pragYantra
1.0.0
Pragyantra est un projet logiciel simple conçu pour simuler un robot humanoïde avec vision, audition, parole et fonctionnalités de la mémoire. Ce projet vise à créer une plate-forme flexible pour expérimenter l'intelligence artificielle et l'interaction humaine-machine. Pour l'instant, cela ressemble plus à un LLM, mais avec des capacités étendues, en lui permettant de voir, d'entendre et de s'engager dans une communication verbale.
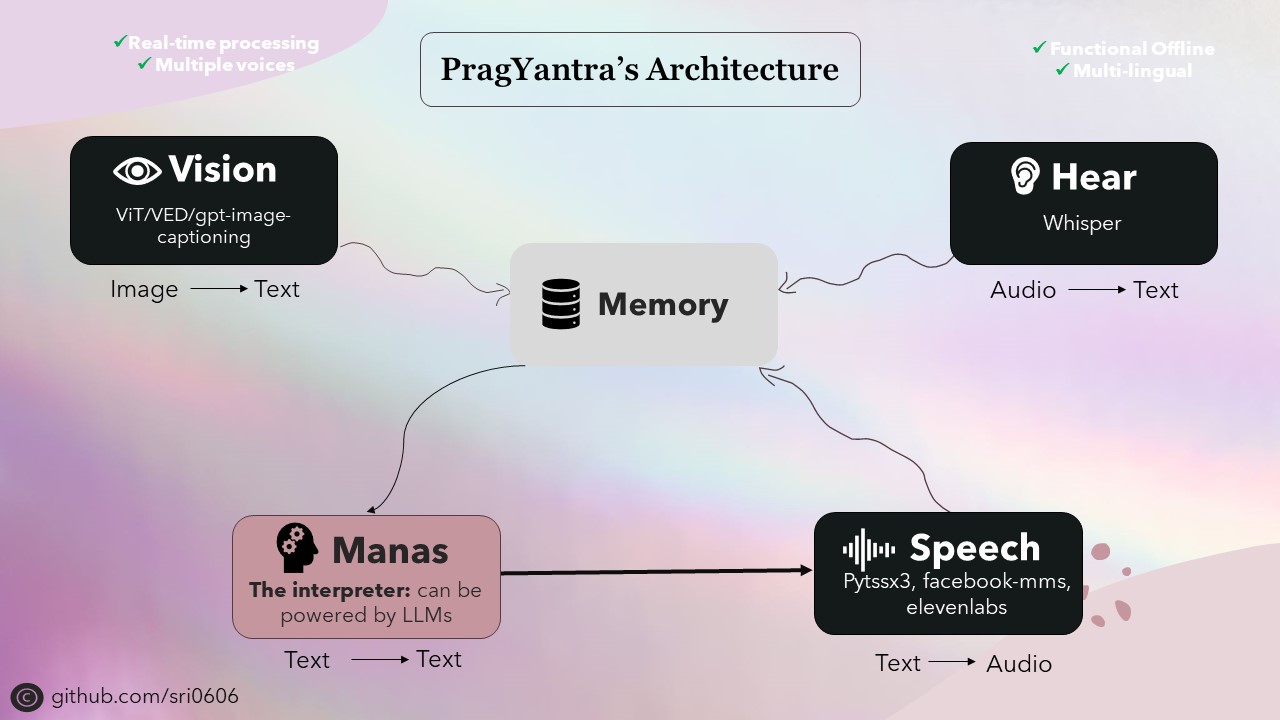
J'ai priorisé Pragyantra pour avoir des capacités hors ligne tout en intégrant également les fonctionnalités en ligne. Pour y parvenir, toutes les composantes du projet ont été conçues pour avoir des capacités hors ligne, avec des fonctionnalités en ligne disponibles en fonctionnalités facultatives. Bien que l'utilisation du mode hors ligne puisse nécessiter un appareil plus fort pour une inférence plus rapide, le projet est entièrement fonctionnel et fonctionne admirablement dans ces conditions.
L'épine dorsale de Pragyantra se compose de divers modèles open source pour des tâches telles que la conversion de texte à la parole, de la parole en texte, du texte-texte et de l'image-texte. Ces modèles servent de blocs de construction sur lesquels l'architecture de Pragyantra est construite, avec des capacités supplémentaires et une concurrence parfaitement intégrée pour améliorer les performances globales et l'expérience utilisateur.
Pragyantra, dérivé du sanskrit, est une fusion de deux mots: "prag" signifiant intelligent ou sage, et "yantra" se référant à la machine ou au robot. Ainsi, assemblé, Pragyantra incarne le concept d'une machine intelligente, reflétant l'objectif du projet de créer une plate-forme flexible pour expérimenter l'interaction IA et humaine-machine.
Pour configurer le projet, suivez ces étapes:
Clone le référentiel:
git clone https://github.com/sri0606/pragyantra.git
Accédez au répertoire du projet:
cd pragyantra
Exécutez le script de configuration:
python setup.py
OU
chmod +x setup.sh
./setup.sh
bash setup.sh
Le script de configuration installera les dépendances, téléchargera les modèles requis et créera les répertoires nécessaires.
Pour obtenir de l'aide, exécutez la commande suivante:
python main.py --help
Exemples de commandes:
Mode hors ligne
python main.py --interpreter_model llama3_8B --offline_mode --speaker_model pyttsx3Mode en ligne
python main.py --interpreter_model llama3-70B-8192 --speaker_model pyttsx3
or
python main.py --interpreter_model mixtral-8x7b-32768 --speaker_model 11labs @misc {nlp_connect_2022,
author = { {NLP Connect} },
title = { vit-gpt2-image-captioning (Revision 0e334c7) },
year = 2022,
url = { https://huggingface.co/nlpconnect/vit-gpt2-image-captioning },
doi = { 10.57967/hf/0222 },
publisher = { Hugging Face }
}
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


