pytorch ts
Version 0.6.0
Pytorchts هو إطار للتنبؤ بسلسلة Pytorch probabilistic ، والذي يوفر نماذج سلسلة زمنية Pytorch الفنية من خلال استخدام Gluonts كأاجهات واجهة برمجة التطبيقات الخلفية ولتحميل مجموعات بيانات السلاسل الزمنية وتحويلها واختبارها الخلفية.
$ pip3 install pytorchts
هنا نسلط الضوء على تغييرات API عبر Gluonts readme.
import matplotlib . pyplot as plt
import pandas as pd
import torch
from gluonts . dataset . common import ListDataset
from gluonts . dataset . util import to_pandas
from pts . model . deepar import DeepAREstimator
from pts import Trainerيوضح هذا المثال البسيط كيفية تدريب نموذج على بعض البيانات ، ثم استخدمه لعمل التنبؤات. كخطوة أولى ، نحتاج إلى جمع بعض البيانات: في هذا المثال ، سنستخدم حجم التغريدات التي تذكر رمز AMZN Ticker.
url = "https://raw.githubusercontent.com/numenta/NAB/master/data/realTweets/Twitter_volume_AMZN.csv"
df = pd . read_csv ( url , header = 0 , index_col = 0 , parse_dates = True )تبدو أول 100 نقطة بيانات يلي:
df [: 100 ]. plot ( linewidth = 2 )
plt . grid ( which = 'both' )
plt . show ()
يمكننا الآن إعداد مجموعة بيانات تدريب لنموذجنا للتدريب عليها. مجموعات البيانات عبارة عن مجموعات من القواميس غير قابلة للإعجاب: تمثل كل قاموس سلسلة زمنية ذات ميزات ربما مرتبطة. على سبيل المثال ، ليس لدينا سوى إدخال واحد ، يحدده حقل "start" وهو الطابع الزمني لنقطة البيانات الأولى ، وحقل "target" الذي يحتوي على بيانات السلاسل الزمنية. للتدريب ، سوف نستخدم البيانات حتى منتصف الليل في 5 أبريل 2015.
training_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-05 00:00:00" ]}],
freq = "5min"
) نموذج التنبؤ هو كائن تنبؤ . طريقة واحدة للحصول على المتنبئين هي عن طريق تدريب مقدر المراسل. يتطلب إنشاء المقدر تحديد تواتر السلسلة الزمنية التي سيتعامل معها ، وكذلك عدد الخطوات الزمنية للتنبؤ بها. في مثالنا ، نستخدم بيانات 5 دقائق ، لذلك req="5min" ، وسنقوم بتدريب نموذج للتنبؤ بالساعة التالية ، لذلك prediction_length=12 . سيكون المدخلات إلى النموذج متجهًا من الحجم input_size=43 في كل نقطة زمنية. نحدد أيضًا بعض خيارات التدريب الدنيا في التدريب على وجه الخصوص على device لـ epoch=10 .
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
estimator = DeepAREstimator ( freq = "5min" ,
prediction_length = 12 ,
input_size = 19 ,
trainer = Trainer ( epochs = 10 ,
device = device ))
predictor = estimator . train ( training_data = training_data , num_workers = 4 ) 45it [00:01, 37.60it/s, avg_epoch_loss=4.64, epoch=0]
48it [00:01, 39.56it/s, avg_epoch_loss=4.2, epoch=1]
45it [00:01, 38.11it/s, avg_epoch_loss=4.1, epoch=2]
43it [00:01, 36.29it/s, avg_epoch_loss=4.05, epoch=3]
44it [00:01, 35.98it/s, avg_epoch_loss=4.03, epoch=4]
48it [00:01, 39.48it/s, avg_epoch_loss=4.01, epoch=5]
48it [00:01, 38.65it/s, avg_epoch_loss=4, epoch=6]
46it [00:01, 37.12it/s, avg_epoch_loss=3.99, epoch=7]
48it [00:01, 38.86it/s, avg_epoch_loss=3.98, epoch=8]
48it [00:01, 39.49it/s, avg_epoch_loss=3.97, epoch=9]
أثناء التدريب ، سيتم عرض معلومات مفيدة حول التقدم. للحصول على نظرة عامة كاملة على الخيارات المتاحة ، يرجى الرجوع إلى رمز المصدر لـ DeepAREstimator (أو المقدرين الآخرين) Trainer .
نحن الآن على استعداد لتقديم تنبؤات: سوف نتوقع الساعة التالية لفيلم منتصف الليل في 15 أبريل 2015.
test_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-15 00:00:00" ]}],
freq = "5min"
) for test_entry , forecast in zip ( test_data , predictor . predict ( test_data )):
to_pandas ( test_entry )[ - 60 :]. plot ( linewidth = 2 )
forecast . plot ( color = 'g' , prediction_intervals = [ 50.0 , 90.0 ])
plt . grid ( which = 'both' )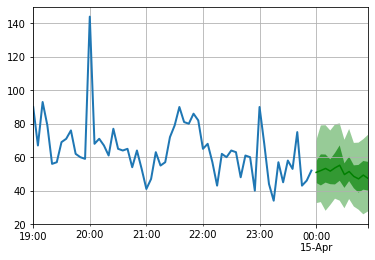
لاحظ أن التوقعات يتم عرضها من حيث توزيع الاحتمالات: تمثل المناطق المظللة فترات التنبؤ بنسبة 50 ٪ و 90 ٪ ، على التوالي ، تتمحور حول الوسيط (الخط الأخضر الداكن).
pip install -e .
pytest test
للاستشهاد بهذا المستودع:
@software{pytorchgithub,
author = {Kashif Rasul},
title = {{P}yTorch{TS}},
url = {https://github.com/zalandoresearch/pytorch-ts},
version = {0.6.x},
year = {2021},
}لقد قمنا بتنفيذ النموذج التالي باستخدام هذا الإطار:
@INPROCEEDINGS{rasul2020tempflow,
author = {Kashif Rasul and Abdul-Saboor Sheikh and Ingmar Schuster and Urs Bergmann and Roland Vollgraf},
title = {{M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting via {C}onditioned {N}ormalizing {F}lows},
year = {2021},
url = {https://openreview.net/forum?id=WiGQBFuVRv},
booktitle = {International Conference on Learning Representations 2021},
}@InProceedings{pmlr-v139-rasul21a,
title = {{A}utoregressive {D}enoising {D}iffusion {M}odels for {M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting},
author = {Rasul, Kashif and Seward, Calvin and Schuster, Ingmar and Vollgraf, Roland},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {8857--8868},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/rasul21a/rasul21a.pdf},
url = {http://proceedings.mlr.press/v139/rasul21a.html},
}@misc{gouttes2021probabilistic,
title={{P}robabilistic {T}ime {S}eries {F}orecasting with {I}mplicit {Q}uantile {N}etworks},
author={Adèle Gouttes and Kashif Rasul and Mateusz Koren and Johannes Stephan and Tofigh Naghibi},
year={2021},
eprint={2107.03743},
archivePrefix={arXiv},
primaryClass={cs.LG}
}

