Bauen Sie eine große Modellbasis für Lappen -Lappen von Grund auf neu auf
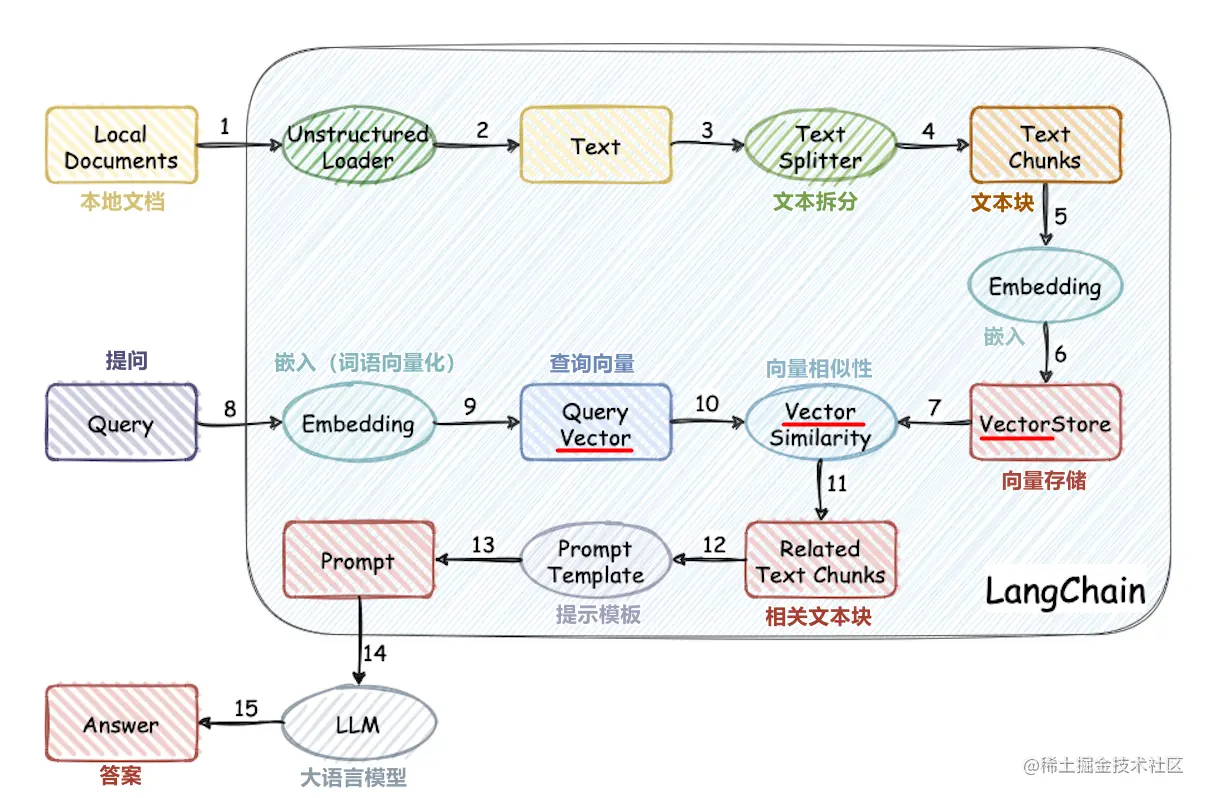
Dieses Projekt implementiert den Prozess der Verwendung der externen Wissensbasis für Großmodelle von Grund auf:
- Verarbeitung chinesischer Datensatzverarbeitung
- Wortvektormodelltraining
- Dokumentvektorisierung
- Vektor -Datenbankspeicherwissensbasis
- Lokale Chatglm2-6b große Modellbereitstellung
- Einfache Anwendung von Wissensbasis
Projektstruktur
- Corpus: Der Ordner, in dem die Wissensbasisdokumente gespeichert sind
- Daten: Daten im Zusammenhang mit Word -Vektormodelltraining (die Modelldatei ist groß, bitte laden Sie das Modell selbst herunter)
- DOC: Quellcode und Dokumentation für Word -Vektor -Modelltraining
- LLM_SERVER: Einfache Anwendung für Wissensbasis
- vector_db: Speichern Sie das Dokument in Corpus in der QDrant Vector -Datenbank
- config.json: Einige Konfigurationen des Projekts
- OpenAI_API_KEY: OpenAIs API -Schlüssel
- Einbettung_Model_Type: Text vectorized Modell OpenAI oder Word2VEC
- CHAT_MODEL_TYPE: Dialog Mockup Openai oder Chatglm
- CHATGLM_PORT: Port für die lokale Bereitstellung von Chatglm
- ** Pfad: Einige Pfade, beginnend mit dem Projekt Root Directory
- Collection_Name: Name der Vektor -Datenbanksammlung
laufen
Erzeugen eine anhaltende Wissensbasis
cd vector_db
pip install -r requirements.txt
python main.py
main.py erstellt automatisch eine Vektor -Datenbank mit dem Namen Collection_Name und speichere die Dokumentvektoren im Korpusordner in der Datenbank
Führen Sie die Anwendung aus
cd llm_server
pip install -r requirements.txt
python main.py
Führen Sie lokal bereitgestellte Chatglm2-6b aus
Siehe das offizielle Dokument von Chatglm2-6b
Tutorial


