pragYantra
1.0.0
Pragyantra - это простой программный проект, предназначенный для имитации гуманоидного робота с визуальным, слухом, речи и функциональностью памяти. Этот проект направлен на создание гибкой платформы для экспериментов с искусственным интеллектом и человеческим взаимодействием. На данный момент он больше похож на LLM, но с расширенными возможностями, позволяя ему видеть, слышать и участвовать в устной связи.
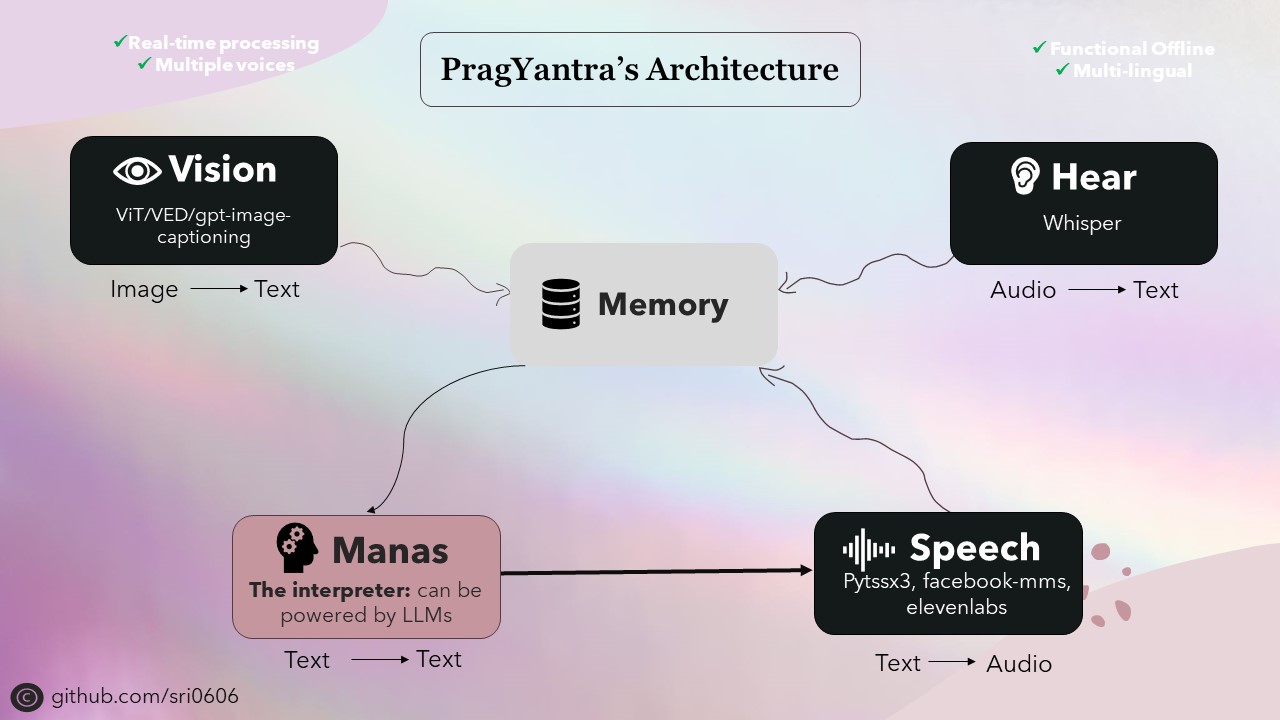
Я приоритет Pragyantra обладать офлайн -возможностями, а также интегрировал онлайн -функции. Для достижения этого все компоненты проекта были разработаны, чтобы иметь автономные возможности, с онлайн -функциональными возможностями, доступными в качестве дополнительных функций. Хотя использование автономного режима может потребовать более сильного устройства для более быстрого вывода, проект полностью функционален и работает превосходно в этих условиях.
Оболочка Pragyantra состоит из различных моделей с открытым исходным кодом для таких задач, как текст в речь, речь в тексте, текстовый текст и конверсия изображения в текст. Эти модели служат строительными блоками, на которых строится архитектура Pragyantra, с дополнительными возможностями и параллелизмом плавно интегрированы для повышения общей производительности и пользовательского опыта.
Pragyantra, полученная от санскрита, представляет собой слияние двух слов: «Prag», означающий интеллектуальные или мудрые, и «янтра», относящаяся к машине или роботу. Итак, собравшись, Pragyantra воплощает концепцию интеллектуальной машины, отражая цель проекта-создать гибкую платформу для экспериментов с ИИ и человеческим взаимодействием.
Чтобы настроить проект, следуйте этим шагам:
Клонировать репозиторий:
git clone https://github.com/sri0606/pragyantra.git
Перейдите к каталогу проекта:
cd pragyantra
Запустите скрипт настройки:
python setup.py
ИЛИ
chmod +x setup.sh
./setup.sh
bash setup.sh
Сценарий настройки установит зависимости, загружает необходимые модели и создаст необходимые каталоги.
Для получения помощи, запустите следующую команду:
python main.py --help
Пример команд:
Автономный режим
python main.py --interpreter_model llama3_8B --offline_mode --speaker_model pyttsx3Онлайн -режим
python main.py --interpreter_model llama3-70B-8192 --speaker_model pyttsx3
or
python main.py --interpreter_model mixtral-8x7b-32768 --speaker_model 11labs @misc {nlp_connect_2022,
author = { {NLP Connect} },
title = { vit-gpt2-image-captioning (Revision 0e334c7) },
year = 2022,
url = { https://huggingface.co/nlpconnect/vit-gpt2-image-captioning },
doi = { 10.57967/hf/0222 },
publisher = { Hugging Face }
}
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


