pytorch ts
Version 0.6.0
Pytorchts-это структура прогнозирования вероятностных временных рядов Pytorch, которая обеспечивает современные модели временных рядов Art Pytorch, используя глюонты в качестве наборов данных по всему концу, а также для загрузки, преобразования и обратного тестирования.
$ pip3 install pytorchts
Здесь мы выделяем изменения API через Gluonts Readme.
import matplotlib . pyplot as plt
import pandas as pd
import torch
from gluonts . dataset . common import ListDataset
from gluonts . dataset . util import to_pandas
from pts . model . deepar import DeepAREstimator
from pts import TrainerЭтот простой пример иллюстрирует, как обучить модель на некоторых данных, а затем использовать ее для прогнозирования. В качестве первого шага нам нужно собрать некоторые данные: в этом примере мы будем использовать объем твитов, упомянутых символом тикера Amzn.
url = "https://raw.githubusercontent.com/numenta/NAB/master/data/realTweets/Twitter_volume_AMZN.csv"
df = pd . read_csv ( url , header = 0 , index_col = 0 , parse_dates = True )Первые 100 точек данных выглядят как следующие:
df [: 100 ]. plot ( linewidth = 2 )
plt . grid ( which = 'both' )
plt . show ()
Теперь мы можем подготовить учебный набор данных для нашей модели для обучения. Наборы данных представляют собой по существу итерационные коллекции словарей: каждый словарь представляет собой временные ряды с возможными связанными функциями. Для этого примера у нас есть только одна запись, указанная в поле "start" , которое является временной меткой первой точки данных, и поле "target" , содержащее данные временных рядов. Для обучения мы будем использовать данные до полуночи 5 апреля 2015 года.
training_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-05 00:00:00" ]}],
freq = "5min"
) Модель прогнозирования является объектом предиктора . Одним из способов получения предикторов является обучение оценки корреспондента. Оценка оценки требует определения частоты временных рядов, которые он будет обрабатывать, а также количество временных шагов для прогнозирования. В нашем примере мы используем 5 -минутные данные, так что req="5min" , и мы будем обучать модель для прогнозирования следующего часа, так что prediction_length=12 . Ввод в модель будет вектор размера input_size=43 в каждый момент времени. Мы также указываем некоторые минимальные варианты обучения, в частности, обучение на device для epoch=10 .
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
estimator = DeepAREstimator ( freq = "5min" ,
prediction_length = 12 ,
input_size = 19 ,
trainer = Trainer ( epochs = 10 ,
device = device ))
predictor = estimator . train ( training_data = training_data , num_workers = 4 ) 45it [00:01, 37.60it/s, avg_epoch_loss=4.64, epoch=0]
48it [00:01, 39.56it/s, avg_epoch_loss=4.2, epoch=1]
45it [00:01, 38.11it/s, avg_epoch_loss=4.1, epoch=2]
43it [00:01, 36.29it/s, avg_epoch_loss=4.05, epoch=3]
44it [00:01, 35.98it/s, avg_epoch_loss=4.03, epoch=4]
48it [00:01, 39.48it/s, avg_epoch_loss=4.01, epoch=5]
48it [00:01, 38.65it/s, avg_epoch_loss=4, epoch=6]
46it [00:01, 37.12it/s, avg_epoch_loss=3.99, epoch=7]
48it [00:01, 38.86it/s, avg_epoch_loss=3.98, epoch=8]
48it [00:01, 39.49it/s, avg_epoch_loss=3.97, epoch=9]
Во время обучения будет отображаться полезная информация о прогрессе. Чтобы получить полный обзор доступных вариантов, пожалуйста, обратитесь к исходному коду DeepAREstimator (или других оценок) и Trainer .
Теперь мы готовы сделать прогнозы: мы прогнозируем час после полуночи 15 апреля 2015 года.
test_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-15 00:00:00" ]}],
freq = "5min"
) for test_entry , forecast in zip ( test_data , predictor . predict ( test_data )):
to_pandas ( test_entry )[ - 60 :]. plot ( linewidth = 2 )
forecast . plot ( color = 'g' , prediction_intervals = [ 50.0 , 90.0 ])
plt . grid ( which = 'both' )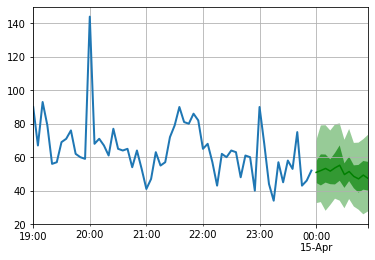
Обратите внимание, что прогноз отображается с точки зрения распределения вероятностей: затененные области представляют собой интервалы прогнозирования 50% и 90%, соответственно, сосредоточены вокруг медианы (темно -зеленая линия).
pip install -e .
pytest test
При употреблении этого хранилища:
@software{pytorchgithub,
author = {Kashif Rasul},
title = {{P}yTorch{TS}},
url = {https://github.com/zalandoresearch/pytorch-ts},
version = {0.6.x},
year = {2021},
}Мы реализовали следующую модель, используя эту структуру:
@INPROCEEDINGS{rasul2020tempflow,
author = {Kashif Rasul and Abdul-Saboor Sheikh and Ingmar Schuster and Urs Bergmann and Roland Vollgraf},
title = {{M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting via {C}onditioned {N}ormalizing {F}lows},
year = {2021},
url = {https://openreview.net/forum?id=WiGQBFuVRv},
booktitle = {International Conference on Learning Representations 2021},
}@InProceedings{pmlr-v139-rasul21a,
title = {{A}utoregressive {D}enoising {D}iffusion {M}odels for {M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting},
author = {Rasul, Kashif and Seward, Calvin and Schuster, Ingmar and Vollgraf, Roland},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {8857--8868},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/rasul21a/rasul21a.pdf},
url = {http://proceedings.mlr.press/v139/rasul21a.html},
}@misc{gouttes2021probabilistic,
title={{P}robabilistic {T}ime {S}eries {F}orecasting with {I}mplicit {Q}uantile {N}etworks},
author={Adèle Gouttes and Kashif Rasul and Mateusz Koren and Johannes Stephan and Tofigh Naghibi},
year={2021},
eprint={2107.03743},
archivePrefix={arXiv},
primaryClass={cs.LG}
}

