pytorch widedeep
mps backend support and more rec models
حزمة مرنة للتعلم متعدد الوسائط لدمج البيانات الجدولية مع النص والصور باستخدام نماذج واسعة وعميقة في Pytorch
الوثائق: https://pytorch-wideeep.readthedocs.io
المشاركات والدروس التعليمية المصاحبة: Infinitoml
التجارب والمقارنة مع LightGBM : Tabulardl vs LightgBM
الركود : إذا كنت تريد المساهمة أو تريد فقط الدردشة معنا ، انضم إلى Slack
يتم تنظيم محتوى هذا المستند على النحو التالي:
deeptabularrec يعتمد pytorch-widedeep على خوارزمية Google الواسعة والعميقة ، المعدلة لمجموعات البيانات متعددة الوسائط.
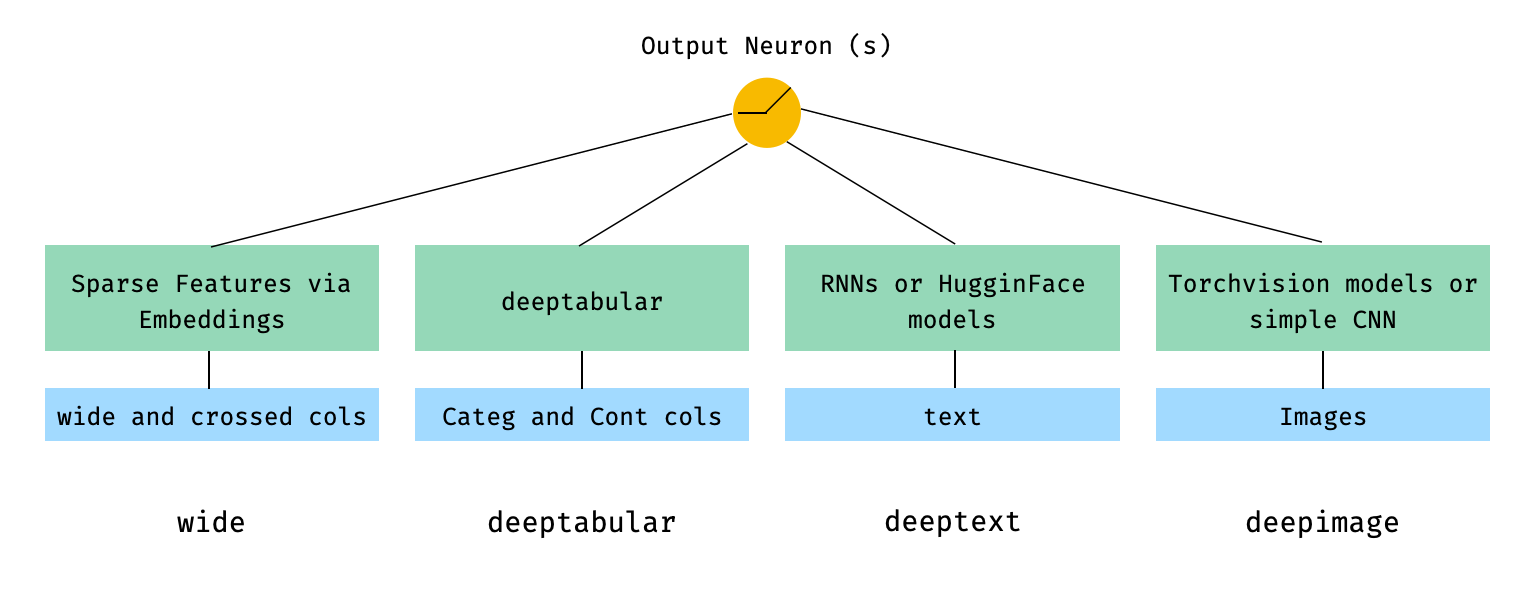
بشكل عام ، تعتبر pytorch-widedeep حزمة لاستخدام التعلم العميق مع البيانات الجدولية. على وجه الخصوص ، يهدف إلى تسهيل مزيج من النص والصور مع البيانات الجدولية المقابلة باستخدام نماذج واسعة وعميقة. مع وضع ذلك في الاعتبار ، هناك عدد من البنى التي يمكن تنفيذها مع المكتبة. تظهر المكونات الرئيسية لتلك البنى في الشكل أدناه:
من حيث الرياضيات ، واتباع الترميز في الورقة ، يمكن صياغة التعبير عن البنية بدون مكون deephead على النحو التالي:
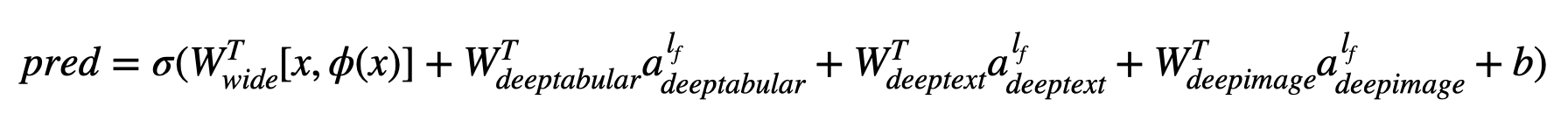
عندما تكون σ هي وظيفة sigmoid ، فإن "W ' هي مصفوفات الوزن المطبقة على النموذج الواسع وإلى التنشيط النهائي للنماذج العميقة ، " A' هذه التنشيطات النهائية ، φ (x) هي تحويلات المنتج المتقاطعة للميزات الأصلية "X" ، و "B" هي مصطلح التحيز. في حال كنت تتساءل ما هي "تحويلات المنتجات المتقاطعة" ، فإليك اقتباس تم التقاطه مباشرة من الورقة: "للميزات الثنائية ، وتحول المنتج المتقاطع (على سبيل المثال ،" و (الجنس = الإناث ، اللغة = EN)) هو 1 إذا وفقط إذا كانت الميزات المكونة ("الجنس = الإناث" و "en") كلها 1 ، و 0 خلاف ذلك ".
