Construya una gran base de conocimiento del trapo modelo desde cero
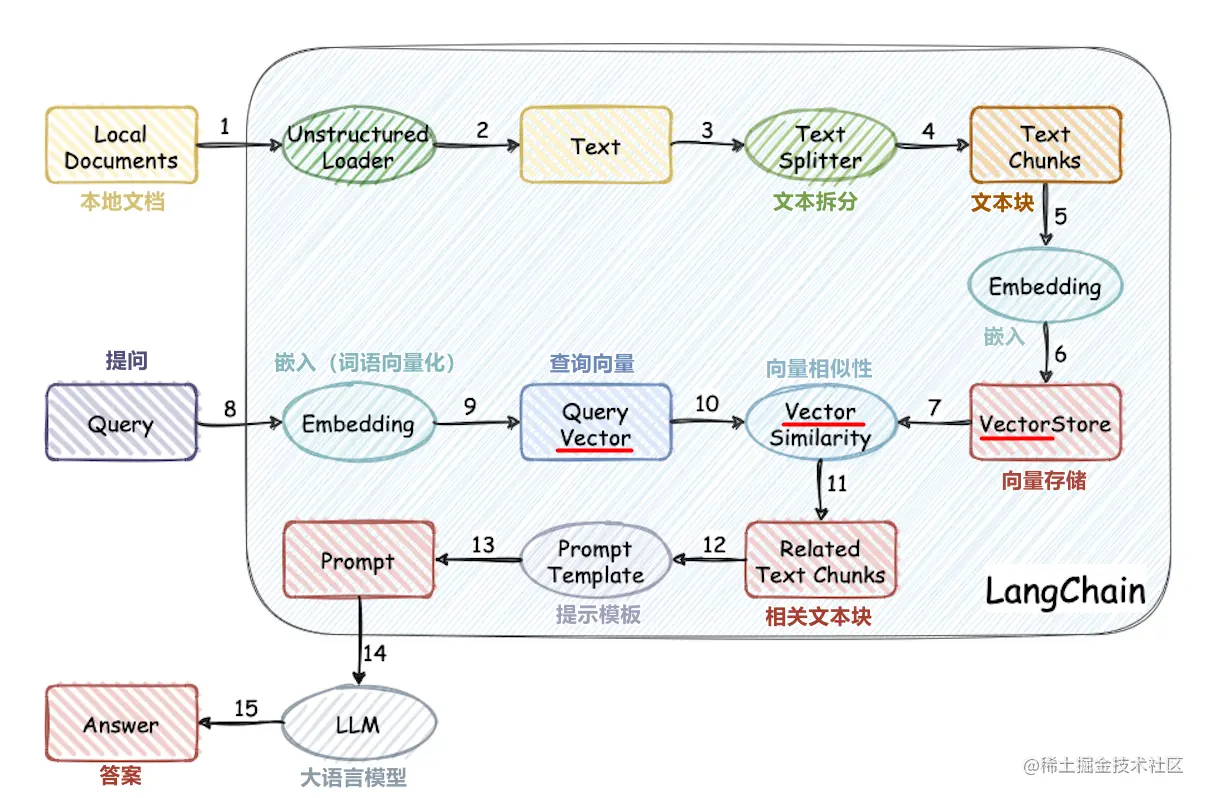
Este proyecto implementa el proceso de uso de la base de conocimiento externo para modelos grandes desde cero:
- Procesamiento del conjunto de datos chino
- Entrenamiento del modelo de vector de palabras
- Vectorización de documentos
- Base de conocimiento de almacenamiento de bases de datos vectoriales
- Chatglm2-6b local implementación de modelos grandes
- Aplicación de base de conocimiento simple
Estructura de proyectos
- Corpus: la carpeta donde se almacenan los documentos de la base de conocimiento
- Datos: Datos relacionados con la capacitación del modelo de Vector de Word (el archivo del modelo es grande, descargue el modelo usted mismo)
- DOC: Código fuente y documentación para la capacitación del modelo de Vector de Word
- LLM_SERVER: aplicación de base de conocimiento simple
- Vector_DB: Guarde el documento en Corpus en la base de datos QDRant Vector
- config.json: algunas configuraciones del proyecto
- OpenAI_API_KEY: clave API de Openai
- Incruscting_model_type: modelo de texto vectorizado OpenAI o word2vec
- Chat_model_type: maCkup de diálogo opadai o chatglm
- ChatGlm_port: puerto para la implementación local de chatglm
- ** Ruta: algunas rutas, comenzando desde el directorio de la raíz del proyecto
- Collection_Name: Nombre de la colección de bases de datos vectoriales
correr
Generar una base de conocimiento persistente
cd vector_db
pip install -r requirements.txt
python main.py
Main.py creará automáticamente una base de datos vectorial llamada Collection_Name y almacenará los vectores de documentos en la carpeta Corpus en la base de datos
Ejecutar la aplicación
cd llm_server
pip install -r requirements.txt
python main.py
Ejecute ChatGLM2-6b de implementación localmente
Consulte el documento oficial de ChatGlm2-6b
Tutorial


