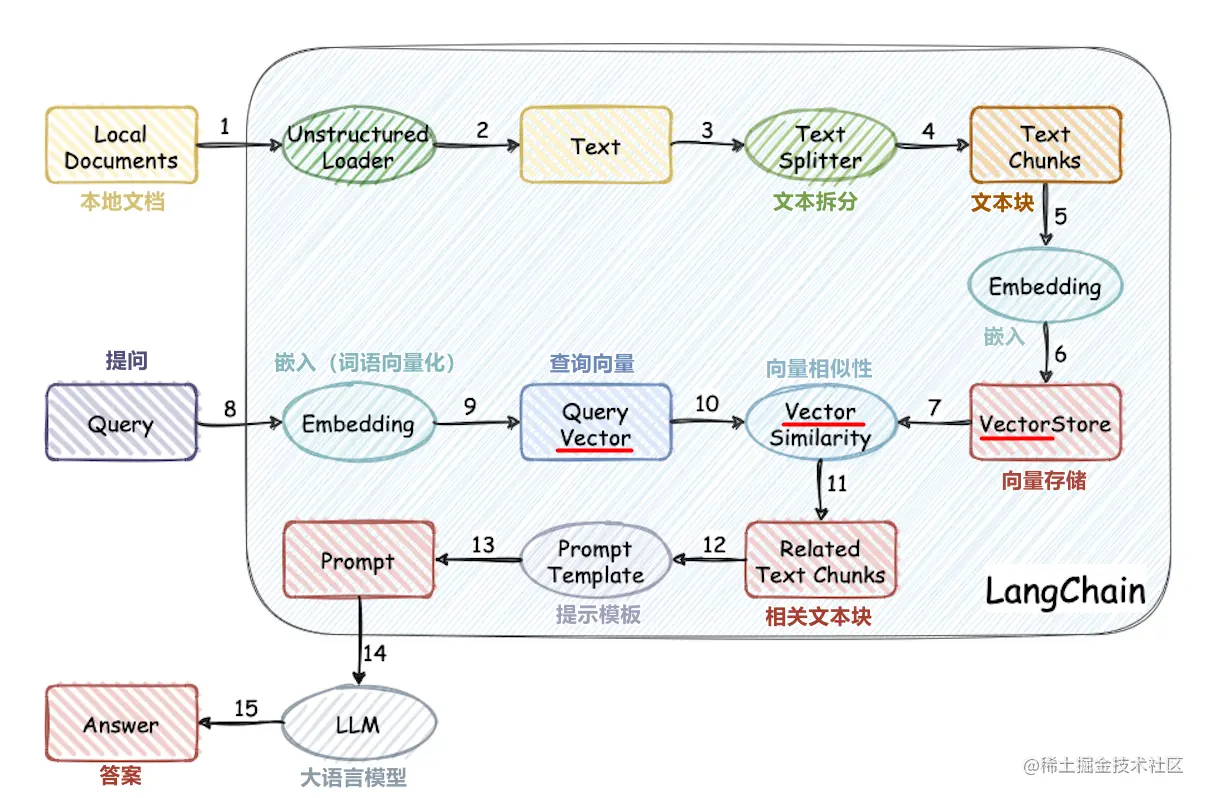
Bangun basis pengetahuan Rag Model Besar dari awal
Proyek ini mengimplementasikan proses penggunaan basis pengetahuan eksternal untuk model besar dari awal:
- Pemrosesan kumpulan data Cina
- Pelatihan Model Vektor Kata
- Vektorisasi dokumen
- Basis pengetahuan penyimpanan basis data vektor
- Penyebaran Model Besar ChatGlM2-6B Lokal
- Aplikasi Basis Pengetahuan Sederhana
Struktur proyek
- Corpus: Folder tempat dokumen basis pengetahuan disimpan
- Data: Data yang Terkait dengan Pelatihan Model Vektor Kata (file modelnya besar, silakan unduh modelnya sendiri)
- DOC: Kode Sumber dan Dokumentasi untuk Pelatihan Model Vektor Kata
- LLM_SERVER: Aplikasi Basis Pengetahuan Sederhana
- Vector_DB: Simpan dokumen dalam corpus ke dalam database qdrant vector
- config.json: Beberapa konfigurasi proyek
- OpenAI_API_KEY: Kunci API Openai
- Embedding_model_type: model vektor teks openai atau word2vec
- Chat_model_type: dialog mockup openai atau chatglm
- Chatglm_port: port untuk penyebaran lokal chatglm
- ** Path: Beberapa jalur, mulai dari direktori root proyek
- Collection_name: Nama koleksi database vektor
berlari
Menghasilkan basis pengetahuan yang persisten
cd vector_db
pip install -r requirements.txt
python main.py
Main.py akan secara otomatis membuat database vektor bernama collection_name dan menyimpan vektor dokumen di folder corpus ke dalam database
Jalankan aplikasi
cd llm_server
pip install -r requirements.txt
python main.py
Jalankan chatglm2-6b yang digunakan secara lokal
Lihat dokumen resmi chatglm2-6b
Tutorial