من الممكن تمامًا استخدام نماذج مخصصة (وليس بالضرورة تلك الموجودة في المكتبة) طالما أن النماذج المخصصة لها خاصية تسمى output_dim بحجم الطبقة الأخيرة من التنشيط ، بحيث يمكن إنشاء WideDeep . يمكن العثور على أمثلة حول كيفية استخدام المكونات المخصصة في مجلد الأمثلة والقسم أدناه.
تقدم مكتبة pytorch-widedeep عددًا من البنى المختلفة. في هذا القسم ، سنعرض بعضها في أبسط أشكاله (أي مع قيم Param الافتراضية في معظم الحالات) مع قصاصات الكود المقابلة الخاصة بهم. لاحظ أن جميع المقتطفات أسفل shoud تعمل محليا. للحصول على شرح أكثر تفصيلاً للمكونات المختلفة ومعلماتها ، يرجى الرجوع إلى الوثائق.
بالنسبة للأمثلة أدناه ، سنستخدم مجموعة بيانات ألعاب تم إنشاؤها على النحو التالي:
import os
import random
import numpy as np
import pandas as pd
from PIL import Image
from faker import Faker
def create_and_save_random_image ( image_number , size = ( 32 , 32 )):
if not os . path . exists ( "images" ):
os . makedirs ( "images" )
array = np . random . randint ( 0 , 256 , ( size [ 0 ], size [ 1 ], 3 ), dtype = np . uint8 )
image = Image . fromarray ( array )
image_name = f"image_ { image_number } .png"
image . save ( os . path . join ( "images" , image_name ))
return image_name
fake = Faker ()
cities = [ "New York" , "Los Angeles" , "Chicago" , "Houston" ]
names = [ "Alice" , "Bob" , "Charlie" , "David" , "Eva" ]
data = {
"city" : [ random . choice ( cities ) for _ in range ( 100 )],
"name" : [ random . choice ( names ) for _ in range ( 100 )],
"age" : [ random . uniform ( 18 , 70 ) for _ in range ( 100 )],
"height" : [ random . uniform ( 150 , 200 ) for _ in range ( 100 )],
"sentence" : [ fake . sentence () for _ in range ( 100 )],
"other_sentence" : [ fake . sentence () for _ in range ( 100 )],
"image_name" : [ create_and_save_random_image ( i ) for i in range ( 100 )],
"target" : [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )],
}
df = pd . DataFrame ( data ) سيؤدي ذلك إلى إنشاء 100 صفوف بيانات و dir في المجلد المحلي الخاص بك ، يسمى images مع 100 صورة عشوائية (أو صور مع ضوضاء فقط).
ربما تكون أبسط بنية هي مجرد مكون واحد ، wide ، deeptabular ، deeptext أو deepimage من تلقاء نفسه ، وهو أمر ممكن أيضًا ، ولكن لنبدأ الأمثلة مع بنية عريضة وعميقة قياسية. من هناك ، سيكون كيفية إنشاء نموذج يتكون فقط من مكون واحد واضحًا.
