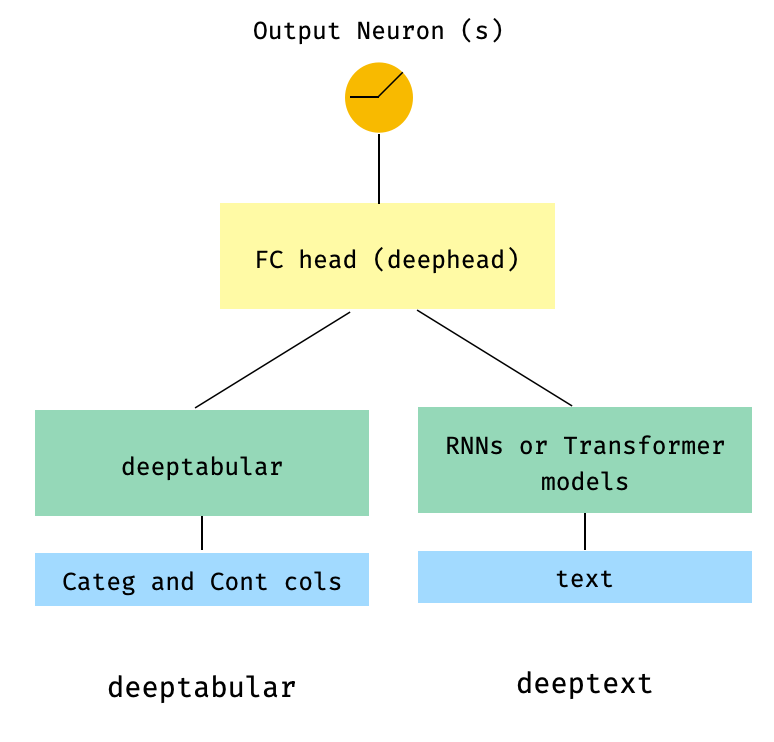
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn , head_hidden_dims = [ 32 , 16 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 4. WideDeep 로 직접 전달되는 표 및 다중 텍스트 열
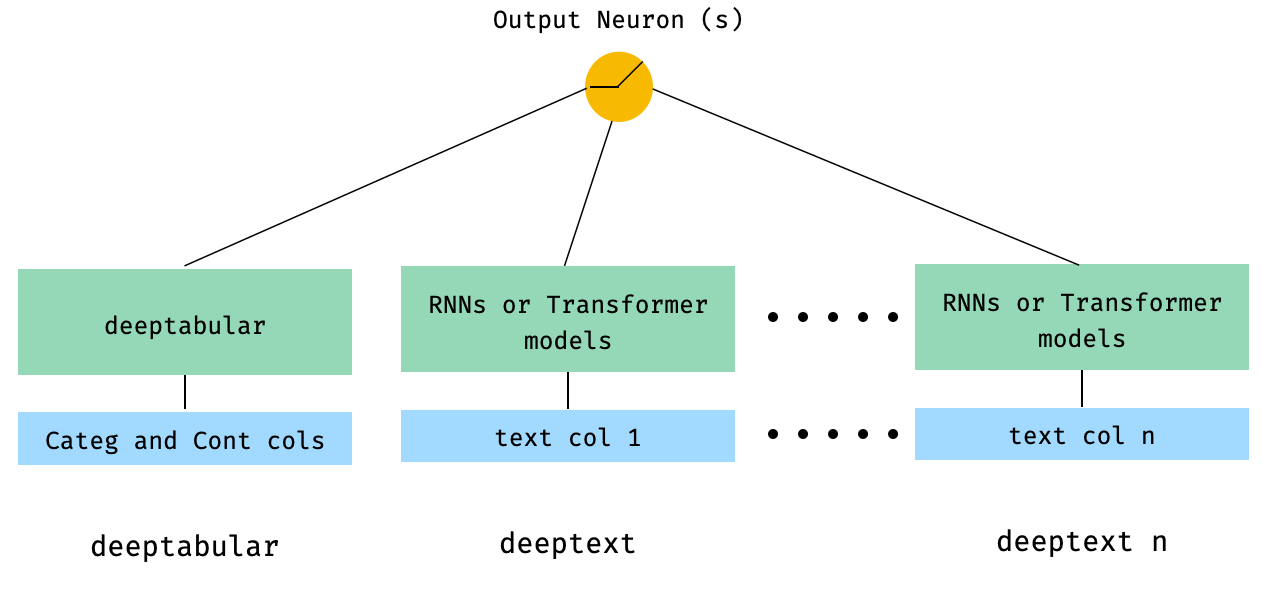
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = [ rnn_1 , rnn_2 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 5. 도서관의 ModelFuser 클래스를 통해 융합 된 표 형 데이터 및 여러 텍스트 열
