처음부터 큰 모델 래그 지식 기반을 구축하십시오
이 프로젝트는 대형 모델에 외부 지식 기반을 처음부터 사용하는 프로세스를 시행합니다.
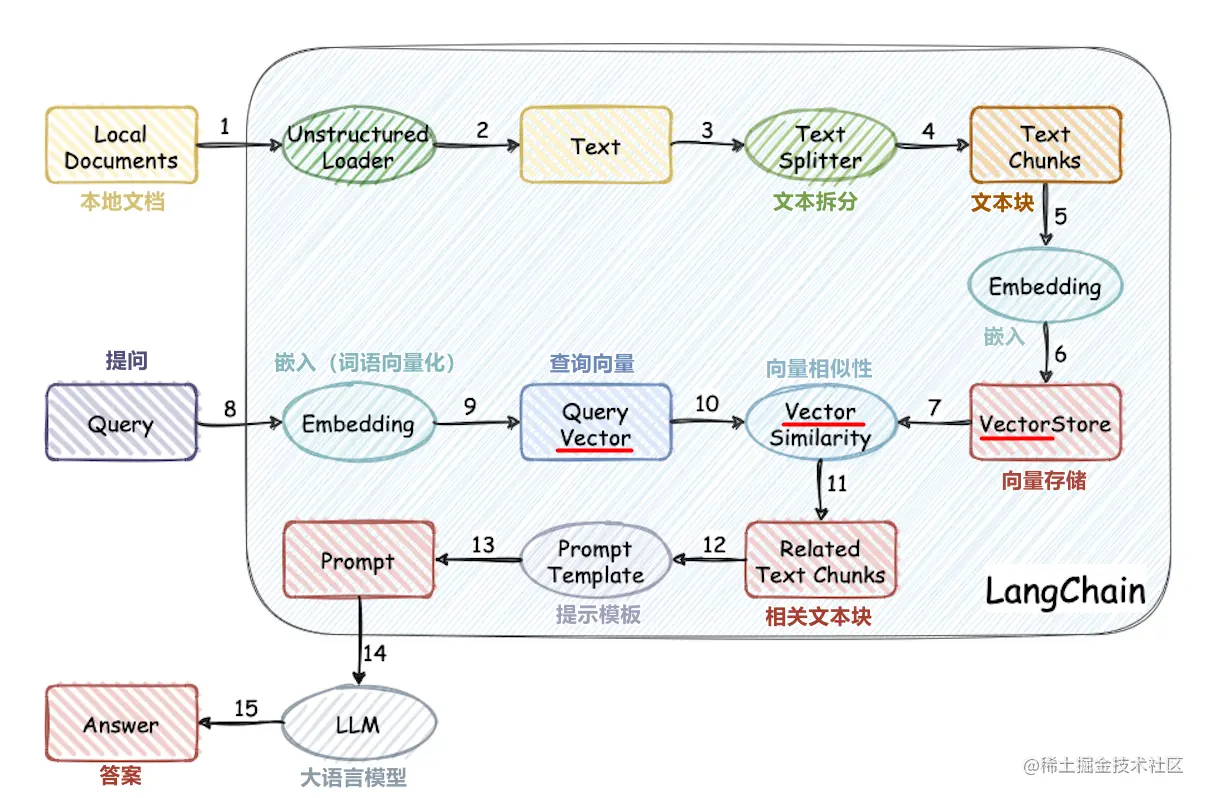
- 중국 데이터 세트 처리
- 단어 벡터 모델 교육
- 문서 벡터화
- 벡터 데이터베이스 스토리지 지식 기반
- 로컬 chatglm2-6b 대형 모델 배포
- 간단한 지식 기반 응용 프로그램
프로젝트 구조
- Corpus : 지식 기반 문서가 저장되는 폴더
- 데이터 : Word Vector Model Training과 관련된 데이터 (모델 파일은 크고 모델을 직접 다운로드하십시오).
- DOC : Word Vector 모델 교육에 대한 소스 코드 및 문서
- LLM_SERVER : 간단한 지식 기반 응용 프로그램
- Vector_DB : Corpus의 문서를 Qdrant Vector 데이터베이스에 저장
- config.json : 프로젝트의 일부 구성
- OpenAi_api_key : OpenAi의 API 키
- embedding_model_type : 텍스트 벡터화 된 모델 OpenAi 또는 Word2Vec
- chat_model_type : 대화 mockup openai 또는 chatglm
- chatglm_port : chatglm의 로컬 배포를위한 포트
- ** 경로 : 프로젝트 루트 디렉토리에서 시작하는 일부 경로
- Collection_Name : 벡터 데이터베이스 컬렉션의 이름
달리다
지속적인 지식 기반을 생성합니다
cd vector_db
pip install -r requirements.txt
python main.py
main.py는 collection_name이라는 벡터 데이터베이스를 자동으로 생성하고 문서 벡터를 코퍼스 폴더에 데이터베이스에 저장합니다.
응용 프로그램을 실행하십시오
cd llm_server
pip install -r requirements.txt
python main.py
로컬로 배포 된 ChatGLM2-6B를 실행하십시오
ChatGLM2-6B의 공식 문서를 참조하십시오
지도 시간