لاحظ أن الأمثلة الموضحة أدناه ستكون متطابقة تقريبًا باستخدام أي من النماذج المتوفرة في المكتبة. على سبيل المثال ، يمكن استبدال TabMlp بـ TabResnet و TabNet و TabTransformer ، وما إلى ذلك. وبالمثل ، يمكن استبدال BasicRNN AttentiveRNN أو StackedAttentiveRNN ، أو HFModel مع معلماتها المقابلة والمعالج المسبق في حالة المعانقة.
1. مكون واسع ومكون (ويعرف أيضًا باسم DeepTabular)
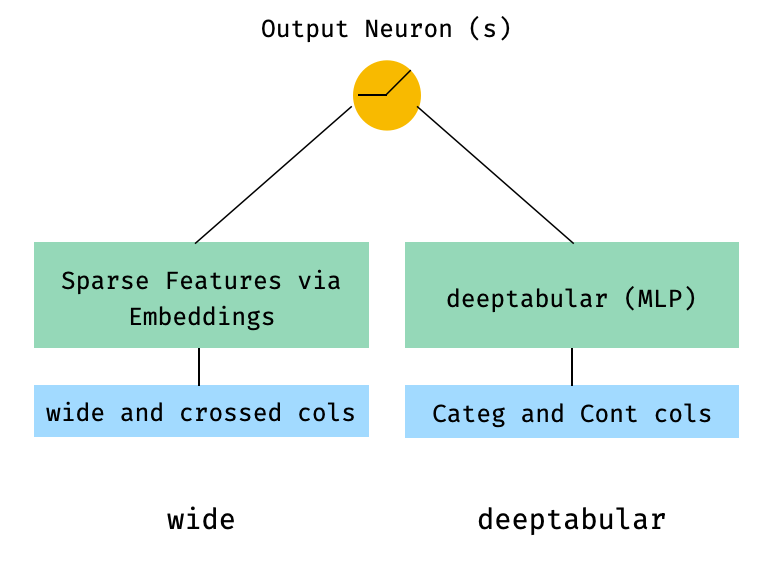
from pytorch_widedeep . preprocessing import TabPreprocessor , WidePreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . training import Trainer
# Wide
wide_cols = [ "city" ]
crossed_cols = [( "city" , "name" )]
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df )
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ])
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# WideDeep
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)2. البيانات الجدولية والنص
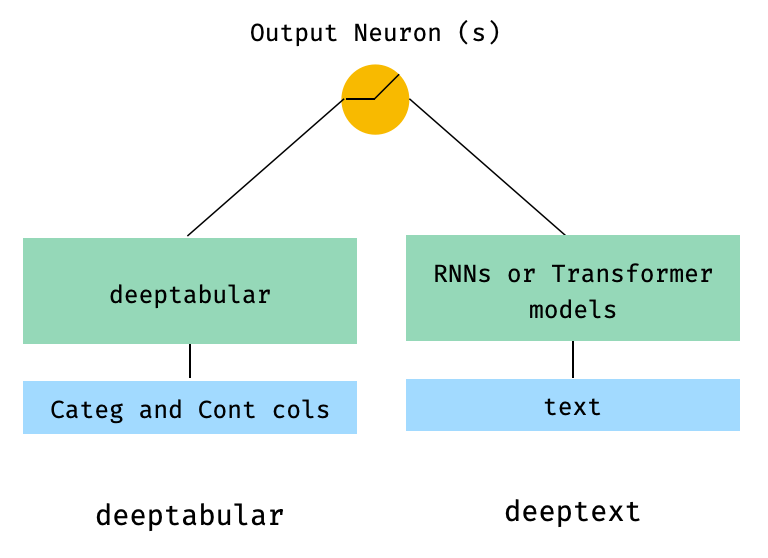
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 3. جدولة ونص برأس FC في الأعلى عبر param head_hidden_dims في WideDeep
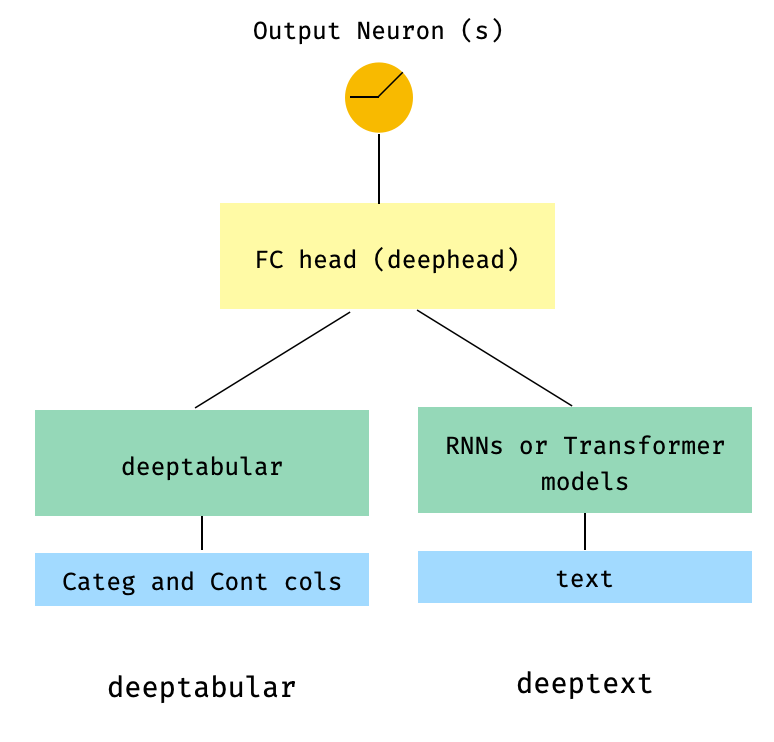
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text = text_preprocessor . fit_transform ( df )
rnn = BasicRNN (
vocab_size = len ( text_preprocessor . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = rnn , head_hidden_dims = [ 32 , 16 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = X_text ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 4. أعمدة نص جدولة ومتعددة يتم تمريرها مباشرة إلى WideDeep
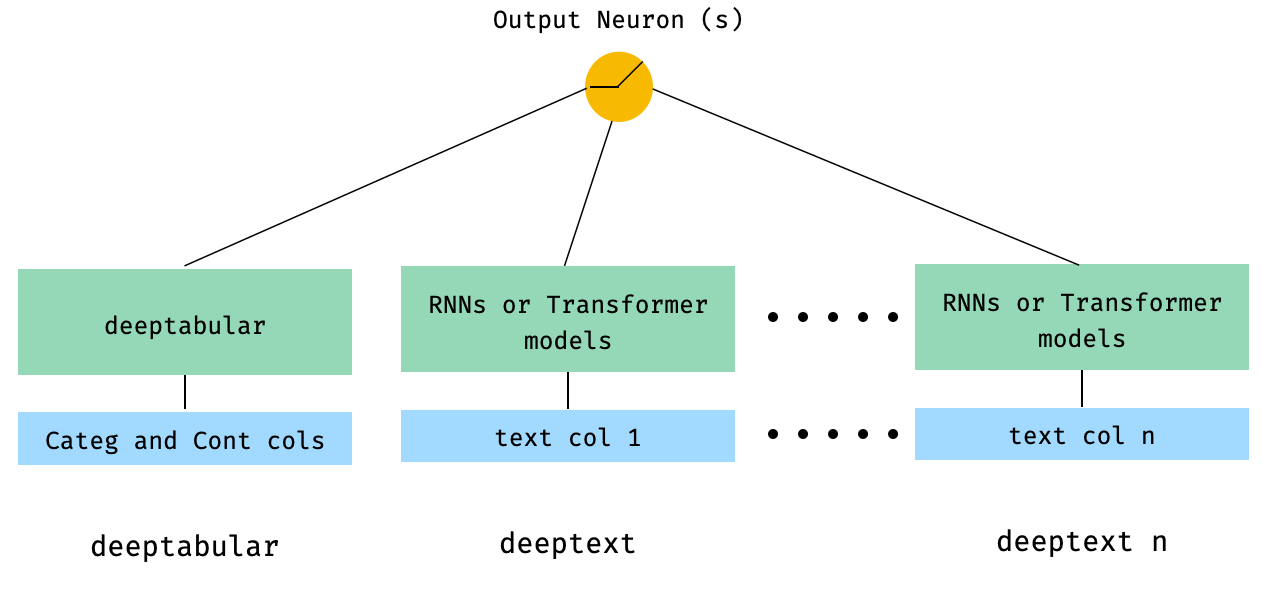
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep
from pytorch_widedeep . training import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = [ rnn_1 , rnn_2 ])
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
) 5. البيانات الجدولية والأعمدة النصية المتعددة التي يتم دمجها عبر فئة ModelFuser للمكتبة
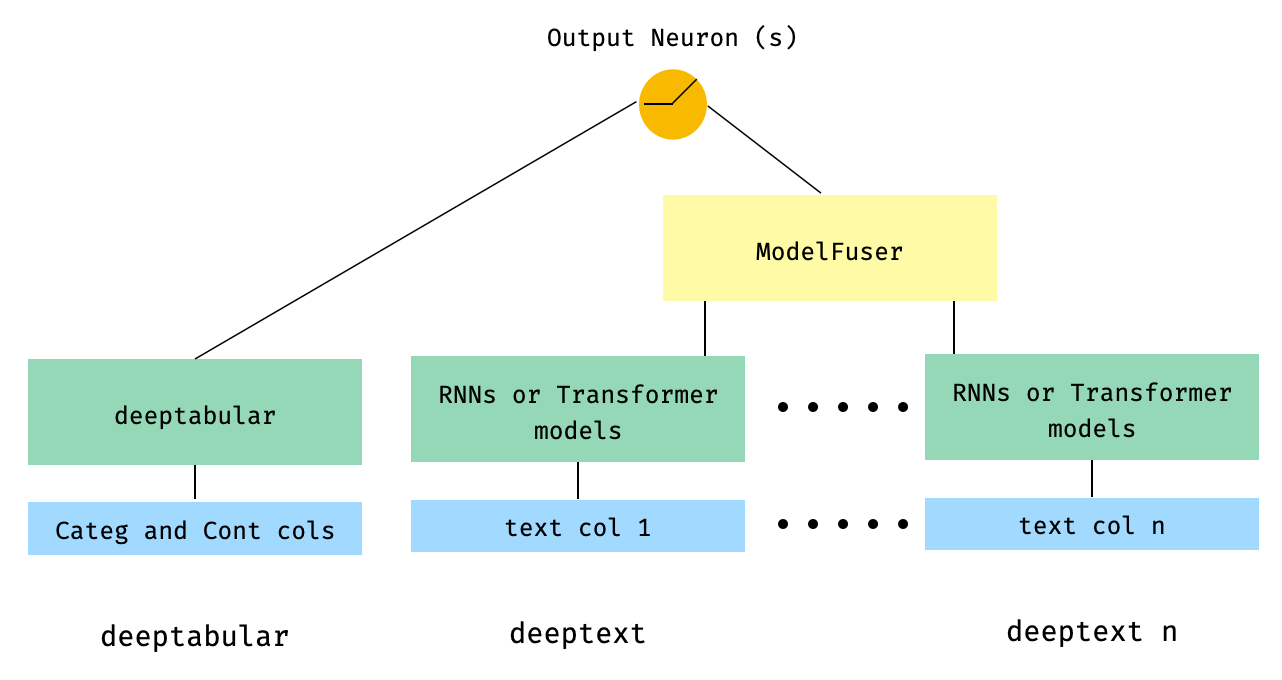
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser ( models = [ rnn_1 , rnn_2 ], fusion_method = "mult" )
# WideDeep
model = WideDeep ( deeptabular = tab_mlp , deeptext = models_fuser )
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
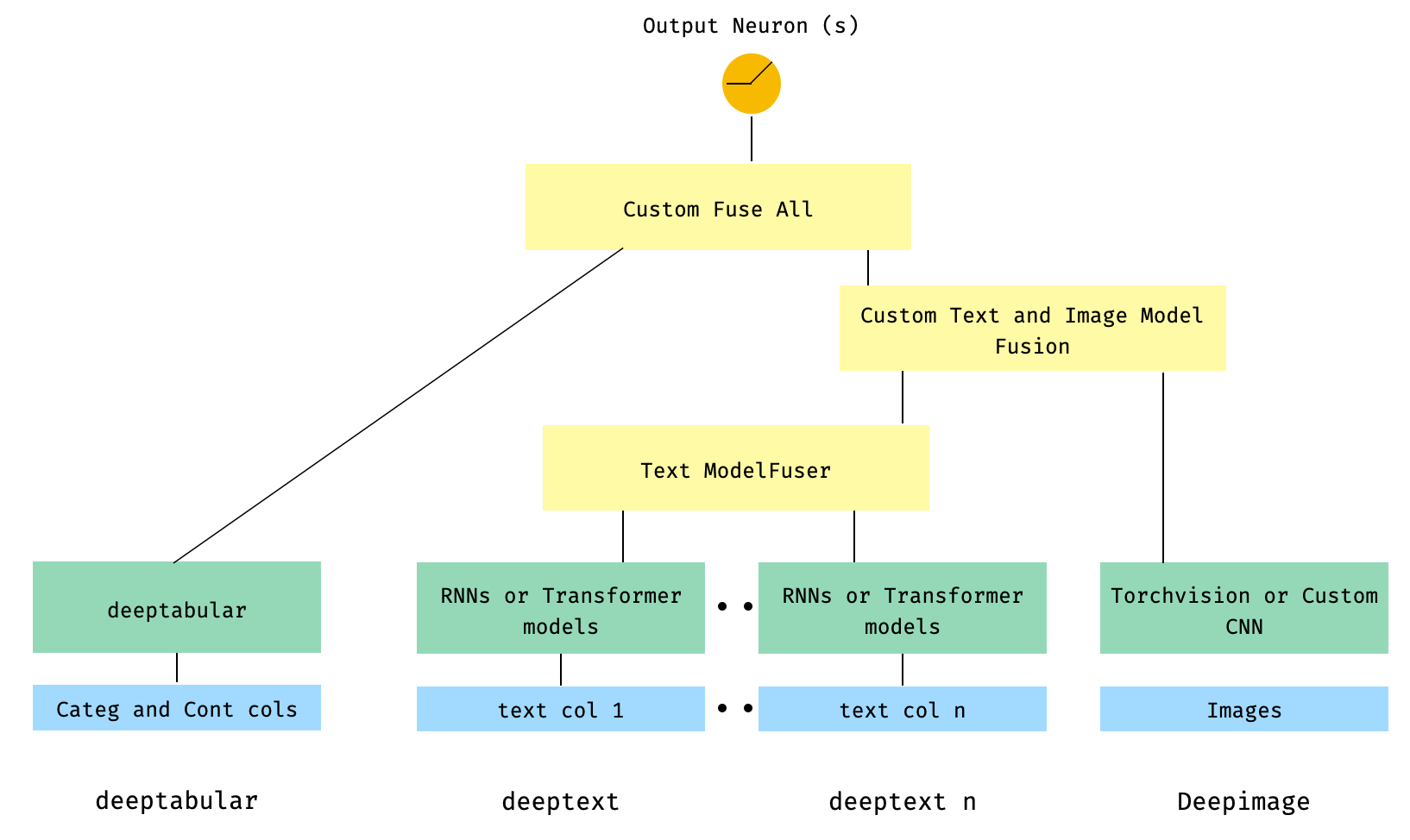
) 6. أعمدة نصية ومتعددة ، مع عمود صورة. يتم دمج أعمدة النص من خلال ModelFuser للمكتبة ومن ثم تنصهر جميعها عبر Deephead Paramenter في WideDeep وهي عبارة عن ModelFuser مخصصة مشفرة بواسطة المستخدم
