literary alpaca2
1.0.0

ตั้งแต่คำศัพท์ไปจนถึงการปรับแต่งนี่คือทุกสิ่งที่คุณต้องการ
พื้นที่เก็บข้อมูลนี้จะแสดงวิธีการสร้างคำศัพท์ของคุณเองจากคำศัพท์และใช้รูปแบบท่าเรือก่อนการฝึกอบรมและปรับตัวอย่างรหัสในที่เก็บส่วนใหญ่ได้รับการฝึกฝนตามเวอร์ชันการกอดของ Llama2 เนื่องจากพลังงานที่ จำกัด ของผู้เขียนมีข้อบกพร่องในสคริปต์ TPU ซึ่งใช้สำหรับการอ้างอิงเท่านั้น
| พิมพ์ | อธิบาย |
|---|---|
| นวนิยายออนไลน์ | ข้อมูลข้อความยาวคุณภาพสูง |
| Math23K | ปัญหาคณิตศาสตร์จีน |
| LCCC | ชุดบทสนทนาโอเพนซอร์สจีน |
วิธีใช้ชุดข้อมูล LCCC:
from datasets import load_dataset
dataset = load_dataset("lccc", "base") # or "large"
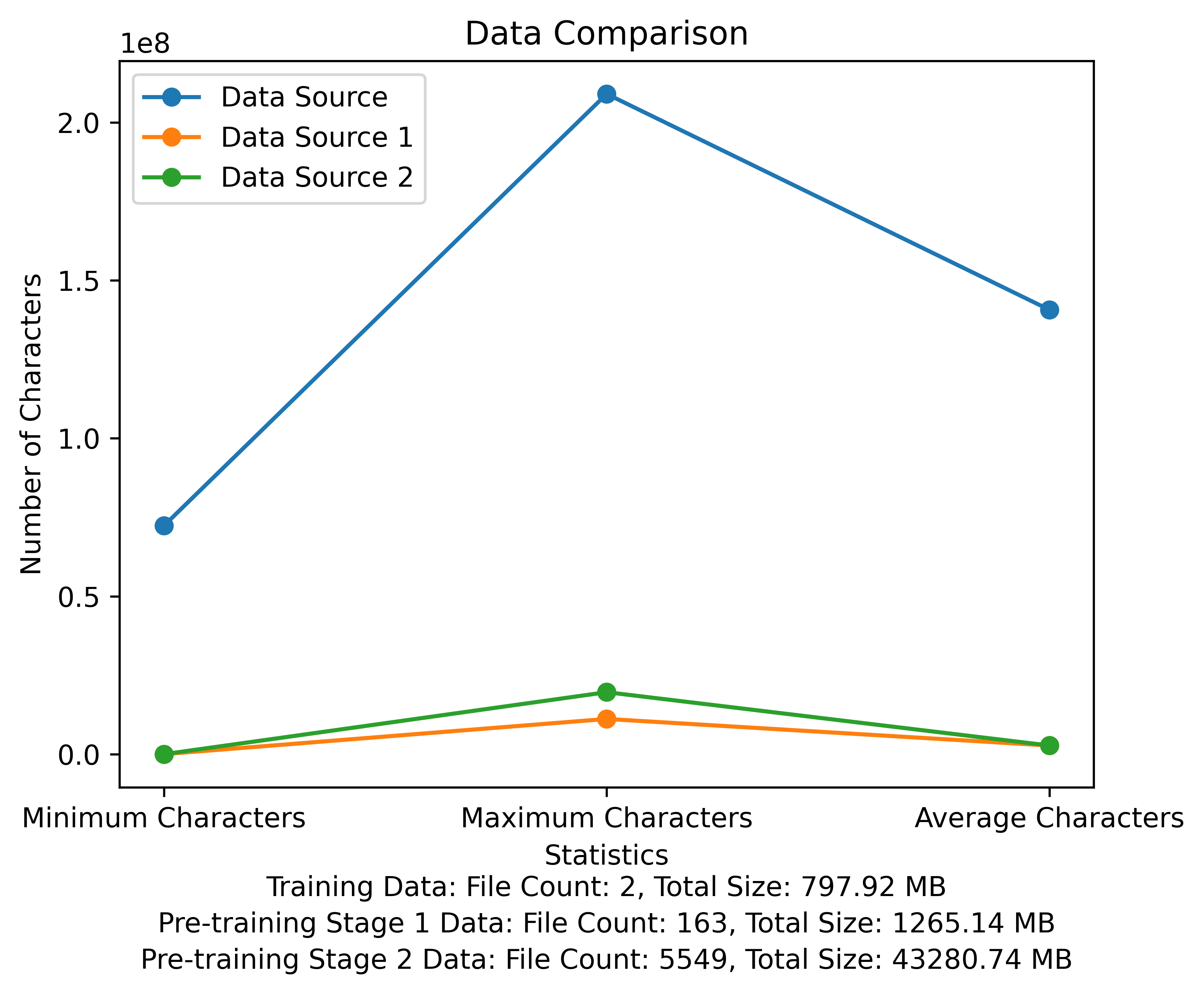
รายการคำศัพท์และแผนภาพการเปรียบเทียบข้อมูลของขั้นตอนการฝึกอบรมก่อน รูปแสดงจำนวนไฟล์และขนาดไฟล์ทั้งหมดของแต่ละแหล่งข้อมูลและเปรียบเทียบอักขระขั้นต่ำและสูงสุดและจำนวนอักขระเฉลี่ยในแต่ละไฟล์:
ลิงค์ดาวน์โหลดอย่างเป็นทางการของ Meta: https://huggingface.co/meta-llama
โมเดลที่ผ่านการฝึกอบรมก่อนภาษาจีนพารามิเตอร์ LORA และโมเดลแชทได้รับการอัปโหลดไปยังใบหน้ากอด ปัจจุบันมีเพียง 13b รุ่น
| หมวดหมู่ | ? ชื่อรุ่น | รุ่นฐาน | ดาวน์โหลดที่อยู่ |
|---|---|---|---|
| การฝึกอบรมล่วงหน้า | Taotie1/วรรณกรรม -alpaca2-13b | meta-llama/llama-2-13b-hf | ดาวน์โหลดรุ่น |
| Lora | Taotie1/วรรณกรรม -alpaca2-13b-lora | Taotie1/วรรณกรรม -alpaca2-13b | ดาวน์โหลดรุ่น |
| หมวดหมู่ | ? ชื่อรุ่น | ดาวน์โหลดที่อยู่ |
|---|---|---|
| แชท | taotie1/วรรณกรรม-อัลปาคา 2-13b-chat | ดาวน์โหลดรุ่น |
ตามข้อกำหนดของ TXT การติดตั้งสภาพแวดล้อมการติดตั้งโปรดเลือกเวอร์ชันของการติดตั้งไฟฉายตามอุปกรณ์ของคุณ
import torch
from transformers import AutoTokenizer , AutoModelForCausalLM