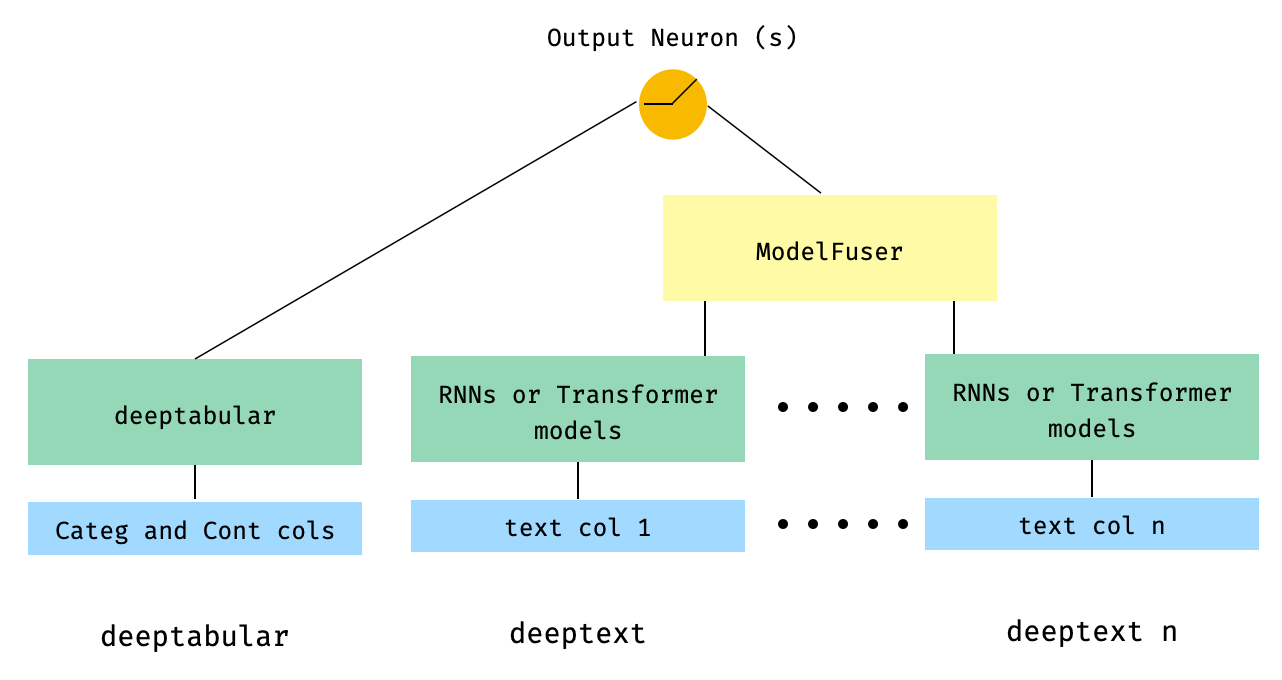
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser ( models = [ rnn_1 , rnn_2 ], fusion_method = "mult" )
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = models_fuser )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
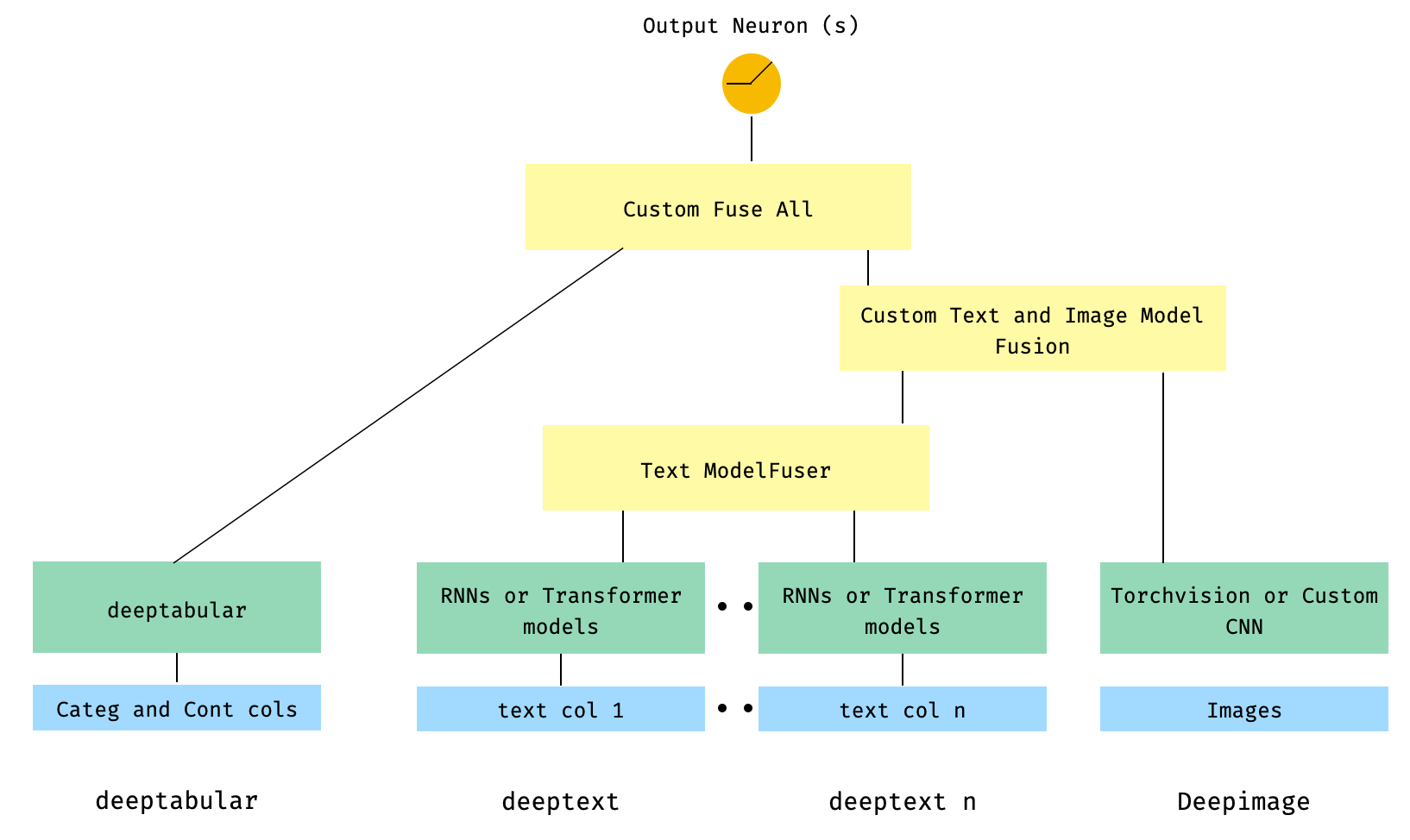
) 6. 이미지 열이있는 표 및 다중 텍스트 열. 텍스트 열은 라이브러리의 ModelFuser 통해 융합 된 다음 WideDeep 의 Deephead Paramenter를 통해 융합되어 사용자가 코딩 한 사용자 정의 ModelFuser 입니다.
이것은 사용자의 사용자 지정 구성 요소를 포함하고 '들어오는'텐서를 슬라이싱하기 때문에 우아한 솔루션 일 것입니다. 앞으로이 과정을보다 간단하게 만들기 위해 TextAndImageModelFuser 포함 할 것입니다. 그럼에도 불구하고 실제로 복잡하지 않으며 pytorch-widedeep 에서 사용자 정의 구성 요소를 사용하는 방법의 좋은 예입니다.
사용자 정의 구성 요소의 유일한 요구 사항은 마지막 활성화 계층의 크기를 반환하는 output_dim 이라는 속성이 있다는 것입니다. 다시 말해, BaseWDModelComponent 에서 상속받을 필요는 없습니다. 이 기본 클래스는 단순히 그러한 속성의 존재를 확인하고 내부적으로 일부 타이핑 오류를 피합니다.