ربما يكون هذا هو الحل الأقل أناقة لأنه يتضمن مكونًا مخصصًا من قبل المستخدم وتقطيع الموتر "الوارد". في المستقبل ، سنقوم بتضمين TextAndImageModelFuser لجعل هذه العملية أكثر وضوحًا. ومع ذلك ، ليس معقدًا حقًا ، وهو مثال جيد على كيفية استخدام المكونات المخصصة في pytorch-widedeep .
لاحظ أن الشرط الوحيد للمكون المخصص هو أنه يحتوي على خاصية تسمى output_dim التي تُرجع حجم الطبقة الأخيرة من التنشيط. بمعنى آخر ، لا يحتاج إلى أن يرث من BaseWDModelComponent . تتحقق هذه الفئة الأساسية ببساطة من وجود هذه الخاصية وتتجنب بعض أخطاء الكتابة داخليًا.
import torch
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 16 , 8 ],
)
# Text
text_preprocessor_1 = TextPreprocessor (
text_col = "sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_1 = text_preprocessor_1 . fit_transform ( df )
text_preprocessor_2 = TextPreprocessor (
text_col = "other_sentence" , maxlen = 20 , max_vocab = 100 , n_cpus = 1
)
X_text_2 = text_preprocessor_2 . fit_transform ( df )
rnn_1 = BasicRNN (
vocab_size = len ( text_preprocessor_1 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
rnn_2 = BasicRNN (
vocab_size = len ( text_preprocessor_2 . vocab . itos ),
embed_dim = 16 ,
hidden_dim = 8 ,
n_layers = 1 ,
)
models_fuser = ModelFuser (
models = [ rnn_1 , rnn_2 ],
fusion_method = "mult" ,
)
# Image
image_preprocessor = ImagePreprocessor ( img_col = "image_name" , img_path = "images" )
X_img = image_preprocessor . fit_transform ( df )
vision = Vision ( pretrained_model_setup = "resnet18" , head_hidden_dims = [ 16 , 8 ])
# deephead (custom model fuser)
class MyModelFuser ( BaseWDModelComponent ):
"""
Simply a Linear + Relu sequence on top of the text + images followed by a
Linear -> Relu -> Linear for the concatenation of tabular slice of the
tensor and the output of the text and image sequential model
"""
def __init__ (
self ,
tab_incoming_dim : int ,
text_incoming_dim : int ,
image_incoming_dim : int ,
output_units : int ,
):
super ( MyModelFuser , self ). __init__ ()
self . tab_incoming_dim = tab_incoming_dim
self . text_incoming_dim = text_incoming_dim
self . image_incoming_dim = image_incoming_dim
self . output_units = output_units
self . text_and_image_fuser = torch . nn . Sequential (
torch . nn . Linear ( text_incoming_dim + image_incoming_dim , output_units ),
torch . nn . ReLU (),
