pytorch ts
Version 0.6.0
O Pytorchts é uma estrutura de previsão de séries temporais probabilísticas de Pytorch, que fornece modelos de séries temporais de última geração, utilizando gluontes como sua API de back-end e para carregar, transformar e testar os conjuntos de dados da série de tempo.
$ pip3 install pytorchts
Aqui, destacamos as alterações da API através do Readme Gluonts.
import matplotlib . pyplot as plt
import pandas as pd
import torch
from gluonts . dataset . common import ListDataset
from gluonts . dataset . util import to_pandas
from pts . model . deepar import DeepAREstimator
from pts import TrainerEste exemplo simples ilustra como treinar um modelo em alguns dados e depois usá -los para fazer previsões. Como primeira etapa, precisamos coletar alguns dados: neste exemplo, usaremos o volume de tweets mencionando o símbolo AMZN Ticker.
url = "https://raw.githubusercontent.com/numenta/NAB/master/data/realTweets/Twitter_volume_AMZN.csv"
df = pd . read_csv ( url , header = 0 , index_col = 0 , parse_dates = True )Os 100 primeiros pontos de dados parecem seguintes:
df [: 100 ]. plot ( linewidth = 2 )
plt . grid ( which = 'both' )
plt . show ()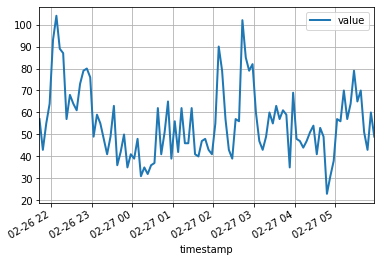
Agora podemos preparar um conjunto de dados de treinamento para o nosso modelo treinar. Os conjuntos de dados são essencialmente coleções iteráveis de dicionários: cada dicionário representa uma série temporal com recursos possivelmente associados. Para este exemplo, temos apenas uma entrada, especificada pelo campo "start" , que é o registro de data e hora do primeiro ponto de dados e o campo "target" contendo dados de séries temporais. Para treinamento, usaremos dados até meia -noite em 5 de abril de 2015.
training_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-05 00:00:00" ]}],
freq = "5min"
) Um modelo de previsão é um objeto preditor . Uma maneira de obter preditores é treinar um estimador correspondente. Instantando um estimador requer especificar a frequência das séries temporais que ele manipulará, bem como o número de etapas de tempo a serem previstas. Em nosso exemplo, estamos usando dados de 5 minutos, então req="5min" , e treinaremos um modelo para prever a próxima hora, então prediction_length=12 . A entrada para o modelo será um vetor de tamanho input_size=43 em cada momento. Também especificamos algumas opções mínimas de treinamento, em particular treinamento em um device para epoch=10 .
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
estimator = DeepAREstimator ( freq = "5min" ,
prediction_length = 12 ,
input_size = 19 ,
trainer = Trainer ( epochs = 10 ,
device = device ))
predictor = estimator . train ( training_data = training_data , num_workers = 4 ) 45it [00:01, 37.60it/s, avg_epoch_loss=4.64, epoch=0]
48it [00:01, 39.56it/s, avg_epoch_loss=4.2, epoch=1]
45it [00:01, 38.11it/s, avg_epoch_loss=4.1, epoch=2]
43it [00:01, 36.29it/s, avg_epoch_loss=4.05, epoch=3]
44it [00:01, 35.98it/s, avg_epoch_loss=4.03, epoch=4]
48it [00:01, 39.48it/s, avg_epoch_loss=4.01, epoch=5]
48it [00:01, 38.65it/s, avg_epoch_loss=4, epoch=6]
46it [00:01, 37.12it/s, avg_epoch_loss=3.99, epoch=7]
48it [00:01, 38.86it/s, avg_epoch_loss=3.98, epoch=8]
48it [00:01, 39.49it/s, avg_epoch_loss=3.97, epoch=9]
Durante o treinamento, informações úteis sobre o progresso serão exibidas. Para obter uma visão geral completa das opções disponíveis, consulte o código -fonte do DeepAREstimator (ou outros estimadores) e Trainer .
Agora estamos prontos para fazer previsões: preveremos a hora após a meia -noite de 15 de abril de 2015.
test_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-15 00:00:00" ]}],
freq = "5min"
) for test_entry , forecast in zip ( test_data , predictor . predict ( test_data )):
to_pandas ( test_entry )[ - 60 :]. plot ( linewidth = 2 )
forecast . plot ( color = 'g' , prediction_intervals = [ 50.0 , 90.0 ])
plt . grid ( which = 'both' )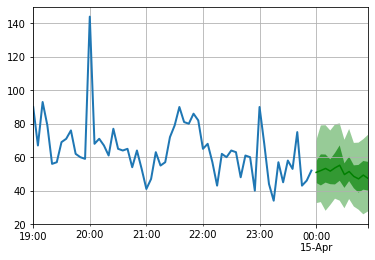
Observe que a previsão é exibida em termos de distribuição de probabilidade: as áreas sombreadas representam os intervalos de previsão de 50% e 90%, respectivamente, centrados na mediana (linha verde escura).
pip install -e .
pytest test
Para citar este repositório:
@software{pytorchgithub,
author = {Kashif Rasul},
title = {{P}yTorch{TS}},
url = {https://github.com/zalandoresearch/pytorch-ts},
version = {0.6.x},
year = {2021},
}Implementamos o seguinte modelo usando esta estrutura:
@INPROCEEDINGS{rasul2020tempflow,
author = {Kashif Rasul and Abdul-Saboor Sheikh and Ingmar Schuster and Urs Bergmann and Roland Vollgraf},
title = {{M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting via {C}onditioned {N}ormalizing {F}lows},
year = {2021},
url = {https://openreview.net/forum?id=WiGQBFuVRv},
booktitle = {International Conference on Learning Representations 2021},
}@InProceedings{pmlr-v139-rasul21a,
title = {{A}utoregressive {D}enoising {D}iffusion {M}odels for {M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting},
author = {Rasul, Kashif and Seward, Calvin and Schuster, Ingmar and Vollgraf, Roland},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {8857--8868},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/rasul21a/rasul21a.pdf},
url = {http://proceedings.mlr.press/v139/rasul21a.html},
}@misc{gouttes2021probabilistic,
title={{P}robabilistic {T}ime {S}eries {F}orecasting with {I}mplicit {Q}uantile {N}etworks},
author={Adèle Gouttes and Kashif Rasul and Mateusz Koren and Johannes Stephan and Tofigh Naghibi},
year={2021},
eprint={2107.03743},
archivePrefix={arXiv},
primaryClass={cs.LG}
}

