pytorch ts
Version 0.6.0
Pytorchts est un cadre de prévision chronologique probabiliste de Pytorch qui fournit des modèles de séries chronologiques de pointe de la pointe de l'art en utilisant les gluont comme API back-end et pour le chargement, la transformation et les ensembles de séries chronologiques en back-test.
$ pip3 install pytorchts
Ici, nous mettons en évidence les modifications de l'API via les Gluont Readme.
import matplotlib . pyplot as plt
import pandas as pd
import torch
from gluonts . dataset . common import ListDataset
from gluonts . dataset . util import to_pandas
from pts . model . deepar import DeepAREstimator
from pts import TrainerCet exemple simple illustre comment former un modèle sur certaines données, puis l'utiliser pour faire des prédictions. Dans une première étape, nous devons collecter certaines données: dans cet exemple, nous utiliserons le volume de tweets mentionnant le symbole du ticker AMZN.
url = "https://raw.githubusercontent.com/numenta/NAB/master/data/realTweets/Twitter_volume_AMZN.csv"
df = pd . read_csv ( url , header = 0 , index_col = 0 , parse_dates = True )Les 100 premiers points de données ressemblent à suit:
df [: 100 ]. plot ( linewidth = 2 )
plt . grid ( which = 'both' )
plt . show ()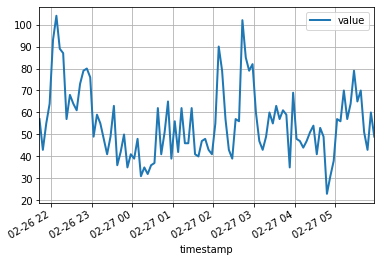
Nous pouvons désormais préparer un ensemble de données de formation pour que notre modèle puisse s'entraîner. Les ensembles de données sont essentiellement des collections de dictionnaires iTables: chaque dictionnaire représente une série temporelle avec des fonctionnalités éventuellement associées. Pour cet exemple, nous n'avons qu'une seule entrée, spécifiée par le champ "start" qui est l'horodatage du premier point de données, et le champ "target" contenant des données de séries chronologiques. Pour la formation, nous utiliserons des données jusqu'à minuit le 5 avril 2015.
training_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-05 00:00:00" ]}],
freq = "5min"
) Un modèle de prévision est un objet prédictif . Une façon d'obtenir des prédicteurs est de former un estimateur correspondant. Instanciation d'un estimateur nécessite de spécifier la fréquence des séries chronologiques qu'elle gérera, ainsi que le nombre de pas de temps à prévoir. Dans notre exemple, nous utilisons 5 minutes de données, donc req="5min" , et nous allons former un modèle pour prédire l'heure suivante, donc prediction_length=12 . L'entrée du modèle sera un vecteur de taille input_size=43 à chaque point dans le temps. Nous spécifions également certaines options de formation minimales dans une formation particulière sur un device pour epoch=10 .
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
estimator = DeepAREstimator ( freq = "5min" ,
prediction_length = 12 ,
input_size = 19 ,
trainer = Trainer ( epochs = 10 ,
device = device ))
predictor = estimator . train ( training_data = training_data , num_workers = 4 ) 45it [00:01, 37.60it/s, avg_epoch_loss=4.64, epoch=0]
48it [00:01, 39.56it/s, avg_epoch_loss=4.2, epoch=1]
45it [00:01, 38.11it/s, avg_epoch_loss=4.1, epoch=2]
43it [00:01, 36.29it/s, avg_epoch_loss=4.05, epoch=3]
44it [00:01, 35.98it/s, avg_epoch_loss=4.03, epoch=4]
48it [00:01, 39.48it/s, avg_epoch_loss=4.01, epoch=5]
48it [00:01, 38.65it/s, avg_epoch_loss=4, epoch=6]
46it [00:01, 37.12it/s, avg_epoch_loss=3.99, epoch=7]
48it [00:01, 38.86it/s, avg_epoch_loss=3.98, epoch=8]
48it [00:01, 39.49it/s, avg_epoch_loss=3.97, epoch=9]
Pendant la formation, des informations utiles sur les progrès seront affichées. Pour obtenir un aperçu complet des options disponibles, veuillez vous référer au code source de DeepAREstimator (ou d'autres estimateurs) et Trainer .
Nous sommes maintenant prêts à faire des prédictions: nous allons prévoir l'heure suivant la minuit le 15 avril 2015.
test_data = ListDataset (
[{ "start" : df . index [ 0 ], "target" : df . value [: "2015-04-15 00:00:00" ]}],
freq = "5min"
) for test_entry , forecast in zip ( test_data , predictor . predict ( test_data )):
to_pandas ( test_entry )[ - 60 :]. plot ( linewidth = 2 )
forecast . plot ( color = 'g' , prediction_intervals = [ 50.0 , 90.0 ])
plt . grid ( which = 'both' )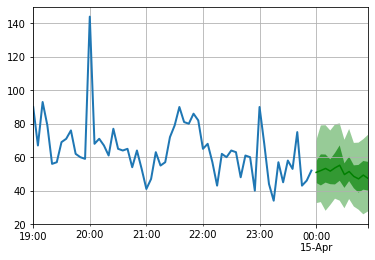
Notez que les prévisions sont affichées en termes de distribution de probabilité: les zones ombrées représentent respectivement les intervalles de prédiction de 50% et 90%, centrés autour de la médiane (ligne verte foncée).
pip install -e .
pytest test
Pour citer ce référentiel:
@software{pytorchgithub,
author = {Kashif Rasul},
title = {{P}yTorch{TS}},
url = {https://github.com/zalandoresearch/pytorch-ts},
version = {0.6.x},
year = {2021},
}Nous avons implémenté le modèle suivant en utilisant ce cadre:
@INPROCEEDINGS{rasul2020tempflow,
author = {Kashif Rasul and Abdul-Saboor Sheikh and Ingmar Schuster and Urs Bergmann and Roland Vollgraf},
title = {{M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting via {C}onditioned {N}ormalizing {F}lows},
year = {2021},
url = {https://openreview.net/forum?id=WiGQBFuVRv},
booktitle = {International Conference on Learning Representations 2021},
}@InProceedings{pmlr-v139-rasul21a,
title = {{A}utoregressive {D}enoising {D}iffusion {M}odels for {M}ultivariate {P}robabilistic {T}ime {S}eries {F}orecasting},
author = {Rasul, Kashif and Seward, Calvin and Schuster, Ingmar and Vollgraf, Roland},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {8857--8868},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/rasul21a/rasul21a.pdf},
url = {http://proceedings.mlr.press/v139/rasul21a.html},
}@misc{gouttes2021probabilistic,
title={{P}robabilistic {T}ime {S}eries {F}orecasting with {I}mplicit {Q}uantile {N}etworks},
author={Adèle Gouttes and Kashif Rasul and Mateusz Koren and Johannes Stephan and Tofigh Naghibi},
year={2021},
eprint={2107.03743},
archivePrefix={arXiv},
primaryClass={cs.LG}
}