)
self . out = torch . nn . Sequential (
torch . nn . Linear ( output_units + tab_incoming_dim , output_units * 4 ),
torch . nn . ReLU (),
torch . nn . Linear ( output_units * 4 , output_units ),
)
def forward ( self , X : torch . Tensor ) -> torch . Tensor :
tab_slice = slice ( 0 , self . tab_incoming_dim )
text_slice = slice (
self . tab_incoming_dim , self . tab_incoming_dim + self . text_incoming_dim
)
image_slice = slice (
self . tab_incoming_dim + self . text_incoming_dim ,
self . tab_incoming_dim + self . text_incoming_dim + self . image_incoming_dim ,
)
X_tab = X [:, tab_slice ]
X_text = X [:, text_slice ]
X_img = X [:, image_slice ]
X_text_and_image = self . text_and_image_fuser ( torch . cat ([ X_text , X_img ], dim = 1 ))
return self . out ( torch . cat ([ X_tab , X_text_and_image ], dim = 1 ))
@ property
def output_dim ( self ):
return self . output_units
deephead = MyModelFuser (
tab_incoming_dim = tab_mlp . output_dim ,
text_incoming_dim = models_fuser . output_dim ,
image_incoming_dim = vision . output_dim ,
output_units = 8 ,
)
# WideDeep
model = WideDeep (
deeptabular = tab_mlp ,
deeptext = models_fuser ,
deepimage = vision ,
deephead = deephead ,
)
# Train
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = X_tab ,
X_text = [ X_text_1 , X_text_2 ],
X_img = X_img ,
target = df [ "target" ]. values ,
n_epochs = 1 ,
batch_size = 32 ,
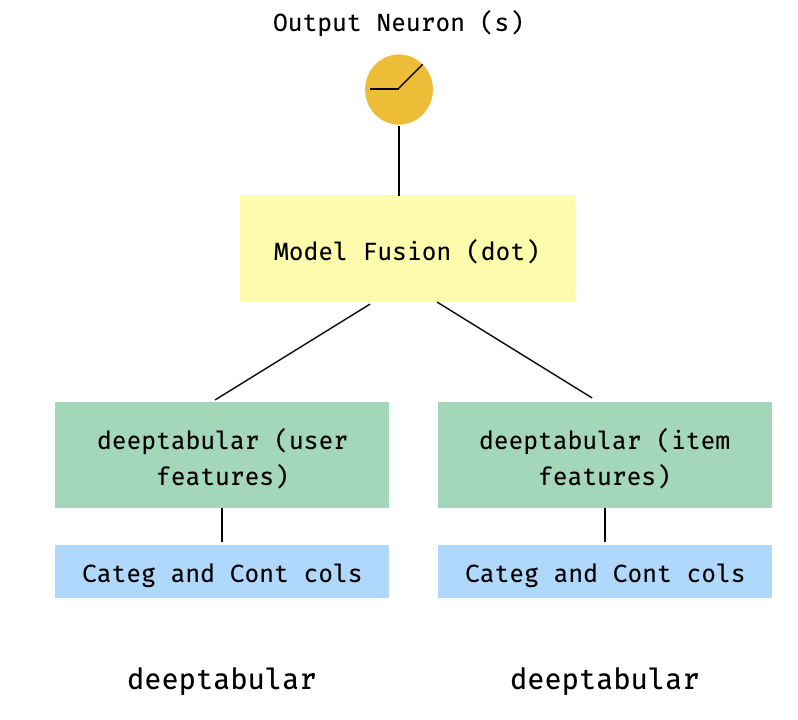
)7. نموذج ذو برجين
هذا نموذج شائع في سياق أنظمة التوصية. دعنا نقول أن لدينا مجموعة بيانات جدولة شكلت ثلاث مرات (ميزات المستخدم ، ميزات العناصر ، الهدف). يمكننا إنشاء نموذج من برجين حيث يتم تمرير ميزات المستخدم والعنصر من خلال نموذجين منفصلين ثم "دمج" عبر منتج DOT.
import numpy as np
import pandas as pd
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import TabPreprocessor
from pytorch_widedeep . models import TabMlp , WideDeep , ModelFuser
# Let's create the interaction dataset
# user_features dataframe
np . random . seed ( 42 )
user_ids = np . arange ( 1 , 101 )
ages = np . random . randint ( 18 , 60 , size = 100 )
genders = np . random . choice ([ "male" , "female" ], size = 100 )
locations = np . random . choice ([ "city_a" , "city_b" , "city_c" , "city_d" ], size = 100 )
user_features = pd . DataFrame (
{ "id" : user_ids , "age" : ages , "gender" : genders , "location" : locations }
