literary alpaca2
1.0.0

語彙から微調整まで、これはあなたが必要とするすべてです
このリポジトリは、語彙から独自の語彙を構築し、リポジトリのコードの例を事前トレーニングと微調整するドックモデルを使用する方法を示します。著者のエネルギーが限られているため、TPUスクリプトにはバグがあります。これは参照用です。
| タイプ | 説明する |
|---|---|
| オンライン小説 | 高品質の長いテキストデータ |
| Math23k | 中国の数学の問題 |
| LCCC | 中国のオープンソースダイアログセット |
LCCCデータセットの使用方法:
from datasets import load_dataset
dataset = load_dataset("lccc", "base") # or "large"
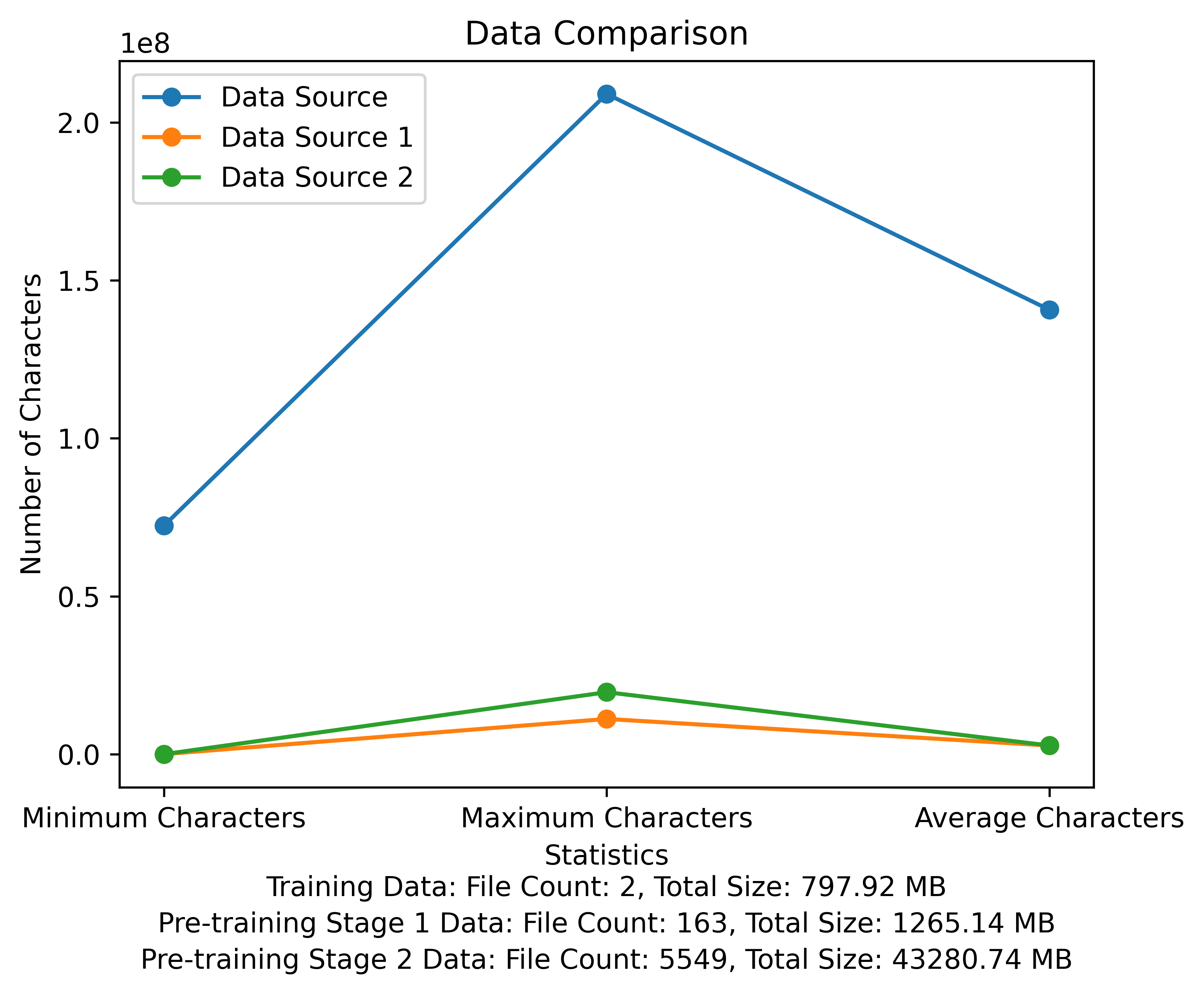
トレーニング前の段階の語彙リストとデータ比較図。この図は、各データソースのファイルの数と合計ファイルサイズを示しており、各ファイルの最小文字と最大文字と平均文字数を比較しています。
メタ公式ダウンロードリンク:https://huggingface.co/meta-llama
中国の事前に訓練されたモデル、LORAパラメーター、およびチャットモデルはすべて、顔を抱きしめるためにアップロードされています。現在、13Bモデルは13Bしかありません。
| カテゴリ | ?モデル名 | ベースモデル | アドレスをダウンロードしてください |
|---|---|---|---|
| トレーニング前 | taotie1/文学-alpaca2-13b | メタラマ/llama-2-13b-hf | モデルダウンロード |
| ロラ | taotie1/literature-alpaca2-13b-lora | taotie1/文学-alpaca2-13b | モデルダウンロード |
| カテゴリ | ?モデル名 | アドレスをダウンロードしてください |
|---|---|---|
| チャット | taotie1/reculation-alpaca2-13b-chat | モデルダウンロード |
requiress.txtのインストール環境依存関係によれば、デバイスに従ってトーチのインストールのバージョンを選択してください。
import torch
from transformers import AutoTokenizer , AutoModelForCausalLM
model = AutoModelForCausalLM . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , device_map = 'auto' , torch_dtype = torch . float16 , load_in_8bit = True )
model = model . eval ()
tokenizer = AutoTokenizer . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , use_fast = False )
tokenizer . pad_token = tokenizer . eos_token
input_ids = tokenizer ([ '<s>Human: 什么是计算机n </s><s>Assistant: ' ], return_tensors = "pt" , add_special_tokens = False ). input_ids . to ( 'cuda' )
generate_input = {
"input_ids" : input_ids ,
"max_new_tokens" : 512 ,
"do_sample" : True ,
"top_k" : 50 ,
"top_p" : 0.95 ,
"temperature" : 0.3 ,
"repetition_penalty" : 1.3 ,
"eos_token_id" : tokenizer . eos_token_id ,
"bos_token_id" : tokenizer . bos_token_id ,
"pad_token_id" : tokenizer . pad_token_id
}
