Construisez une base de connaissances de chiffon de grand modèle à partir de zéro
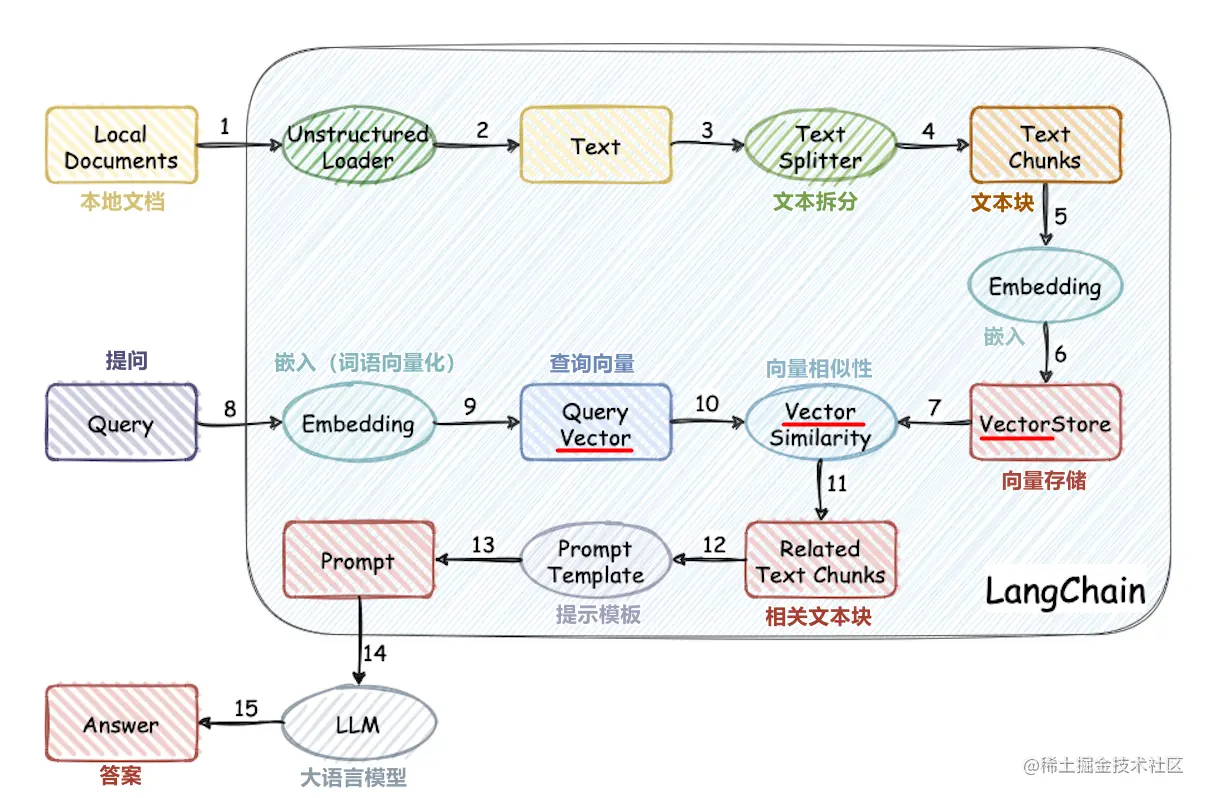
Ce projet met en œuvre le processus d'utilisation de la base de connaissances externe pour les grands modèles à partir de zéro:
- Traitement de l'ensemble de données chinois
- Formation du modèle de vecteur de mots
- Document Vectorisation
- Base de connaissances de stockage de base de données vectorielle
- Déploiement de gros modèle local chatGLM2-6B
- Application de base de connaissances simple
Structure du projet
- Corpus: le dossier où les documents de base de connaissances sont stockés
- Données: données liées à la formation du modèle de vecteur de mots (le fichier du modèle est grand, veuillez télécharger le modèle vous-même)
- Doc: code source et documentation pour la formation du modèle de vecteur de mots
- LLM_SERVER: Application de base de connaissances simple
- VECTOR_DB: Enregistrez le document dans Corpus dans la base de données vectorielle QDRANT
- config.json: quelques configurations du projet
- Openai_api_key: clé API d'Openai
- Embedding_Model_Type: modèle vectorisé de texte OpenAI ou Word2Vec
- CHAT_MODEL_TYPE: Dialogue Mockup Openai ou ChatGlm
- Chatglm_port: port pour le déploiement local de chatGlm
- ** Chemin: certains chemins, à partir du répertoire racine du projet
- Collection_name: Nom de la collection de base de données vectorielle
courir
Générer une base de connaissances persistante
cd vector_db
pip install -r requirements.txt
python main.py
main.py créera automatiquement une base de données vectorielle nommée Collection_name et stockera les vecteurs de document dans le dossier Corpus dans la base de données
Exécuter l'application
cd llm_server
pip install -r requirements.txt
python main.py
Exécutez ChatGlm2-6b localement déployé
Reportez-vous au document officiel de chatGlm2-6b
Tutoriel