)
# item_features dataframe
item_ids = np . arange ( 1 , 101 )
prices = np . random . uniform ( 10 , 500 , size = 100 ). round ( 2 )
colors = np . random . choice ([ "red" , "blue" , "green" , "black" ], size = 100 )
categories = np . random . choice ([ "electronics" , "clothing" , "home" , "toys" ], size = 100 )
item_features = pd . DataFrame (
{ "id" : item_ids , "price" : prices , "color" : colors , "category" : categories }
)
# Interactions dataframe
interaction_user_ids = np . random . choice ( user_ids , size = 1000 )
interaction_item_ids = np . random . choice ( item_ids , size = 1000 )
purchased = np . random . choice ([ 0 , 1 ], size = 1000 , p = [ 0.7 , 0.3 ])
interactions = pd . DataFrame (
{
"user_id" : interaction_user_ids ,
"item_id" : interaction_item_ids ,
"purchased" : purchased ,
}
)
user_item_purchased = interactions . merge (
user_features , left_on = "user_id" , right_on = "id"
). merge ( item_features , left_on = "item_id" , right_on = "id" )
# Users
tab_preprocessor_user = TabPreprocessor (
cat_embed_cols = [ "gender" , "location" ],
continuous_cols = [ "age" ],
)
X_user = tab_preprocessor_user . fit_transform ( user_item_purchased )
tab_mlp_user = TabMlp (
column_idx = tab_preprocessor_user . column_idx ,
cat_embed_input = tab_preprocessor_user . cat_embed_input ,
continuous_cols = [ "age" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
# Items
tab_preprocessor_item = TabPreprocessor (
cat_embed_cols = [ "color" , "category" ],
continuous_cols = [ "price" ],
)
X_item = tab_preprocessor_item . fit_transform ( user_item_purchased )
tab_mlp_item = TabMlp (
column_idx = tab_preprocessor_item . column_idx ,
cat_embed_input = tab_preprocessor_item . cat_embed_input ,
continuous_cols = [ "price" ],
mlp_hidden_dims = [ 16 , 8 ],
mlp_dropout = [ 0.2 , 0.2 ],
)
two_tower_model = ModelFuser ([ tab_mlp_user , tab_mlp_item ], fusion_method = "dot" )
model = WideDeep ( deeptabular = two_tower_model )
trainer = Trainer ( model , objective = "binary" )
trainer . fit (
X_tab = [ X_user , X_item ],
target = interactions . purchased . values ,
n_epochs = 1 ,
batch_size = 32 ,
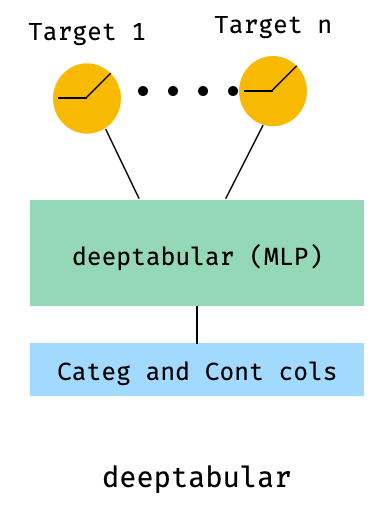
)8. جدولة مع خسارة متعددة الهدف
هذا هو "مكافأة" لتوضيح استخدام الخسائر متعددة الهدف ، أكثر من بنية مختلفة في الواقع.