import torch
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 16 , 8 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser (
models = [ rnn_1 , rnn_2 ],
fusion_method = "mult" ,
)
# Image
image_preprocessor = ImagePreprocessor ( img_col = "image_name" , img_path = "images" )
X_img = image_preprocessor . fit_transform ( df )
vision = Vision ( pretrained_model_setup = "resnet18" , head_hidden_dims = [ 16 , 8 ])
# deephead (custom model fuser)
class MyModelFuser ( BaseWDModelComponent ):
"""
Simply a Linear + Relu sequence on top of the text + images followed by a
Linear -> Relu -> Linear for the concatenation of tabular slice of the
tensor and the output of the text and image sequential model
"""
def __init__ (
self ,
tab_incoming_dim : int ,
text_incoming_dim : int ,
image_incoming_dim : int ,
output_units : int ,
):
super ( MyModelFuser , self ). __init__ ()
self . tab_incoming_dim = tab_incoming_dim
self . text_incoming_dim = text_incoming_dim
self . image_incoming_dim = image_incoming_dim
self . output_units = output_units
self . text_and_image_fuser = torch . nn . Sequential (
torch . nn . Linear ( text_incoming_dim + image_incoming_dim , output_units ),
torch . nn . ReLU (),
)
self . out = torch . nn . Sequential (
torch . nn . Linear ( output_units + tab_incoming_dim , output_units * 4 ),
torch . nn . ReLU (),
torch . nn . Linear ( output_units * 4 , output_units ),
)
def forward ( self , X : torch . Tensor ) -> torch . Tensor :
tab_slice = slice ( 0 , self . tab_incoming_dim )
text_slice = slice (
self . tab_incoming_dim , self . tab_incoming_dim + self . text_incoming_dim
)
image_slice = slice (
self . tab_incoming_dim + self . text_incoming_dim ,
self . tab_incoming_dim + self . text_incoming_dim + self . image_incoming_dim ,
)
X_tab = X [:, tab_slice ]
X_text = X [:, text_slice ]
X_img = X [:, image_slice ]
X_text_and_image = self . text_and_image_fuser ( torch . cat ([ X_text , X_img ], dim = 1 ))
return self . out ( torch . cat ([ X_tab , X_text_and_image ], dim = 1 ))
@ property
def output_dim ( self ):
return self . output_units
deephead = MyModelFuser (
tab_incoming_dim = tab_mlp . output_dim ,
text_incoming_dim = models_fuser . output_dim ,
image_incoming_dim = vision . output_dim ,
output_units = 8 ,
)
# WideDeep
model = WideDeep (
deeptabular = tab_mlp ,
deeptext = models_fuser ,
deepimage = vision ,
deephead = deephead ,
)
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
X_img = X_img ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)7. 2 타워 모델
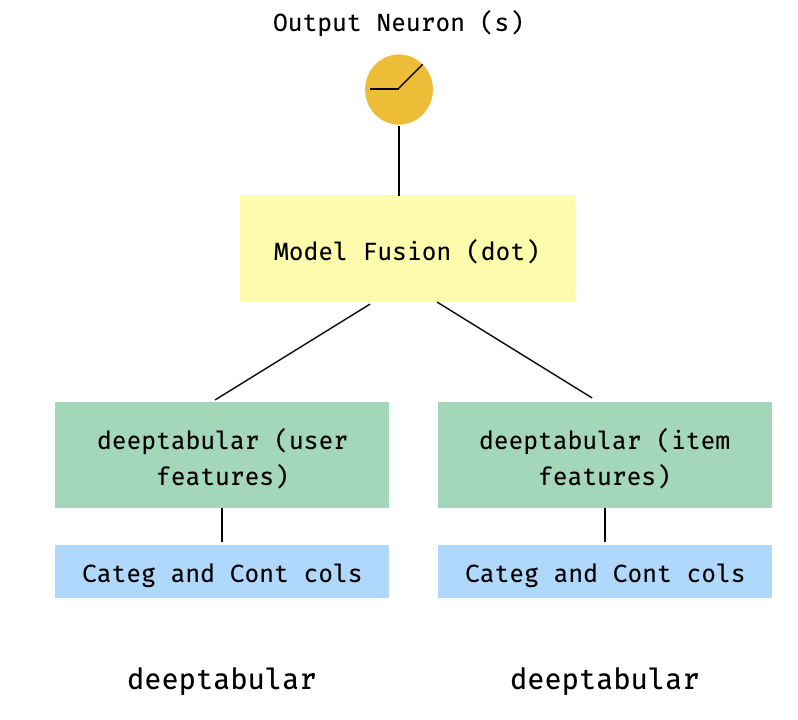
이것은 추천 시스템의 맥락에서 인기있는 모델입니다. 내 트리플 (사용자 기능, 항목 기능, 대상)을 형성 한 테이블 데이터 세트가 있다고 가정 해 봅시다. 사용자 및 항목 기능이 두 개의 개별 모델을 통과 한 다음 도트 제품을 통해 "융합"하는 2 타워 모델을 만들 수 있습니다.
