pragYantra
1.0.0
Pragyantra es un proyecto de software simple diseñado para simular un robot humanoide con funcionalidades de visión, audición, habla y memoria. Este proyecto tiene como objetivo crear una plataforma flexible para experimentar con inteligencia artificial e interacción humana-máquina. A partir de ahora, es más como un LLM, pero con capacidades extendidas, lo que permite ver, escuchar y participar en la comunicación verbal.
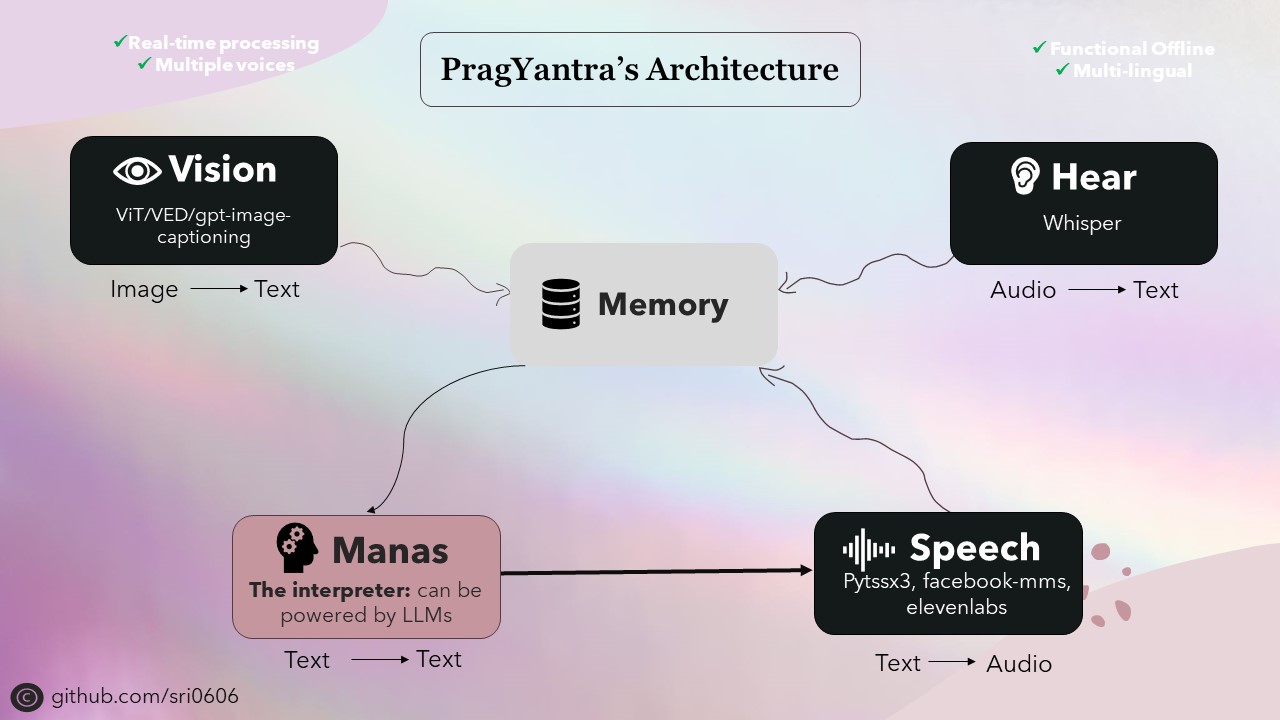
Prioricé a Pragyantra para tener capacidades fuera de línea y al mismo tiempo integrar las funcionalidades en línea. Para lograr esto, todos los componentes del proyecto fueron diseñados para tener capacidades fuera de línea, con funcionalidades en línea disponibles como características opcionales. Si bien el uso del modo fuera de línea puede requerir un dispositivo más fuerte para una inferencia más rápida, el proyecto es completamente funcional y funciona admirablemente en estas condiciones.
La columna vertebral de Pragyantra consta de varios modelos de código abierto para tareas como texto a voz, habla a texto, texto a texto y conversión de imagen a texto. Estos modelos sirven como bloques de construcción en los que se construye la arquitectura de Pragyantra, con capacidades adicionales y concurrencia sin problemas para mejorar el rendimiento general y la experiencia del usuario.
Pragyantra, derivado del sánscrito, es una fusión de dos palabras: "prag" que significa inteligente o sabio, y "yantra" que se refiere a la máquina o el robot. Entonces, elaborado, Pragyantra encarna el concepto de una máquina inteligente, lo que refleja el objetivo del proyecto de crear una plataforma flexible para experimentar con IA y la interacción humana-máquina.
Para configurar el proyecto, siga estos pasos:
Clon el repositorio:
git clone https://github.com/sri0606/pragyantra.git
Navegue al directorio del proyecto:
cd pragyantra
Ejecute el script de configuración:
python setup.py
O
chmod +x setup.sh
./setup.sh
bash setup.sh
El script de configuración instalará las dependencias, descargará los modelos requeridos y creará los directorios necesarios.
Para obtener ayuda, ejecute el siguiente comando:
python main.py --help
Comandos de ejemplo:
Modo fuera de línea
python main.py --interpreter_model llama3_8B --offline_mode --speaker_model pyttsx3Modo en línea
python main.py --interpreter_model llama3-70B-8192 --speaker_model pyttsx3
or
python main.py --interpreter_model mixtral-8x7b-32768 --speaker_model 11labs @misc {nlp_connect_2022,
author = { {NLP Connect} },
title = { vit-gpt2-image-captioning (Revision 0e334c7) },
year = 2022,
url = { https://huggingface.co/nlpconnect/vit-gpt2-image-captioning },
doi = { 10.57967/hf/0222 },
publisher = { Hugging Face }
}
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


