pytorch ts
Version 0.6.0
PytorChts ist ein Pytorch-Prognose-Framework für Zeitreihen, das auf dem neuesten Stand der Technik Pytorch Time Series-Modelle bietet, indem GLUONTS als Back-End-API und zum Laden, Transformieren und Backtest-Testing-Zeitreihen Datensätze verwendet wird.
$ pip3 install pytorchts
Hier heben wir die API über die Gluonts Readme hervor.
import matplotlib . pyplot as plt
import pandas as pd
import torch
from gluonts . dataset . common import ListDataset
from gluonts . dataset . util import to_pandas
from pts . model . deepar import DeepAREstimator
from pts import TrainerDieses einfache Beispiel zeigt, wie ein Modell für einige Daten trainiert und es dann verwendet wird, um Vorhersagen zu treffen. Als erster Schritt müssen wir einige Daten sammeln: In diesem Beispiel werden wir das Volumen der Tweets verwenden, wobei das AMZN -Ticker -Symbol erwähnt wird.
url = "https://raw.githubusercontent.com/numenta/NAB/master/data/realTweets/Twitter_volume_AMZN.csv"
df = pd . read_csv ( url , header = 0 , index_col = 0 , parse_dates = True )Die ersten 100 Datenpunkte sehen folgend aus:
df [: 100 ]. plot ( linewidth = 2 )
plt . grid ( which = 'both' )
plt . show ()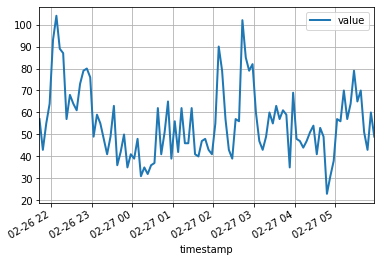
Wir können jetzt einen Trainingsdatensatz für unser Modell vorbereiten, um darauf zu trainieren. Datensätze sind im Wesentlichen iterbare Sammlungen von Wörterbüchern: Jedes Wörterbuch stellt eine Zeitreihe mit möglicherweise zugehörigen Funktionen dar. In diesem Beispiel haben wir nur einen Eintrag, der durch das Feld "start" angegeben ist und der Zeitstempel des ersten Datenpunkts ist, und das Feld "target" das Zeitreihendaten enthält. Für das Training werden wir Daten bis Mitternacht am 5. April 2015 verwenden.
training_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-05 00:00:00" ]}],
freq = "5min"
) Ein Prognosemodell ist ein Prädiktorobjekt . Eine Möglichkeit, Prädiktoren zu erhalten, besteht darin, einen Korrespondenzschätzer auszubilden. Wenn Sie einen Schätzer instanziieren, müssen Sie die Häufigkeit der Zeitreihen, die er verarbeitet, sowie die Anzahl der Zeitschritte zur Vorhersage angeben muss. In unserem Beispiel verwenden wir 5 Minuten Daten, also req="5min" , und wir werden ein Modell für die Vorhersage der nächsten Stunde trainieren, also prediction_length=12 . Die Eingabe zum Modell ist zu jedem Zeitpunkt ein Vektor der Größe input_size=43 . Wir geben auch einige minimale Trainingsoptionen an, das insbesondere auf einem device für epoch=10 Schulungen aufgenommen hat.
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
estimator = DeepAREstimator ( freq = "5min" ,
prediction_length = 12 ,
input_size = 19 ,
trainer = Trainer ( epochs = 10 ,
device = device ))
predictor = estimator . train ( training_data = training_data , num_workers = 4 ) 45it [00:01, 37.60it/s, avg_epoch_loss=4.64, epoch=0]
48it [00:01, 39.56it/s, avg_epoch_loss=4.2, epoch=1]
45it [00:01, 38.11it/s, avg_epoch_loss=4.1, epoch=2]
43it [00:01, 36.29it/s, avg_epoch_loss=4.05, epoch=3]
44it [00:01, 35.98it/s, avg_epoch_loss=4.03, epoch=4]
48it [00:01, 39.48it/s, avg_epoch_loss=4.01, epoch=5]
48it [00:01, 38.65it/s, avg_epoch_loss=4, epoch=6]
46it [00:01, 37.12it/s, avg_epoch_loss=3.99, epoch=7]
48it [00:01, 38.86it/s, avg_epoch_loss=3.98, epoch=8]
48it [00:01, 39.49it/s, avg_epoch_loss=3.97, epoch=9]
Während des Trainings werden nützliche Informationen über den Fortschritt angezeigt. Um einen vollständigen Überblick über die verfügbaren Optionen zu erhalten, finden Sie im Quellcode von DeepAREstimator (oder anderen Schätzern) und Trainer .
Wir sind jetzt bereit, Vorhersagen zu treffen: Wir werden die Stunde nach der Mitternacht am 15. April 2015 prognostizieren.
test_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-15 00:00:00" ]}],
freq = "5min"
) for test_entry , forecast in zip ( test_data , predictor . predict ( test_data )):
to_pandas ( test_entry )[ - 60 :]. plot ( linewidth = 2 )
forecast . plot ( color = 'g' , prediction_intervals = [ 50.0 , 90.0 ])
plt . grid ( which = 'both' )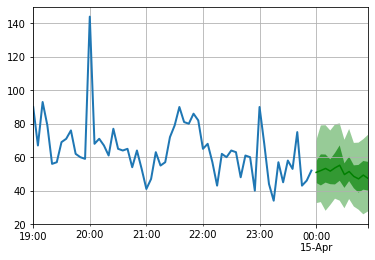
Beachten Sie, dass die Prognose in Bezug auf eine Wahrscheinlichkeitsverteilung angezeigt wird: Die schattierten Bereiche repräsentieren die Vorhersageintervalle von 50% bzw. 90%, die sich um den Median zentrieren (dunkelgrüne Linie).
pip install -e .
pytest test
So zitieren Sie dieses Repository:
@software{pytorchgithub,
author = {Kashif Rasul},
title = {{P}yTorch{TS}},
url = {https://github.com/zalandoresearch/pytorch-ts},
version = {0.6.x},
year = {2021},
}Wir haben das folgende Modell mit diesem Framework implementiert:
@INPROCEEDINGS{rasul2020tempflow,
author = {Kashif Rasul and Abdul-Saboor Sheikh and Ingmar Schuster and Urs Bergmann and Roland Vollgraf},
title = {{M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting via {C}onditioned {N}ormalizing {F}lows},
year = {2021},
url = {https://openreview.net/forum?id=WiGQBFuVRv},
booktitle = {International Conference on Learning Representations 2021},
}@InProceedings{pmlr-v139-rasul21a,
title = {{A}utoregressive {D}enoising {D}iffusion {M}odels for {M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting},
author = {Rasul, Kashif and Seward, Calvin and Schuster, Ingmar and Vollgraf, Roland},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {8857--8868},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/rasul21a/rasul21a.pdf},
url = {http://proceedings.mlr.press/v139/rasul21a.html},
}@misc{gouttes2021probabilistic,
title={{P}robabilistic {T}ime {S}eries {F}orecasting with {I}mplicit {Q}uantile {N}etworks},
author={Adèle Gouttes and Kashif Rasul and Mateusz Koren and Johannes Stephan and Tofigh Naghibi},
year={2021},
eprint={2107.03743},
archivePrefix={arXiv},
primaryClass={cs.LG}
}