from pytorch_widedeep . preprocessing import TabPreprocessor , TextPreprocessor , ImagePreprocessor
from pytorch_widedeep . models import TabMlp , BasicRNN , WideDeep , ModelFuser , Vision
from pytorch_widedeep . losses_multitarget import MultiTargetClassificationLoss
from pytorch_widedeep . models . _base_wd_model_component import BaseWDModelComponent
from pytorch_widedeep import Trainer
# let's add a second target to the dataframe
df [ "target2" ] = [ random . choice ([ 0 , 1 ]) for _ in range ( 100 )]
# Tabular
tab_preprocessor = TabPreprocessor (
embed_cols = [ "city" , "name" ], continuous_cols = [ "age" , "height" ]
)
X_tab = tab_preprocessor . fit_transform ( df )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = tab_preprocessor . continuous_cols ,
mlp_hidden_dims = [ 64 , 32 ],
)
# 'pred_dim=2' because we have two binary targets. For other types of targets,
# please, see the documentation
model = WideDeep ( deeptabular = tab_mlp , pred_dim = 2 ).
loss = MultiTargetClassificationLoss ( binary_config = [ 0 , 1 ], reduction = "mean" )
# When a multi-target loss is used, 'custom_loss_function' must not be None.
# See the docs
trainer = Trainer ( model , objective = "multitarget" , custom_loss_function = loss )
trainer . fit (
X_tab = X_tab ,
target = df [[ "target" , "target2" ]]. values ,
n_epochs = 1 ,
batch_size = 32 ,
)deeptabular من المهم التأكيد مرة أخرى على أنه يمكن استخدام كل مكون فردي ، wide ، deeptabular ، deeptext و deepimage ، بشكل مستقل وبشكل عزلة. على سبيل المثال ، يمكن للمرء استخدام wide فقط ، وهو مجرد نموذج خطي. في الواقع ، فإن واحدة من الوظائف الأكثر إثارة للاهتمام في pytorch-widedeep هي استخدام المكون deeptabular من تلقاء نفسه ، أي ما يمكن أن يشير عادة على أنه تعلم عميق للبيانات الجدولية. حاليًا ، يوفر pytorch-widedeep النماذج المختلفة التالية لهذا المكون:
نموذجان مبنيان على الانتباه نسميهما:
عائلة Tabformer ، أي محولات للبيانات الجدولية:
ونماذج DL الاحتمالية للبيانات الجدولية بناءً على عدم اليقين في الوزن في الشبكات العصبية:
Wide .TabMlpلاحظ أنه على الرغم من وجود منشورات علمية لـ TabTransformer و Saint و FT-Transformer ، فإن Tabfasffformer و tabperceiver هي تكييفنا الخاص لتلك الخوارزميات للبيانات الجدولية.
بالإضافة إلى ذلك ، يمكن استخدام التدريب المسبق للإشراف ذاتيًا لجميع النماذج deeptabular ، باستثناء TabPerceiver . يمكن استخدام التدريب المسبق للإشراف ذاتيًا عبر طريقتين أو إجراءات نشير باسم: طريقة التشفير والتشفير وطريقة التخلص من التشفير. يرجى الاطلاع على الوثائق والأمثلة للحصول على تفاصيل حول هذه الوظيفة ، وجميع الخيارات الأخرى في المكتبة.
recتم تقديم هذه الوحدة كملحق للمكونات الموجودة في المكتبة ، معالجة الأسئلة والقضايا المتعلقة بأنظمة التوصية. بينما لا يزال قيد التطوير النشط ، فإنه يتضمن حاليًا عددًا مختارًا من نماذج التوصية القوية.
تجدر الإشارة إلى أن هذه المكتبة دعمت بالفعل تنفيذ خوارزميات التوصية المختلفة باستخدام المكونات الحالية. على سبيل المثال ، يمكن إنشاء نماذج مثل الترشيح التعاوني الواسع والعميق أو الصبر أو العصبي باستخدام وظائف المكتبة الأساسية.
خوارزميات التوصية في وحدة rec هي:
راجع الأمثلة للحصول على تفاصيل حول كيفية استخدام هذه النماذج.
بالنسبة لمكون النص ، deeptext ، تقدم المكتبة النماذج التالية:
بالنسبة لمكون الصورة ، deepimage ، تدعم المكتبة النماذج من العائلات التالية: "Resnet" ، "Shufflenet" ، "Resnext" ، "Wide_Resnet" ، "regnet" ، "Densenet" ، "Mobilenetv3" ، "Mobilenetv2" ، "Mnasnet" ، "Efficiftnet" و "Fiewzenet". يتم تقديم هذه عبر torchvision واختام في فئة Vision .
التثبيت باستخدام PIP:
pip install pytorch-widedeepأو تثبيت مباشرة من جيثب
pip install git+https://github.com/jrzaurin/pytorch-widedeep.git # Clone the repository
git clone https://github.com/jrzaurin/pytorch-widedeep
cd pytorch-widedeep
# Install in dev mode
pip install -e . فيما يلي مثال شامل لتصنيف ثنائي مع مجموعة بيانات البالغين باستخدام إعدادات Wide DeepDense وافتراضات افتراضية.
