pragYantra
1.0.0
Pragyantra เป็นโครงการซอฟต์แวร์ง่าย ๆ ที่ออกแบบมาเพื่อจำลองหุ่นยนต์มนุษย์ด้วยการมองเห็นการได้ยินการพูดและการทำงานของหน่วยความจำ โครงการนี้มีจุดมุ่งหมายเพื่อสร้างแพลตฟอร์มที่ยืดหยุ่นสำหรับการทดลองกับปัญญาประดิษฐ์และการมีปฏิสัมพันธ์กับเครื่องจักรของมนุษย์ ณ ตอนนี้มันเป็นเหมือน LLM แต่ด้วยความสามารถที่ขยายออกไปทำให้สามารถมองเห็นได้ยินและมีส่วนร่วมในการสื่อสารด้วยวาจา
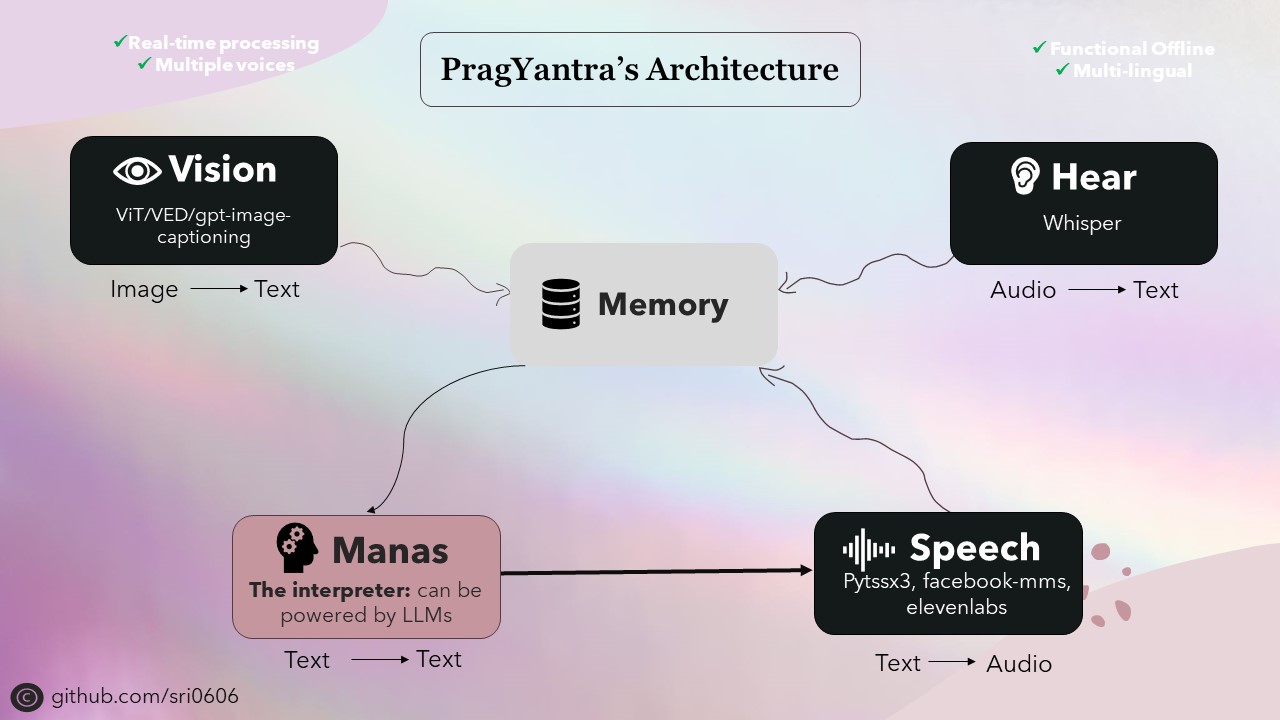
ฉันจัดลำดับความสำคัญของ Pragyantra เพื่อให้มีความสามารถออฟไลน์ในขณะเดียวกันก็รวมฟังก์ชั่นออนไลน์ เพื่อให้บรรลุเป้าหมายนี้ส่วนประกอบทั้งหมดของโครงการได้รับการออกแบบให้มีความสามารถออฟไลน์พร้อมฟังก์ชันการทำงานออนไลน์เป็นคุณสมบัติเสริม ในขณะที่ใช้โหมดออฟไลน์อาจต้องใช้อุปกรณ์ที่แข็งแกร่งกว่าสำหรับการอนุมานที่เร็วขึ้นโครงการทำงานได้อย่างสมบูรณ์และทำงานได้อย่างน่าชื่นชมภายใต้เงื่อนไขเหล่านี้
กระดูกสันหลังของ Pragyantra ประกอบด้วยโมเดลโอเพนซอร์ซต่าง ๆ สำหรับงานเช่นข้อความเป็นคำพูดการพูดข้อความเป็นข้อความข้อความและข้อความเป็นข้อความและการแปลงภาพเป็นข้อความ โมเดลเหล่านี้ทำหน้าที่เป็นหน่วยการสร้างที่สถาปัตยกรรมของ Pragyantra ถูกสร้างขึ้นพร้อมกับความสามารถเพิ่มเติมและการรวมตัวกันพร้อมกันอย่างราบรื่นเพื่อเพิ่มประสิทธิภาพโดยรวมและประสบการณ์ผู้ใช้
Pragyantra ที่ได้มาจากภาษาสันสกฤตเป็นคำศัพท์สองคำ: "prag" หมายถึงชาญฉลาดหรือฉลาดและ "Yantra" หมายถึงเครื่องจักรหรือหุ่นยนต์ ดังนั้นเมื่อรวมเข้าด้วยกัน Pragyantra รวบรวมแนวคิดของเครื่องอัจฉริยะสะท้อนให้เห็นถึงเป้าหมายของโครงการในการสร้างแพลตฟอร์มที่ยืดหยุ่นสำหรับการทดลองกับ AI และการมีปฏิสัมพันธ์กับเครื่องจักรของมนุษย์
หากต้องการตั้งค่าโครงการให้ทำตามขั้นตอนเหล่านี้:
โคลนที่เก็บ:
git clone https://github.com/sri0606/pragyantra.git
นำทางไปยังไดเรกทอรีโครงการ:
cd pragyantra
เรียกใช้สคริปต์การตั้งค่า:
python setup.py
หรือ
chmod +x setup.sh
./setup.sh
bash setup.sh
สคริปต์การตั้งค่าจะติดตั้งการอ้างอิงดาวน์โหลดรุ่นที่ต้องการและสร้างไดเรกทอรีที่จำเป็น
สำหรับความช่วยเหลือเรียกใช้คำสั่งต่อไปนี้:
python main.py --help
คำสั่งตัวอย่าง:
โหมดออฟไลน์
python main.py --interpreter_model llama3_8B --offline_mode --speaker_model pyttsx3โหมดออนไลน์
python main.py --interpreter_model llama3-70B-8192 --speaker_model pyttsx3
or
python main.py --interpreter_model mixtral-8x7b-32768 --speaker_model 11labs @misc {nlp_connect_2022,
author = { {NLP Connect} },
title = { vit-gpt2-image-captioning (Revision 0e334c7) },
year = 2022,
url = { https://huggingface.co/nlpconnect/vit-gpt2-image-captioning },
doi = { 10.57967/hf/0222 },
publisher = { Hugging Face }
}
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