model = AutoModelForCausalLM . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , device_map = 'auto' , torch_dtype = torch . float16 , load_in_8bit = True )
model = model . eval ()
tokenizer = AutoTokenizer . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , use_fast = False )
tokenizer . pad_token = tokenizer . eos_token
input_ids = tokenizer ([ '<s>Human: 什么是计算机n </s><s>Assistant: ' ], return_tensors = "pt" , add_special_tokens = False ). input_ids . to ( 'cuda' )
generate_input = {
"input_ids" : input_ids ,
"max_new_tokens" : 512 ,
"do_sample" : True ,
"top_k" : 50 ,
"top_p" : 0.95 ,
"temperature" : 0.3 ,
"repetition_penalty" : 1.3 ,
"eos_token_id" : tokenizer . eos_token_id ,
"bos_token_id" : tokenizer . bos_token_id ,
"pad_token_id" : tokenizer . pad_token_id
}
generate_ids = model . generate ( ** generate_input )
text = tokenizer . decode ( generate_ids [ 0 ])
print ( text ) ชื่อแรกและทำความสะอาดข้อมูลการฝึกอบรมของคุณ [ไม่บังคับ]
เลือกที่จะเรียกใช้รหัสการทำความสะอาดแบบสุ่มหรือทำความสะอาดทั้งหมดและคุณสามารถปรับแต่งกฎของคุณใน ill_ocr_regex.txt
เรียกใช้ full_sample_extraction.py เพื่อรวมข้อมูลเข้ากับไฟล์
อ้างถึง Train-Chinese-tokenizer.ipynb สำหรับการฝึกอบรมคำศัพท์และคุณสามารถปรับเปลี่ยนรหัสตามความต้องการของคุณเอง หลังจากการฝึกอบรมเสร็จสิ้นให้ใส่รายการคำศัพท์ของคุณลงในไดเรกทอรี my-tokenizer ผสานกับโทเค็นของ LLAMA2 ดั้งเดิมด้วยวิธีต่อไปนี้
bash运行
'
Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
python incorporation.py
'
เรียกใช้ text.py เพื่อทดสอบเอฟเฟกต์คำศัพท์
รหัสการฝึกอบรมที่เก็บนี้ใช้ DeepSpeed เพื่อเร่งความเร็ว
如两机8卡:torchrun --nnodes 2 --nproc_per_node 8
