pytorch ts
Version 0.6.0
Pytorchts es un marco de pronóstico de series de tiempo probabilísticas de Pytorch que proporciona modelos de series de tiempo de Pytorch de última generación al utilizar Gluonts como su API de fondo y para cargar, transformar y probar conjuntos de datos de series temporales.
$ pip3 install pytorchts
Aquí destacamos los cambios de API a través del ReadMe Gluonts.
import matplotlib . pyplot as plt
import pandas as pd
import torch
from gluonts . dataset . common import ListDataset
from gluonts . dataset . util import to_pandas
from pts . model . deepar import DeepAREstimator
from pts import TrainerEste simple ejemplo ilustra cómo entrenar un modelo en algunos datos y luego usarlo para hacer predicciones. Como primer paso, necesitamos recopilar algunos datos: en este ejemplo, usaremos el volumen de tweets que mencionan el símbolo de Ticker AMZN.
url = "https://raw.githubusercontent.com/numenta/NAB/master/data/realTweets/Twitter_volume_AMZN.csv"
df = pd . read_csv ( url , header = 0 , index_col = 0 , parse_dates = True )Los primeros 100 puntos de datos parecen seguir:
df [: 100 ]. plot ( linewidth = 2 )
plt . grid ( which = 'both' )
plt . show ()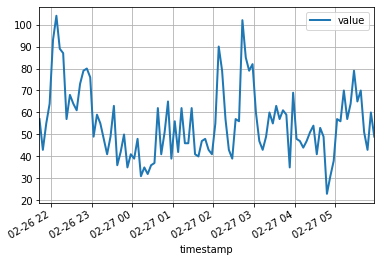
Ahora podemos preparar un conjunto de datos de capacitación para que nuestro modelo se entrene. Los conjuntos de datos son esencialmente colecciones de diccionarios: cada diccionario representa una serie temporal con características posiblemente asociadas. Para este ejemplo, solo tenemos una entrada, especificada por el campo "start" , que es la marca de tiempo del primer punto de datos, y el campo "target" que contiene datos de series temporales. Para la capacitación, utilizaremos datos hasta la medianoche del 5 de abril de 2015.
training_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-05 00:00:00" ]}],
freq = "5min"
) Un modelo de pronóstico es un objeto predictor . Una forma de obtener predictores es mediante el entrenamiento de un estimador corresponsal. La instancia de un estimador requiere especificar la frecuencia de la serie temporal que manejará, así como la cantidad de pasos de tiempo para predecir. En nuestro ejemplo, estamos usando datos de 5 minutos, por lo que req="5min" , y entrenaremos un modelo para predecir la siguiente hora, por lo que prediction_length=12 . La entrada al modelo será un vector de tamaño input_size=43 en cada punto de tiempo. También especificamos algunas opciones de entrenamiento mínimas en particular entrenamiento en un device para epoch=10 .
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
estimator = DeepAREstimator ( freq = "5min" ,
prediction_length = 12 ,
input_size = 19 ,
trainer = Trainer ( epochs = 10 ,
device = device ))
predictor = estimator . train ( training_data = training_data , num_workers = 4 ) 45it [00:01, 37.60it/s, avg_epoch_loss=4.64, epoch=0]
48it [00:01, 39.56it/s, avg_epoch_loss=4.2, epoch=1]
45it [00:01, 38.11it/s, avg_epoch_loss=4.1, epoch=2]
43it [00:01, 36.29it/s, avg_epoch_loss=4.05, epoch=3]
44it [00:01, 35.98it/s, avg_epoch_loss=4.03, epoch=4]
48it [00:01, 39.48it/s, avg_epoch_loss=4.01, epoch=5]
48it [00:01, 38.65it/s, avg_epoch_loss=4, epoch=6]
46it [00:01, 37.12it/s, avg_epoch_loss=3.99, epoch=7]
48it [00:01, 38.86it/s, avg_epoch_loss=3.98, epoch=8]
48it [00:01, 39.49it/s, avg_epoch_loss=3.97, epoch=9]
Durante la capacitación, se mostrará información útil sobre el progreso. Para obtener una descripción completa de las opciones disponibles, consulte el código fuente de DeepAREstimator (u otros estimadores) y Trainer .
Ahora estamos listos para hacer predicciones: pronosticaremos la hora posterior a la medianoche del 15 de abril de 2015.
test_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-15 00:00:00" ]}],
freq = "5min"
) for test_entry , forecast in zip ( test_data , predictor . predict ( test_data )):
to_pandas ( test_entry )[ - 60 :]. plot ( linewidth = 2 )
forecast . plot ( color = 'g' , prediction_intervals = [ 50.0 , 90.0 ])
plt . grid ( which = 'both' )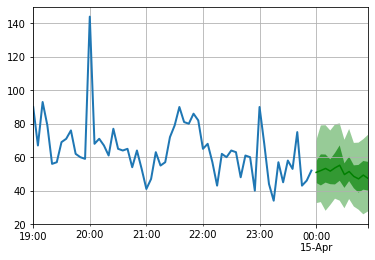
Tenga en cuenta que el pronóstico se muestra en términos de una distribución de probabilidad: las áreas sombreadas representan los intervalos de predicción del 50% y 90%, respectivamente, centrados en la mediana (línea verde oscuro).
pip install -e .
pytest test
Para citar este repositorio:
@software{pytorchgithub,
author = {Kashif Rasul},
title = {{P}yTorch{TS}},
url = {https://github.com/zalandoresearch/pytorch-ts},
version = {0.6.x},
year = {2021},
}Hemos implementado el siguiente modelo utilizando este marco:
@INPROCEEDINGS{rasul2020tempflow,
author = {Kashif Rasul and Abdul-Saboor Sheikh and Ingmar Schuster and Urs Bergmann and Roland Vollgraf},
title = {{M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting via {C}onditioned {N}ormalizing {F}lows},
year = {2021},
url = {https://openreview.net/forum?id=WiGQBFuVRv},
booktitle = {International Conference on Learning Representations 2021},
}@InProceedings{pmlr-v139-rasul21a,
title = {{A}utoregressive {D}enoising {D}iffusion {M}odels for {M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting},
author = {Rasul, Kashif and Seward, Calvin and Schuster, Ingmar and Vollgraf, Roland},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {8857--8868},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/rasul21a/rasul21a.pdf},
url = {http://proceedings.mlr.press/v139/rasul21a.html},
}@misc{gouttes2021probabilistic,
title={{P}robabilistic {T}ime {S}eries {F}orecasting with {I}mplicit {Q}uantile {N}etworks},
author={Adèle Gouttes and Kashif Rasul and Mateusz Koren and Johannes Stephan and Tofigh Naghibi},
year={2021},
eprint={2107.03743},
archivePrefix={arXiv},
primaryClass={cs.LG}
}