generate_ids = model . generate ( ** generate_input )
text = tokenizer . decode ( generate_ids [ 0 ])
print ( text )ファーストネームとトレーニングデータのクリーニング[オプション]
ランダムクリーニングコードを実行するか、すべてをクリーニングするか、ill_ocr_regex.txtでルールをカスタマイズできます。
Full_sample_extraction.pyを実行して、データをファイルにマージします。
語彙トレーニングについては、Train-Chinese-Tokenizer.ipynbを参照してください。自分のニーズに応じてコードを変更できます。トレーニングが完了したら、語彙リストをMy-Tokenizerディレクトリに入れます。次の方法で元のllama2のトークナー剤とマージする
bash运行
'
Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
python incorporation.py
'
text.pyを実行して、語彙効果をテストします
このリポジトリトレーニングコードは、DeepSpeedを使用してスピードアップします
如两机8卡:torchrun --nnodes 2 --nproc_per_node 8
for name, param in model.named_parameters():
if "model.embed_tokens" not in name:
param.requires_grad = False
else:
param.requires_grad = True
--load_in_kbits 设置量化,不为4或8则不启用量化
--bf16 | --fp16 启用bf16需要gpu硬件支持
如果出现OOM请在deepspeed_config_peft2.json配置中添加:
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
-Pretrain Script 2を使用して、Pretrain-Peft2.shがLORAパラメーターを生成します。 Merge_lora_low_mem.pyスクリプトを実行して、中国語 - ラマ-Alpaca-2から変更してマージできます
python merge_lora_low_mem.py
--base_model /root/LiteraryAlpaca2
--lora_model /root/autodl-tmp/LiteraryAlpaca2-lora
--output_type huggingface
--output_dir /root/autodl-tmp/LiteraryAlpaca2
単純なデータセットへのパーソナライズされた調整の表示:

SFTディレクトリの変換スクリプトを使用して、データセットを必要なトレーニング形式に変換します。このプロジェクトで使用されている元のデータセットはすべてJSON形式です。必要に応じて変換スクリプトを変更してください。
生成されたJSONファイル形式は次のとおりです。
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
例えば:
{
"instruction": "下面是人类之间的对话与交流",
"input": "火锅 我 在 重庆 成都 吃 了 七八 顿 火锅",
"output": [
"哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !",
"不会 的 就是 好 油腻"
]
}
変換されたCSVファイルには「テキスト」の列が含まれ、各動作はトレーニングの例であり、各トレーニングの例は次の形式でモデルの入力に編成されます。
"<s>Human: "+...+"n</s><s>Assistant: "+...
例えば:
<s>Human: 镇海雅乐学校二年级的小朋友到一条小路的一边植树.小朋友们每隔2米种一棵树(马路两头都种了树),最后发现一共种了11棵,这条小路长多少米.</s><s>Assistant: 根据方程式x=(11-1)*2解得:
20</s>
SFT/SFT-PEFT.SHをSFTディレクトリで実行して、トレーニングを開始します。特定の実装コードについては、SFT/SFT-Peft.pyを参照してください