for name, param in model.named_parameters():
if "model.embed_tokens" not in name:
param.requires_grad = False
else:
param.requires_grad = True
--load_in_kbits 设置量化,不为4或8则不启用量化
--bf16 | --fp16 启用bf16需要gpu硬件支持
如果出现OOM请在deepspeed_config_peft2.json配置中添加:
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
- การใช้สคริปต์ pretrain 2 pretrain-peft2.sh จะสร้างพารามิเตอร์ LORA คุณสามารถเรียกใช้ MERGE_LORA_LOW_MEM.PY สคริปต์ที่แก้ไขจาก Chinese-llama-Alpaca-2 เพื่อรวม
python merge_lora_low_mem.py
--base_model /root/LiteraryAlpaca2
--lora_model /root/autodl-tmp/LiteraryAlpaca2-lora
--output_type huggingface
--output_dir /root/autodl-tmp/LiteraryAlpaca2
แสดงการปรับเปลี่ยนส่วนบุคคลในชุดข้อมูลอย่างง่าย:

ใช้สคริปต์การแปลงในไดเรกทอรี SFT เพื่อแปลงชุดข้อมูลเป็นรูปแบบการฝึกอบรมที่จำเป็น ชุดข้อมูลต้นฉบับที่ใช้ในโครงการนี้ทั้งหมดอยู่ในรูปแบบ JSON โปรดแก้ไขสคริปต์การแปลงตามต้องการ:
รูปแบบไฟล์ JSON ที่สร้างขึ้นคือ:
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
ตัวอย่างเช่น:
{
"instruction": "下面是人类之间的对话与交流",
"input": "火锅 我 在 重庆 成都 吃 了 七八 顿 火锅",
"output": [
"哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !",
"不会 的 就是 好 油腻"
]
}
ไฟล์ CSV ที่แปลงแล้วมีคอลัมน์ของ "ข้อความ" แต่ละพฤติกรรมเป็นตัวอย่างการฝึกอบรมและแต่ละตัวอย่างการฝึกอบรมจะถูกจัดระเบียบลงในอินพุตของโมเดลในรูปแบบต่อไปนี้:
"<s>Human: "+...+"n</s><s>Assistant: "+...
ตัวอย่างเช่น:
<s>Human: 镇海雅乐学校二年级的小朋友到一条小路的一边植树.小朋友们每隔2米种一棵树(马路两头都种了树),最后发现一共种了11棵,这条小路长多少米.</s><s>Assistant: 根据方程式x=(11-1)*2解得:
20</s>
เรียกใช้ SFT/SFT-peft.sh ในไดเรกทอรี SFT เพื่อเริ่มการฝึกอบรม สำหรับรหัสการใช้งานเฉพาะโปรดดู SFT/SFT-peft.py


