สร้างฐานความรู้เศษผ้าขนาดใหญ่ตั้งแต่เริ่มต้น
โครงการนี้ใช้กระบวนการใช้ฐานความรู้ภายนอกสำหรับแบบจำลองขนาดใหญ่ตั้งแต่เริ่มต้น:
- การประมวลผลชุดข้อมูลภาษาจีน
- การฝึกอบรมแบบจำลองเวกเตอร์ Word
- เอกสารเวกเตอร์
- ฐานความรู้การจัดเก็บข้อมูลเวกเตอร์ฐานข้อมูล
- การปรับใช้รุ่นใหญ่ chatglm2-6b
- แอปพลิเคชันฐานความรู้ง่ายๆ
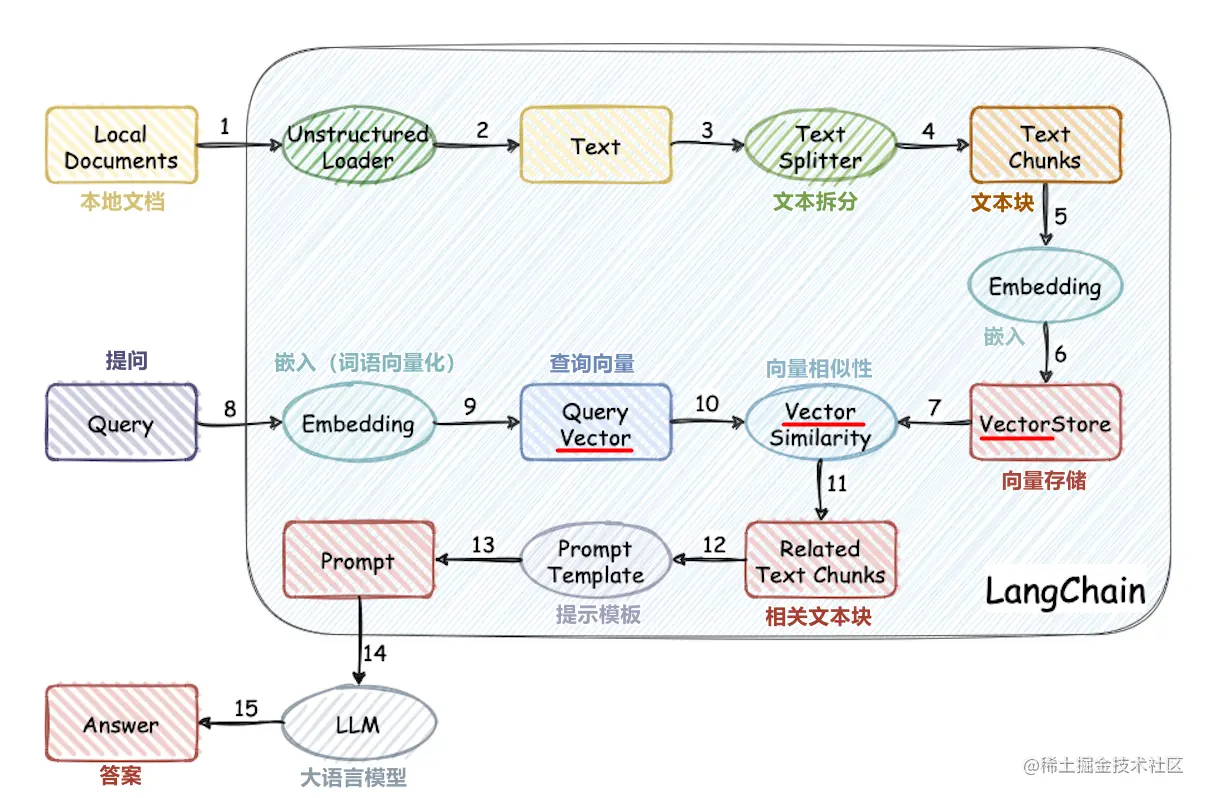
โครงสร้างโครงการ
- Corpus: โฟลเดอร์ที่จัดเก็บเอกสารฐานความรู้
- ข้อมูล: ข้อมูลที่เกี่ยวข้องกับการฝึกอบรมแบบจำลองเวกเตอร์ Word (ไฟล์โมเดลมีขนาดใหญ่โปรดดาวน์โหลดโมเดลด้วยตัวคุณเอง)
- เอกสาร: ซอร์สโค้ดและเอกสารประกอบสำหรับการฝึกอบรมแบบจำลองเวกเตอร์ Word
- llm_server: แอปพลิเคชันฐานความรู้ง่ายๆ
- vector_db: บันทึกเอกสารในคลังข้อมูลลงในฐานข้อมูล qdrant Vector
- config.json: การกำหนดค่าบางอย่างของโครงการ
- openai_api_key: คีย์ API ของ Openai
- EMBEDDING_MODEL_TYPE: โมเดลข้อความ vectorized OpenAI หรือ Word2Vec
- chat_model_type: บทสนทนา mockup openai หรือ chatglm
- chatglm_port: พอร์ตสำหรับการปรับใช้ท้องถิ่นของ chatglm
- ** เส้นทาง: บางเส้นทางเริ่มต้นจากไดเรกทอรีรากโครงการ
- Collection_name: ชื่อของการรวบรวมฐานข้อมูลเวกเตอร์
วิ่ง
สร้างฐานความรู้ถาวร
cd vector_db
pip install -r requirements.txt
python main.py
main.py จะสร้างฐานข้อมูลเวกเตอร์ชื่อคอลเลกชัน _name โดยอัตโนมัติและจัดเก็บเวกเตอร์เอกสารในโฟลเดอร์คอร์ปัสลงในฐานข้อมูล
เรียกใช้แอปพลิเคชัน
cd llm_server
pip install -r requirements.txt
python main.py
รัน chatglm2-6b ที่ปรับใช้ในพื้นที่
อ้างถึงเอกสารอย่างเป็นทางการของ chatglm2-6b
การสอน