import numpy as np
import pandas as pd
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import TabPreprocessor
from pytorch_widedeep . models import TabMlp , WideDeep , ModelFuser
# Let's create the interaction dataset
# user_features dataframe
np . random . seed ( 42 )
user_ids = np . arange ( 1 , 101 )
ages = np . random . randint ( 18 , 60 , size = 100 )
genders = np . random . choice ([ "male" , "female" ], size = 100 )
locations = np . random . choice ([ "city_a" , "city_b" , "city_c" , "city_d" ], size = 100 )
user_features = pd . DataFrame (
{ "id" : user_ids , "age" : ages , "gender" : genders , "location" : locations }
)
# item_features dataframe
item_ids = np . arange ( 1 , 101 )
prices = np . random . uniform ( 10 , 500 , size = 100 ). round ( 2 )
colors = np . random . choice ([ "red" , "blue" , "green" , "black" ], size = 100 )
categories = np . random . choice ([ "electronics" , "clothing" , "home" , "toys" ], size = 100 )
item_features = pd . DataFrame (
{ "id" : item_ids , "price" : prices , "color" : colors , "category" : categories }
)
# Interactions dataframe
interaction_user_ids = np . random . choice ( user_ids , size = 1000 )
interaction_item_ids = np . random . choice ( item_ids , size = 1000 )
purchased = np . random . choice ([ 0 , 1 ], size = 1000 , p = [ 0.7 , 0.3 ])
interactions = pd . DataFrame (
{
"user_id" : interaction_user_ids ,
"item_id" : interaction_item_ids ,
"purchased" : purchased ,
}
)
user_item_purchased = interactions . merge (
user_features , left_on = "user_id" , right_on = "id"
). merge ( item_features , left_on = "item_id" , right_on = "id" )
# Users
tab_preprocessor_user = TabPreprocessor (
cat_embed_cols = [ "gender" , "location" ],
continuous_cols = [ "age" ],
)
X_user = tab_preprocessor_user . fit_transform ( user_item_purchased )
tab_mlp_user = TabMlp (
column_idx = tab_preprocessor_user . column_idx ,
cat_embed_input = tab_preprocessor_user . cat_embed_input ,
continuous_cols = [ "age" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
# Items
tab_preprocessor_item = TabPreprocessor (
cat_embed_cols = [ "color" , "category" ],
continuous_cols = [ "price" ],
)
X_item = tab_preprocessor_item . fit_transform ( user_item_purchased )
tab_mlp_item = TabMlp (
column_idx = tab_preprocessor_item . column_idx ,
cat_embed_input = tab_preprocessor_item . cat_embed_input ,
continuous_cols = [ "price" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
two_tower_model = ModelFuser ([ tab_mlp_user , tab_mlp_item ], fusion_method = "dot" )
model = WideDeep ( deeptabular = two_tower_model )
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = [ X_user , X_item ],
target = interactions . purchased . values ,
n_epochs = 1 ,
batch_size = 32 ,
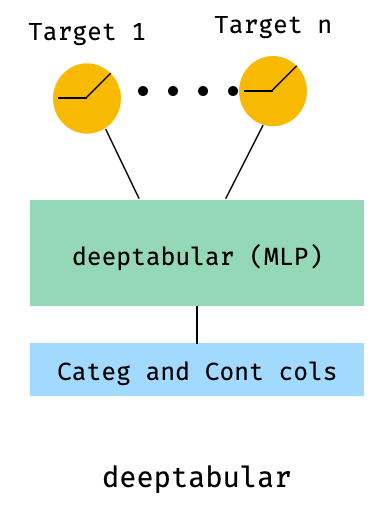
)8. 다중 표적 손실이있는 표
이것은 실제로 다른 아키텍처보다 다중 표적 손실의 사용을 설명하기위한 "보너스"입니다.
