pytorch ts
Version 0.6.0
Pytorchts เป็นกรอบการพยากรณ์เวลาของ Pytorch Pytorch ซึ่งให้แบบจำลองอนุกรมเวลา Pytorch ที่ทันสมัยโดยใช้ Gluonts เป็น API แบ็คเอนด์และสำหรับการโหลดการแปลงและชุดข้อมูลอนุกรมเวลาทดสอบย้อนกลับ
$ pip3 install pytorchts
ที่นี่เราเน้นการเปลี่ยนแปลง API ผ่าน Gluonts ReadMe
import matplotlib . pyplot as plt
import pandas as pd
import torch
from gluonts . dataset . common import ListDataset
from gluonts . dataset . util import to_pandas
from pts . model . deepar import DeepAREstimator
from pts import Trainerตัวอย่างง่ายๆนี้แสดงวิธีการฝึกอบรมแบบจำลองข้อมูลบางอย่างจากนั้นใช้เพื่อทำการคาดการณ์ เป็นขั้นตอนแรกเราต้องรวบรวมข้อมูลบางอย่าง: ในตัวอย่างนี้เราจะใช้ปริมาณทวีตที่กล่าวถึงสัญลักษณ์ Ticker AMZN
url = "https://raw.githubusercontent.com/numenta/NAB/master/data/realTweets/Twitter_volume_AMZN.csv"
df = pd . read_csv ( url , header = 0 , index_col = 0 , parse_dates = True )จุดข้อมูล 100 จุดแรกมีลักษณะดังนี้:
df [: 100 ]. plot ( linewidth = 2 )
plt . grid ( which = 'both' )
plt . show ()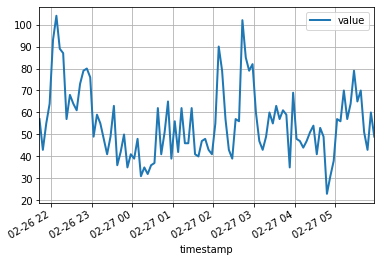
ตอนนี้เราสามารถเตรียมชุดข้อมูลการฝึกอบรมสำหรับแบบจำลองของเราเพื่อฝึกอบรม ชุดข้อมูลเป็นคอลเลกชันที่ทำซ้ำได้ของพจนานุกรม: แต่ละพจนานุกรมแสดงถึงอนุกรมเวลาที่มีคุณสมบัติที่เกี่ยวข้อง สำหรับตัวอย่างนี้เรามีเพียงรายการเดียวที่ระบุโดยฟิลด์ "start" ซึ่งเป็นเวลาเวลาของจุดข้อมูลแรกและฟิลด์ "target" ที่มีข้อมูลอนุกรมเวลา สำหรับการฝึกอบรมเราจะใช้ข้อมูลจนถึงเที่ยงคืนของวันที่ 5 เมษายน 2558
training_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-05 00:00:00" ]}],
freq = "5min"
) รูปแบบการพยากรณ์เป็นวัตถุ ทำนาย วิธีหนึ่งในการรับตัวทำนายคือการฝึกอบรมตัวประมาณผู้สื่อข่าว อินสแตนซ์อินสแตนซ์ตัวประมาณต้องระบุความถี่ของอนุกรมเวลาที่จะจัดการเช่นเดียวกับจำนวนขั้นตอนเวลาในการทำนาย ในตัวอย่างของเราเราใช้ข้อมูล 5 นาทีดังนั้น req="5min" และเราจะฝึกอบรมแบบจำลองเพื่อทำนายชั่วโมงถัดไปดังนั้น prediction_length=12 อินพุตไปยังรุ่นจะเป็นเวกเตอร์ของขนาด input_size=43 ในแต่ละช่วงเวลา นอกจากนี้เรายังระบุตัวเลือกการฝึกอบรมขั้นต่ำในการฝึกอบรมโดยเฉพาะบน device สำหรับ epoch=10
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
estimator = DeepAREstimator ( freq = "5min" ,
prediction_length = 12 ,
input_size = 19 ,
trainer = Trainer ( epochs = 10 ,
device = device ))
predictor = estimator . train ( training_data = training_data , num_workers = 4 ) 45it [00:01, 37.60it/s, avg_epoch_loss=4.64, epoch=0]
48it [00:01, 39.56it/s, avg_epoch_loss=4.2, epoch=1]
45it [00:01, 38.11it/s, avg_epoch_loss=4.1, epoch=2]
43it [00:01, 36.29it/s, avg_epoch_loss=4.05, epoch=3]
