Создайте большую модельную базу знаний Rag с нуля
Этот проект реализует процесс использования внешней базы знаний для крупных моделей с нуля:
- Китайская обработка набора данных
- Word Vector Model Training
- Векторизация документа
- База знаний о хранении векторных баз данных
- Локальная чатгггм2-6B Big Model Развертывание модели
- Простое применение базы знаний
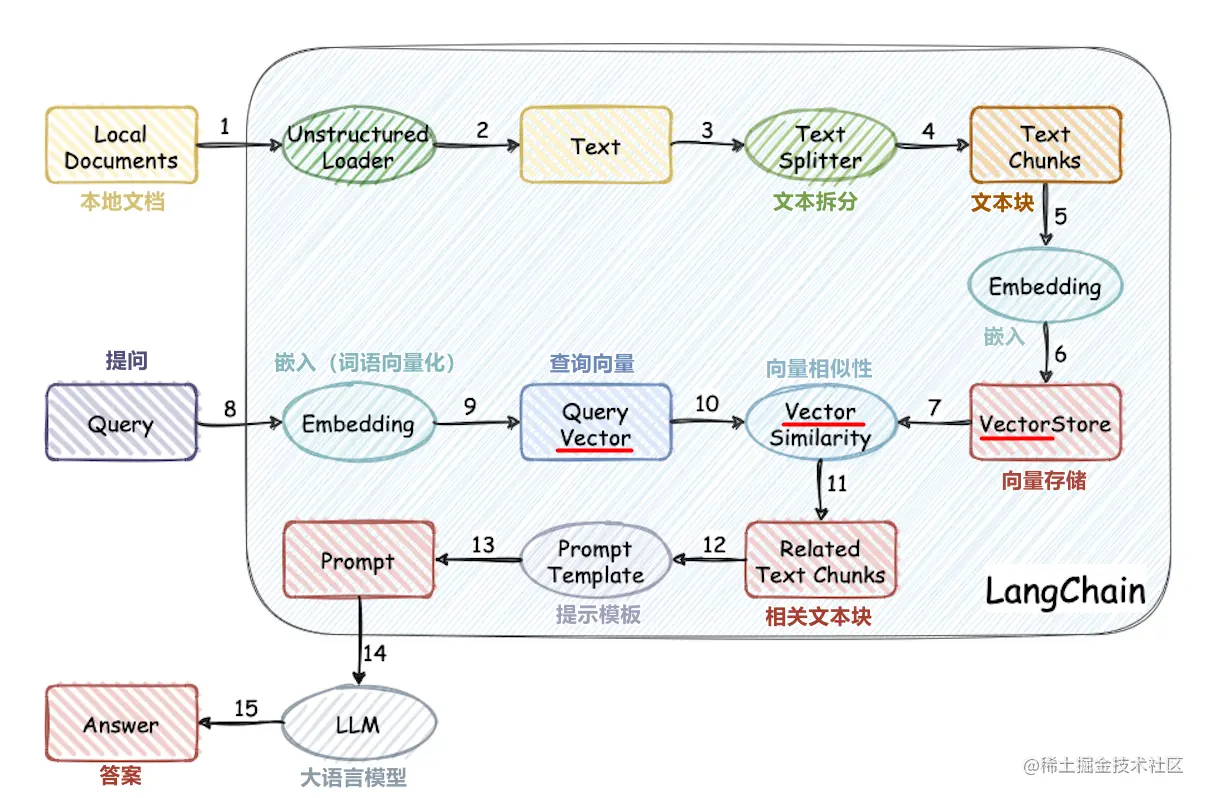
Структура проекта
- Корпус: папка, в которой хранятся базы знаний
- Данные: данные, связанные с обучением модели Word Vector (файл модели велик, пожалуйста, загрузите модель самостоятельно)
- DOC: исходный код и документация для обучения модели Word Vect
- llm_server: простое приложение базы знаний
- Vector_DB: Сохраните документ в корпусе в базу данных Qdrant Vector
- config.json: некоторые конфигурации проекта
- Openai_api_key: ключ API Openai
- Encedding_Model_Type: Текстовая векторизованная модель OpenAI или Word2VEC
- CHAT_MODEL_TYPE: диалог Mockup Openai или Chatglm
- Chatglm_port: порт для локального развертывания Chatglm
- ** Путь: некоторые пути, начиная с каталога корневой проекта
- Collection_name: имя коллекции базы данных векторных данных
бегать
Генерировать постоянную базу знаний
cd vector_db
pip install -r requirements.txt
python main.py
main.py автоматически создаст векторную базу данных с именем collection_name и сохранит векторы документа в папке корпуса в базу данных
Запустите приложение
cd llm_server
pip install -r requirements.txt
python main.py
Запустите локально развернутые чатгггм2-6B
Обратитесь к официальному документу Chatglm2-6b
Учебник