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . losses_multitarget import MultiTargetClassificationLoss
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# let's add a second target to the dataframe
df [ "target2" ] = [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )]
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# 'pred_dim=2' because we have two binary targets. For other types of targets,
# please, see the documentation
model = WideDeep ( deeptabular = tab_mlp , pred_dim = 2 ).
loss = MultiTargetClassificationLoss ( binary_config = [ 0 , 1 ], reduction = "mean" )
# When a multi-target loss is used, 'custom_loss_function' must not be None.
# See the docs
trainer = Trainer ( model , objective = "multitarget" , custom_loss_function = loss )
trainer . fit (
X_tab = X_tab ,
target = df [[ "target" , "target2" ]]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)deeptabular 성분 wide , deeptabular , deeptext 및 deepimage 마다 각각의 개별 구성 요소가 독립적으로 그리고 분리 될 수 있음 을 다시 강조하는 것이 중요하다. 예를 들어, 단순히 선형 모델에있는 wide 만 사용할 수 있습니다. 실제로, pytorch-widedeep 에서 가장 흥미로운 기능 중 하나는 자체적으로 deeptabular 성분을 사용하는 것입니다. 현재 pytorch-widedeep 해당 구성 요소에 대해 다음과 같은 모델을 제공합니다.
우리가 호출하는 두 가지 간단한주의 기반 모델 :
Tabformer 패밀리, 즉 테이블 데이터를위한 변압기 :
및 신경망의 중량 불확실성을 기반으로 한 표 데이터에 대한 확률 론적 DL 모델 :
Wide 모델의 확률 적응.TabMlp 모델의 확률 적응Tabtransformer, Saint 및 FT-Transformer를위한 과학 간행물이 있지만 Tabfasfformer 및 TabperCeiver는 표 형식 데이터에 대한 이러한 알고리즘에 대한 우리 자신의 적응입니다.
또한 TabPerceiver 제외하고 모든 deeptabular 모델에 자체 감독 사전 훈련을 사용할 수 있습니다. 자체 감독 사전 훈련은 다음과 같은 두 가지 방법 또는 루틴을 통해 사용할 수 있습니다. 이 기능에 대한 자세한 내용은 문서 및 예제 및 라이브러리의 다른 모든 옵션을 참조하십시오.
rec 모듈이 모듈은 라이브러리의 기존 구성 요소에 대한 확장으로 도입되어 추천 시스템과 관련된 질문 및 문제를 해결했습니다. 여전히 활발한 개발 중이지만 현재 선택된 강력한 추천 모델이 포함되어 있습니다.
이 라이브러리는 이미 기존 구성 요소를 사용하여 다양한 권장 알고리즘의 구현을 지원했다는 점은 주목할 가치가 있습니다. 예를 들어, 라이브러리의 핵심 기능을 사용하여 넓고 깊이, 2 타워 또는 신경 공동 작업 필터링과 같은 모델을 구성 할 수 있습니다.
rec 모듈의 권장 알고리즘은 다음과 같습니다.
이 모델 사용 방법에 대한 자세한 내용은 예제를 참조하십시오.
텍스트 구성 요소 인 deeptext 의 경우 라이브러리는 다음 모델을 제공합니다.
이미지 구성 요소 인 deepimage 의 경우 라이브러리는 다음과 같은 패밀리의 모델을 지원합니다. 이들은 torchvision 통해 제공되며 Vision 클래스에 싸여 있습니다.
PIP를 사용하여 설치 :
pip install pytorch-widedeep또는 Github에서 직접 설치하십시오
pip install git+https://github.com/jrzaurin/pytorch-widedeep.git # Clone the repository
git clone https://github.com/jrzaurin/pytorch-widedeep
cd pytorch-widedeep
# Install in dev mode
pip install -e . 다음은 Wide DeepDense 기본값 설정을 사용하여 성인 데이터 세트를 사용한 이진 분류의 엔드 투 엔드 예입니다.