44it [00:01, 35.98it/s, avg_epoch_loss=4.03, epoch=4]
48it [00:01, 39.48it/s, avg_epoch_loss=4.01, epoch=5]
48it [00:01, 38.65it/s, avg_epoch_loss=4, epoch=6]
46it [00:01, 37.12it/s, avg_epoch_loss=3.99, epoch=7]
48it [00:01, 38.86it/s, avg_epoch_loss=3.98, epoch=8]
48it [00:01, 39.49it/s, avg_epoch_loss=3.97, epoch=9]
ในระหว่างการฝึกอบรมข้อมูลที่เป็นประโยชน์เกี่ยวกับความคืบหน้าจะปรากฏขึ้น หากต้องการรับภาพรวมเต็มรูปแบบของตัวเลือกที่มีอยู่โปรดดูที่ซอร์สโค้ดของ DeepAREstimator (หรือตัวประมาณอื่น ๆ ) และ Trainer
ตอนนี้เราพร้อมที่จะคาดการณ์: เราจะคาดการณ์ชั่วโมงหลังจากเที่ยงคืนของวันที่ 15 เมษายน 2015
test_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-15 00:00:00" ]}],
freq = "5min"
) for test_entry , forecast in zip ( test_data , predictor . predict ( test_data )):
to_pandas ( test_entry )[ - 60 :]. plot ( linewidth = 2 )
forecast . plot ( color = 'g' , prediction_intervals = [ 50.0 , 90.0 ])
plt . grid ( which = 'both' )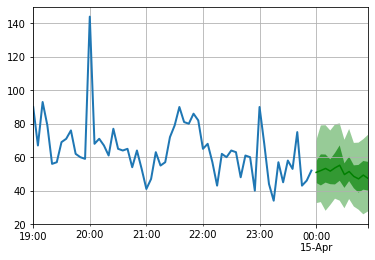
โปรดทราบว่าการคาดการณ์จะแสดงในแง่ของการกระจายความน่าจะเป็น: พื้นที่แรเงาแสดงถึงช่วงเวลาการทำนาย 50% และ 90% ตามลำดับโดยมีศูนย์กลางอยู่ที่ค่ามัธยฐาน (เส้นสีเขียวเข้ม)
pip install -e .
pytest test
เพื่ออ้างถึงที่เก็บนี้:
@software{pytorchgithub,
author = {Kashif Rasul},
title = {{P}yTorch{TS}},
url = {https://github.com/zalandoresearch/pytorch-ts},
version = {0.6.x},
year = {2021},
}เราได้ใช้โมเดลต่อไปนี้โดยใช้เฟรมเวิร์กนี้:
@INPROCEEDINGS{rasul2020tempflow,
author = {Kashif Rasul and Abdul-Saboor Sheikh and Ingmar Schuster and Urs Bergmann and Roland Vollgraf},
title = {{M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting via {C}onditioned {N}ormalizing {F}lows},
year = {2021},
url = {https://openreview.net/forum?id=WiGQBFuVRv},
booktitle = {International Conference on Learning Representations 2021},
}@InProceedings{pmlr-v139-rasul21a,
title = {{A}utoregressive {D}enoising {D}iffusion {M}odels for {M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting},
author = {Rasul, Kashif and Seward, Calvin and Schuster, Ingmar and Vollgraf, Roland},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {8857--8868},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/rasul21a/rasul21a.pdf},
url = {http://proceedings.mlr.press/v139/rasul21a.html},
}@misc{gouttes2021probabilistic,
title={{P}robabilistic {T}ime {S}eries {F}orecasting with {I}mplicit {Q}uantile {N}etworks},
author={Adèle Gouttes and Kashif Rasul and Mateusz Koren and Johannes Stephan and Tofigh Naghibi},
year={2021},
eprint={2107.03743},
archivePrefix={arXiv},
primaryClass={cs.LG}
}

