pragYantra
1.0.0
Pragyantra ist ein einfaches Softwareprojekt, das einen humanoiden Roboter mit Seh-, Hör-, Sprach- und Gedächtnisfunktionalitäten simulieren soll. Dieses Projekt zielt darauf ab, eine flexible Plattform zum Experimentieren mit künstlicher Intelligenz und Interaktion zwischen Mensch und Maschine zu schaffen. Ab sofort ist es eher wie ein LLM, aber mit verlängerten Fähigkeiten, sodass sie verbale Kommunikation sehen, hören und engagieren können.
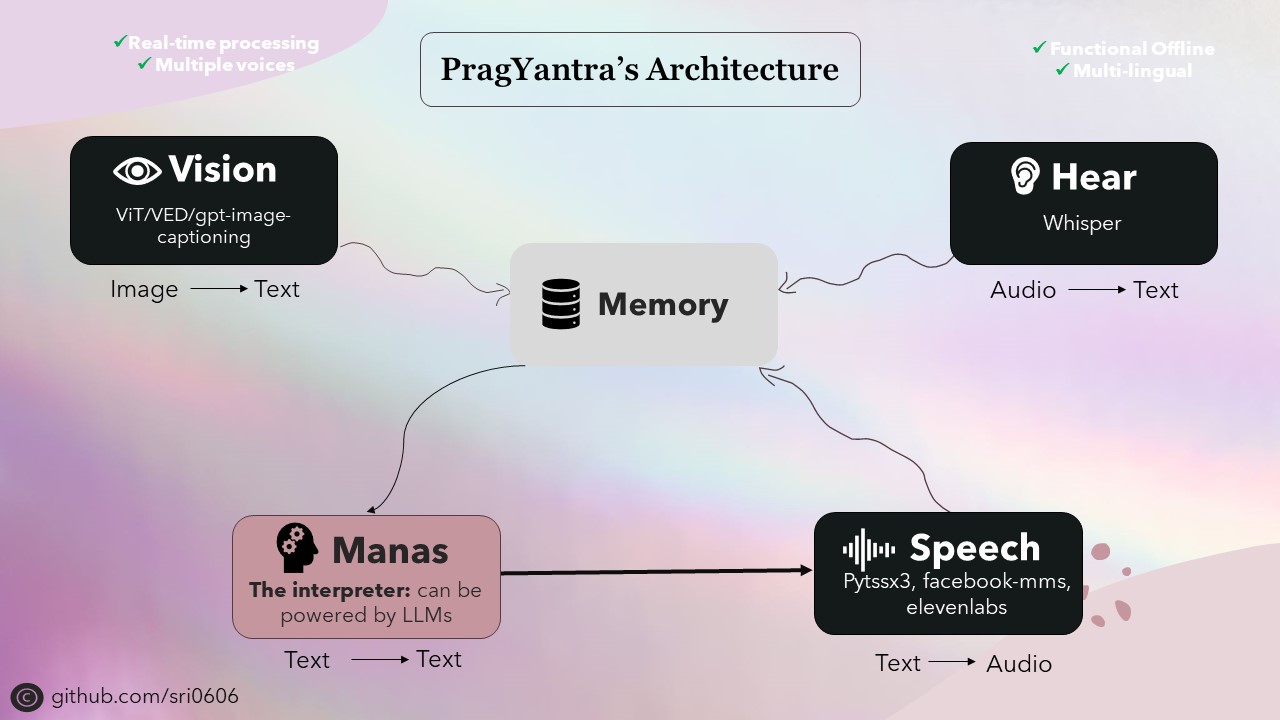
Ich habe Pragyantra priorisiert, um Offline -Funktionen zu haben und gleichzeitig Online -Funktionen zu integrieren. Um dies zu erreichen, wurden alle Komponenten des Projekts so konzipiert, dass sie Offline -Funktionen haben, wobei Online -Funktionen als optionale Funktionen verfügbar sind. Während die Verwendung des Offline -Modus möglicherweise ein stärkeres Gerät für eine schnellere Inferenz erfordern, ist das Projekt voll funktionsfähig und führt unter diesen Bedingungen bewundernswert durch.
Das Rückgrat von Pragyantra besteht aus verschiedenen Open-Source-Modellen für Aufgaben wie Text-to-Speech, Speech-to-Text, Text-to-Text und Image-to-Text-Konvertierung. Diese Modelle dienen als Bausteine, auf denen die Architektur von Pragyantra aufgebaut ist und zusätzliche Funktionen und Parallelität nahtlos integriert ist, um die Gesamtleistung und die Benutzererfahrung zu verbessern.
Pragyantra, abgeleitet von Sanskrit, ist eine Verschmelzung von zwei Wörtern: "Prag" bedeutet intelligent oder weise und "Yantra", die sich auf Maschine oder Roboter beziehen. Also, zusammen, verkörpert Pragyantra das Konzept einer intelligenten Maschine und spiegelt das Ziel des Projekts wider, eine flexible Plattform für das Experimentieren mit KI und Human-Maschinen-Interaktion zu schaffen.
Um das Projekt einzurichten, befolgen Sie die folgenden Schritte:
Klonen Sie das Repository:
git clone https://github.com/sri0606/pragyantra.git
Navigieren Sie zum Projektverzeichnis:
cd pragyantra
Führen Sie das Setup -Skript aus:
python setup.py
ODER
chmod +x setup.sh
./setup.sh
bash setup.sh
Das Setup -Skript installiert die Abhängigkeiten, lädt die erforderlichen Modelle herunter und erstellt die erforderlichen Verzeichnisse.
Führen Sie für Hilfe den folgenden Befehl aus:
python main.py --help
Beispielbefehle:
Offline -Modus
python main.py --interpreter_model llama3_8B --offline_mode --speaker_model pyttsx3Online -Modus
python main.py --interpreter_model llama3-70B-8192 --speaker_model pyttsx3
or
python main.py --interpreter_model mixtral-8x7b-32768 --speaker_model 11labs @misc {nlp_connect_2022,
author = { {NLP Connect} },
title = { vit-gpt2-image-captioning (Revision 0e334c7) },
year = 2022,
url = { https://huggingface.co/nlpconnect/vit-gpt2-image-captioning },
doi = { 10.57967/hf/0222 },
publisher = { Hugging Face }
}
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


