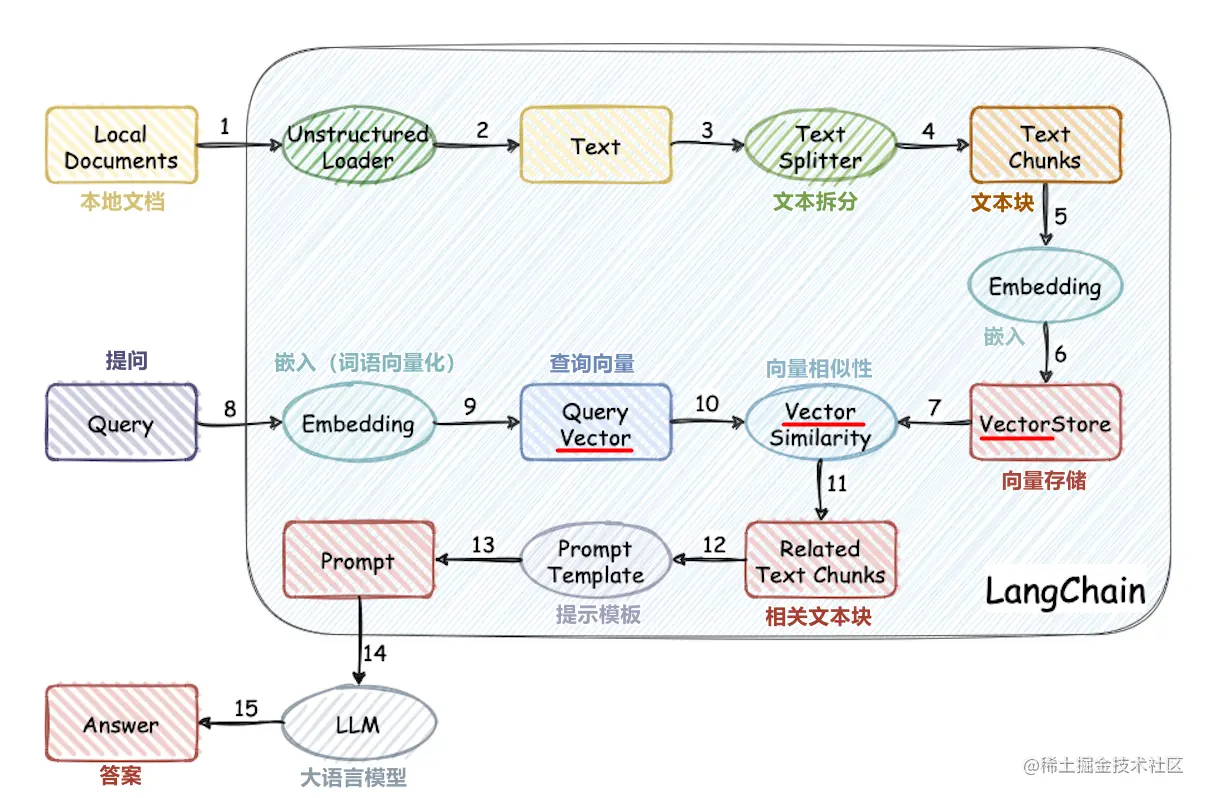
ゼロから大きなモデルのぼろきれの知識ベースを構築します
このプロジェクトは、大型モデルに外部の知識ベースをゼロから使用するプロセスを実装しています。
- 中国のデータセット処理
- 単語ベクトルモデルトレーニング
- ドキュメントベクトル化
- ベクトルデータベースストレージナレッジベース
- ローカルchatglm2-6bビッグモデルの展開
- 簡単な知識ベースアプリケーション
プロジェクト構造
- コーパス:ナレッジベースドキュメントが保存されるフォルダー
- データ:単語ベクトルモデルトレーニングに関連するデータ(モデルファイルは大きいので、モデルを自分でダウンロードしてください)
- ドキュメント:単語ベクターモデルトレーニングのソースコードとドキュメント
- LLM_SERVER:Simple Knowledge Baseアプリケーション
- vector_db:corpusのドキュメントをqdrant vectorデータベースに保存します
- config.json:プロジェクトの一部の構成
- Openai_api_key:OpenaiのAPIキー
- embedding_model_type:テキストベクトル化モデルOpenaiまたはword2vec
- chat_model_type:Dialogue Mockup openaiまたはchatglm
- chatglm_port:chatglmのローカル展開用のポート
- **パス:プロジェクトルートディレクトリから始まるパス
- Collection_name:Vectorデータベースコレクションの名前
走る
永続的な知識ベースを生成します
cd vector_db
pip install -r requirements.txt
python main.py
main.pyは、collection_nameという名前のベクトルデータベースを自動的に作成し、corpusフォルダーのドキュメントベクトルをデータベースに保存します
アプリケーションを実行します
cd llm_server
pip install -r requirements.txt
python main.py
ローカルに展開されたchatglm2-6bを実行します
chatglm2-6bの公式文書を参照してください
チュートリアル


