Construa uma grande base de conhecimentos de pano de modelo do zero
Este projeto implementa o processo de usar a base de conhecimento externa para modelos grandes do zero:
- Processamento do conjunto de dados chinês
- Treinamento de modelo de vetor de palavras
- Vectorização de documentos
- Base de conhecimento de armazenamento de banco de dados vetorial
- Implantação de modelo de grande modelo de chatglm2-6b local
- Aplicação simples da base de conhecimento
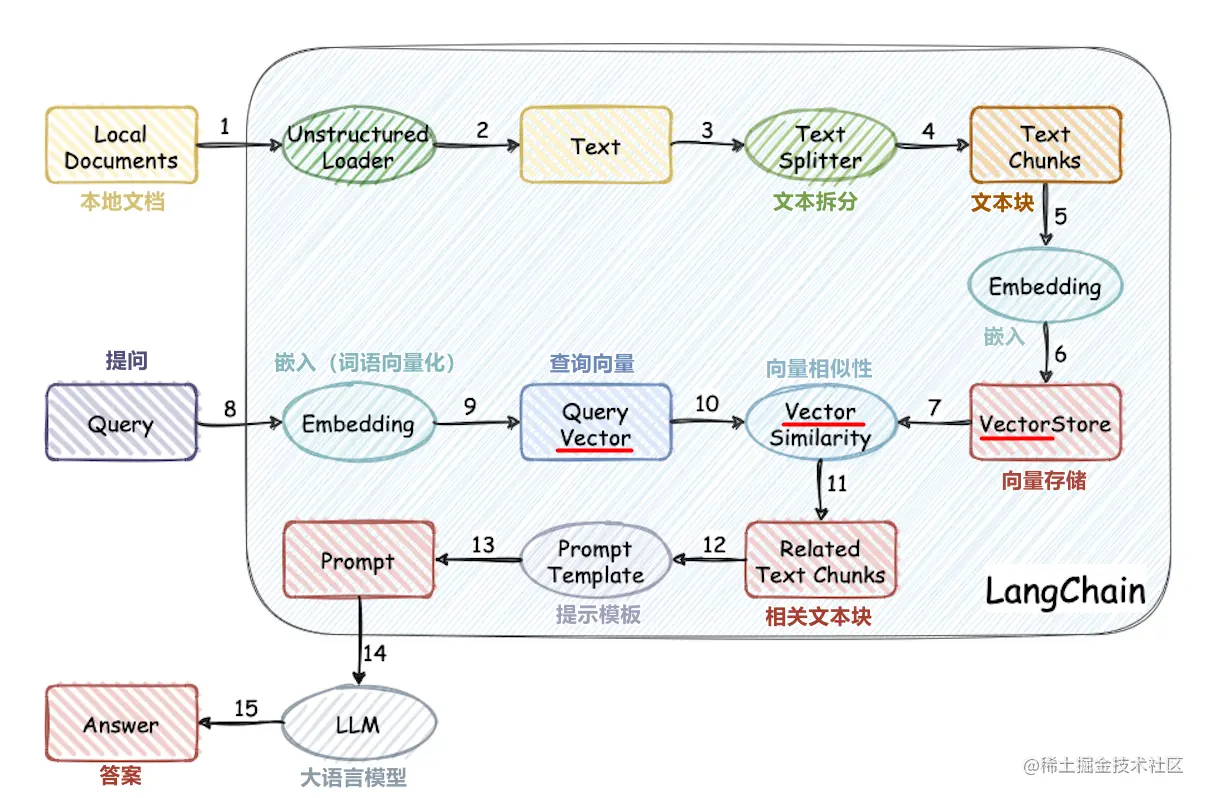
Estrutura do projeto
- corpus: a pasta onde os documentos da base de conhecimento são armazenados
- Dados: Dados relacionados ao treinamento do modelo de vetor de palavras (o arquivo do modelo é grande, faça o download do modelo)
- DOC: Código Fonte e Documentação para Treinamento para Modelo de Vetor de Palavras
- LLM_SERVER: Aplicação simples da base de conhecimento
- Vector_db: salve o documento em corpus no banco de dados de vetor QDRANT
- config.json: Algumas configurações do projeto
- OpenAi_API_KEY: Chave da API do OpenAI
- Incorpingding_model_type: modelo vetorizado de texto open ou word2vec
- Chat_model_type: maquete de diálogo OpenAI ou chatglm
- Chatglm_port: Porta para implantação local de chatglm
- ** Caminho: alguns caminhos, começando pelo diretório raiz do projeto
- Coleção_name: Nome da coleção de banco de dados vetorial
correr
Gerar base de conhecimento persistente
cd vector_db
pip install -r requirements.txt
python main.py
Main.py criará automaticamente um banco de dados vetorial chamado coleção_name e armazenará os vetores de documentos na pasta corpus no banco de dados
Execute o aplicativo
cd llm_server
pip install -r requirements.txt
python main.py
Run Localmente implantado Chatglm2-6b
Consulte o documento oficial do chatglm2-6b
Tutorial