بناء نموذج عريض (خطي) وعمق مع pytorch-widedeep :
import numpy as np
import torch
from sklearn . model_selection import train_test_split
from pytorch_widedeep import Trainer
from pytorch_widedeep . preprocessing import WidePreprocessor , TabPreprocessor
from pytorch_widedeep . models import Wide , TabMlp , WideDeep
from pytorch_widedeep . metrics import Accuracy
from pytorch_widedeep . datasets import load_adult
df = load_adult ( as_frame = True )
df [ "income_label" ] = ( df [ "income" ]. apply ( lambda x : ">50K" in x )). astype ( int )
df . drop ( "income" , axis = 1 , inplace = True )
df_train , df_test = train_test_split ( df , test_size = 0.2 , stratify = df . income_label )
# Define the 'column set up'
wide_cols = [
"education" ,
"relationship" ,
"workclass" ,
"occupation" ,
"native-country" ,
"gender" ,
]
crossed_cols = [( "education" , "occupation" ), ( "native-country" , "occupation" )]
cat_embed_cols = [
"workclass" ,
"education" ,
"marital-status" ,
"occupation" ,
"relationship" ,
"race" ,
"gender" ,
"capital-gain" ,
"capital-loss" ,
"native-country" ,
]
continuous_cols = [ "age" , "hours-per-week" ]
target = "income_label"
target = df_train [ target ]. values
# prepare the data
wide_preprocessor = WidePreprocessor ( wide_cols = wide_cols , crossed_cols = crossed_cols )
X_wide = wide_preprocessor . fit_transform ( df_train )
tab_preprocessor = TabPreprocessor (
cat_embed_cols = cat_embed_cols , continuous_cols = continuous_cols # type: ignore[arg-type]
)
X_tab = tab_preprocessor . fit_transform ( df_train )
# build the model
wide = Wide ( input_dim = np . unique ( X_wide ). shape [ 0 ], pred_dim = 1 )
tab_mlp = TabMlp (
column_idx = tab_preprocessor . column_idx ,
cat_embed_input = tab_preprocessor . cat_embed_input ,
continuous_cols = continuous_cols ,
)
model = WideDeep ( wide = wide , deeptabular = tab_mlp )
# train and validate
trainer = Trainer ( model , objective = "binary" , metrics = [ Accuracy ])
trainer . fit (
X_wide = X_wide ,
X_tab = X_tab ,
target = target ,
n_epochs = 5 ,
batch_size = 256 ,
)
# predict on test
X_wide_te = wide_preprocessor . transform ( df_test )
X_tab_te = tab_preprocessor . transform ( df_test )
preds = trainer . predict ( X_wide = X_wide_te , X_tab = X_tab_te )
# Save and load
# Option 1: this will also save training history and lr history if the
# LRHistory callback is used
trainer . save ( path = "model_weights" , save_state_dict = True )
# Option 2: save as any other torch model
torch . save ( model . state_dict (), "model_weights/wd_model.pt" )
# From here in advance, Option 1 or 2 are the same. I assume the user has
# prepared the data and defined the new model components:
# 1. Build the model
model_new = WideDeep ( wide = wide , deeptabular = tab_mlp )
model_new . load_state_dict ( torch . load ( "model_weights/wd_model.pt" ))
# 2. Instantiate the trainer
trainer_new = Trainer ( model_new , objective = "binary" )
# 3. Either start the fit or directly predict
preds = trainer_new . predict ( X_wide = X_wide , X_tab = X_tab , batch_size = 32 )بالطبع ، يمكن للمرء أن يفعل أكثر من ذلك بكثير . راجع مجلد الأمثلة أو الوثائق أو المنشورات المصاحبة لفهم أفضل لمحتوى الحزمة ووظائفها.
pytest tests
تحقق من صفحة المساهمة.
تأخذ هذه المكتبة من سلسلة من المكتبات الأخرى ، لذلك أعتقد أنه من العدل أن أذكرها هنا في ReadMe (يتم تضمين الإشارات المحددة أيضًا في الكود).
يستوحى هيكل Callbacks Initializers والرمز من مكتبة torchsample ، والتي في حد ذاتها مستوحاة جزئيًا من Keras .
يستخدم فئة TextProcessor في هذه المكتبة Tokenizer fastai و Vocab . الكود في utils.fastai_transforms هو تكيف بسيط لرمزهم بحيث يعمل داخل هذه المكتبة. Tokenizer هو الأفضل في الفصل.
تستخدم فئة ImageProcessor في هذه المكتبة رمزًا من كتاب التعلم العميق الرائع لرؤية الكمبيوتر (DL4CV) من تأليف Adrian Rosebrock.
هذا العمل مرخص له مزدوج تحت Apache 2.0 و MIT (أو أي إصدار لاحق). يمكنك الاختيار بين واحد منهم إذا كنت تستخدم هذا العمل.
SPDX-License-Identifier: Apache-2.0 AND MIT
@article{Zaurin_pytorch-widedeep_A_flexible_2023,
author = {Zaurin, Javier Rodriguez and Mulinka, Pavol},
doi = {10.21105/joss.05027},
journal = {Journal of Open Source Software},
month = jun,
number = {86},
pages = {5027},
title = {{pytorch-widedeep: A flexible package for multimodal deep learning}},
url = {https://joss.theoj.org/papers/10.21105/joss.05027},
volume = {8},
year = {2023}
}
Zaurin, J. R., & Mulinka, P. (2023). pytorch-widedeep: A flexible package for
multimodal deep learning. Journal of Open Source Software, 8(86), 5027.
https://doi.org/10.21105/joss.05027


