literary alpaca2
1.0.0

От словарного запаса до тонкой настройки, это все, что вам нужно
Этот репозиторий покажет, как создать свой собственный словарь из словарного запаса, и использовать док-модель дока, предварительную тренировку, и настраивать примеры кода в репозитории в основном обучаются на основе версии LLAMA2, предоставляя обучающие примеры для GPU и TPU. Из -за ограниченной энергии автора есть ошибки в скрипте TPU, который предназначен только для справки.
| тип | описывать |
|---|---|
| Онлайн -романы | Высококачественные длинные текстовые данные |
| Math23k | Китайские проблемы математики |
| LCCC | Китайский набор диалога с открытым исходным кодом |
Как использовать набор данных LCCC:
from datasets import load_dataset
dataset = load_dataset("lccc", "base") # or "large"
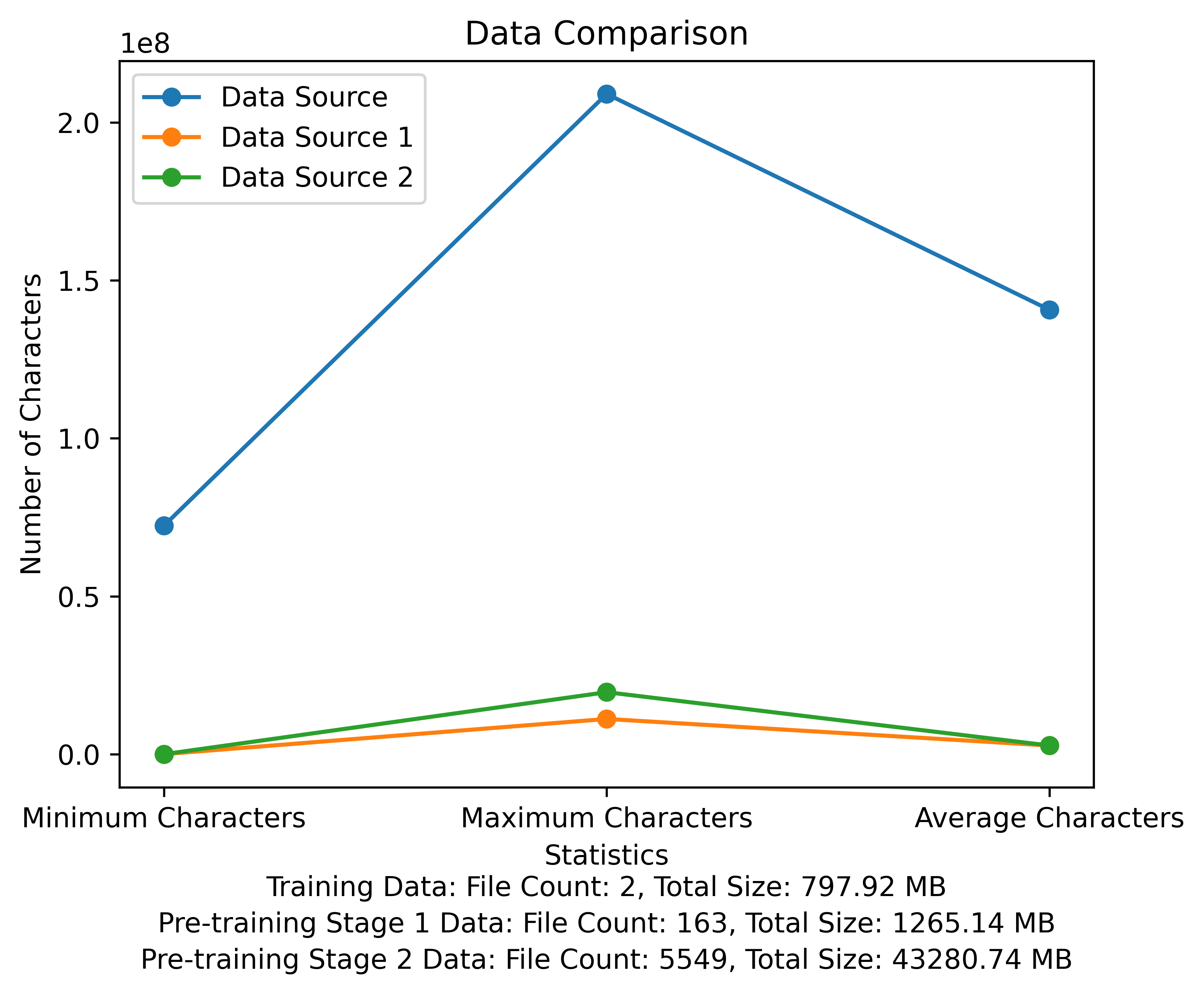
Список словарного запаса и диаграмма сравнения данных на стадии предварительного обучения. На рисунке показано количество файлов и общих размеров файлов каждого источника данных, и сравнивает минимальные и максимальные символы и среднее количество символов в каждом файле:
Meta Official Download Ссылка: https://huggingface.co/meta-llama
Китайская предварительно обученная модель, параметры LORA и модели чата были загружены на обнимающееся лицо. В настоящее время есть только 13b модели.
| категория | ? Модель название | Базовая модель | Скачать адрес |
|---|---|---|---|
| Предварительное обучение | TAOTIE1/Литературно-альпака2-13B | Метама/лама-2-13b-HF | Модель скачать |
| Лора | TAOTIE1/Литературно-альпака2-13B-лора | TAOTIE1/Литературно-альпака2-13B | Модель скачать |
| категория | ? Модель название | Скачать адрес |
|---|---|---|
| Чат | TAOTIE1/Литературно-альпака2-13B-чат | Модель скачать |
Согласно зависимостям среды установки.
import torch
from transformers import AutoTokenizer , AutoModelForCausalLM