pytorch-widedeep 있는 넓은 (선형) 및 딥 모델 구축 :
import numpy as np
import torch
from sklearn . model_selection import train_test_split
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import WidePreprocessor , TabPreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . metrics import Accuracy
from pytorch_widedeep . datasets import load_adult
df = load_adult ( as_frame = True )
df [ "income_label" ] = ( df [ "income" ]. apply ( lambda x : ">50K" in x )). astype ( int )
df . drop ( "income" , axis = 1 , inplace = True )
df_train , df_test = train_test_split ( df , test_size = 0.2 , stratify = df . income_label )
# Define the 'column set up'
wide_cols = [
"education" ,
"relationship" ,
"workclass" ,
"occupation" ,
"native-country" ,
"gender" ,
]
crossed_cols = [( "education" , "occupation" ), ( "native-country" , "occupation" )]
cat_embed_cols = [
"workclass" ,
"education" ,
"marital-status" ,
"occupation" ,
"relationship" ,
"race" ,
"gender" ,
"capital-gain" ,
"capital-loss" ,
"native-country" ,
]
continuous_cols = [ "age" , "hours-per-week" ]
target = "income_label"
target = df_train [ target ]. values
# prepare the data
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df_train )
tab_preprocessor = TabPreprocessor (
cat_embed_cols = cat_embed_cols , continuous_cols = continuous_cols # type: ignore[arg-type]
)
X_tab = tab_preprocessor . fit_transform ( df_train )
# build the model
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ], pred_dim = 1 )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = continuous_cols ,
)
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# train and validate
trainer = Trainer ( model , objective = "binary" , metrics = [ Accuracy ])
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = target ,
n_epochs = 5 ,
batch_size = 256 ,
)
# predict on test
X_wide_te = wide_preprocessor . transform ( df_test )
X_tab_te = tab_preprocessor . transform ( df_test )
preds = trainer . predict ( X_wide = X_wide_te , X_tab = X_tab_te )
# Save and load
# Option 1: this will also save training history and lr history if the
# LRHistory callback is used
trainer . save ( path = "model_weights" , save_state_dict = True )
# Option 2: save as any other torch model
torch . save ( model . state_dict (), "model_weights/wd_model.pt" )
# From here in advance, Option 1 or 2 are the same. I assume the user has
# prepared the data and defined the new model components:
# 1. Build the model
model_new = WideDeep ( wide = wide , deeptabular = tab_mlp )
model_new . load_state_dict ( torch . load ( "model_weights/wd_model.pt" ))
# 2. Instantiate the trainer
trainer_new = Trainer ( model_new , objective = "binary" )
# 3. Either start the fit or directly predict
preds = trainer_new . predict ( X_wide = X_wide , X_tab = X_tab , batch_size = 32 )물론, 훨씬 더 많은 일을 할 수 있습니다. 패키지의 내용과 기능을 더 잘 이해하려면 예제 폴더, 문서 또는 동반자 게시물을 참조하십시오.
pytest tests
기여 페이지를 확인하십시오.
이 라이브러리는 일련의 다른 라이브러리에서 가져 오므로 여기에서 ReadMe에서 언급하는 것이 공정하다고 생각합니다 (특정 언급은 코드에도 포함되어 있음).
Callbacks 및 Initializers 구조 및 코드는 torchsample 라이브러리에서 영감을 얻었으며 그 자체로는 Keras 에서 영감을 얻었습니다.
이 라이브러리의 TextProcessor 클래스는 fastai 의 Tokenizer 및 Vocab 사용합니다. utils.fastai_transforms 의 코드는이 라이브러리 내에서 기능하므로 코드의 작은 적응으로 코드를 약간 적응시킵니다. 내 경험에 따르면 그들의 Tokenizer 수업에서 최고입니다.
이 라이브러리의 ImageProcessor 클래스는 Adrian Rosebrock의 환상적인 딥 러닝 (DL4CV) 책의 코드를 사용합니다.
이 작업은 Apache 2.0 및 MIT (또는 이후 버전)에 따라 이중 라이센스입니다. 이 작업을 사용하는 경우 중 하나를 선택할 수 있습니다.
SPDX-License-Identifier: Apache-2.0 AND MIT
@article{Zaurin_pytorch-widedeep_A_flexible_2023,
author = {Zaurin, Javier Rodriguez and Mulinka, Pavol},
doi = {10.21105/joss.05027},
journal = {Journal of Open Source Software},
month = jun,
number = {86},
pages = {5027},
title = {{pytorch-widedeep: A flexible package for multimodal deep learning}},
url = {https://joss.theoj.org/papers/10.21105/joss.05027},
volume = {8},
year = {2023}
}
Zaurin, J. R., & Mulinka, P. (2023). pytorch-widedeep: A flexible package for
multimodal deep learning. Journal of Open Source Software, 8(86), 5027.
https://doi.org/10.21105/joss.05027