model = AutoModelForCausalLM . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , device_map = 'auto' , torch_dtype = torch . float16 , load_in_8bit = True )
model = model . eval ()
tokenizer = AutoTokenizer . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , use_fast = False )
tokenizer . pad_token = tokenizer . eos_token
input_ids = tokenizer ([ '<s>Human: 什么是计算机n </s><s>Assistant: ' ], return_tensors = "pt" , add_special_tokens = False ). input_ids . to ( 'cuda' )
generate_input = {
"input_ids" : input_ids ,
"max_new_tokens" : 512 ,
"do_sample" : True ,
"top_k" : 50 ,
"top_p" : 0.95 ,
"temperature" : 0.3 ,
"repetition_penalty" : 1.3 ,
"eos_token_id" : tokenizer . eos_token_id ,
"bos_token_id" : tokenizer . bos_token_id ,
"pad_token_id" : tokenizer . pad_token_id
}
generate_ids = model . generate ( ** generate_input )
text = tokenizer . decode ( generate_ids [ 0 ])
print ( text ) Имя и очистите данные обучения [необязательно]
Выберите запуск кода случайной очистки или очистить все это, и вы можете настроить свои правила в ill_ocr_regex.txt.
Запустите full_sample_extraction.py, чтобы объединить данные в файл.
Обратитесь к Train-Chinese-tokenizer.ipynb для обучения словарным запасам, и вы можете изменить код в соответствии с вашими собственными потребностями. После завершения обучения поместите свой список словарного запаса в каталог My-Tokenizer. Слияние с токенизатором оригинального Llama2 следующим образом
bash运行
'
Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
python incorporation.py
'
Запустите Text.py, чтобы проверить эффект словарного запаса
Этот код обучения репозитория использует DeepSpeed для ускорения
如两机8卡:torchrun --nnodes 2 --nproc_per_node 8
for name, param in model.named_parameters():
if "model.embed_tokens" not in name:
param.requires_grad = False
else:
param.requires_grad = True
--load_in_kbits 设置量化,不为4或8则不启用量化
--bf16 | --fp16 启用bf16需要gpu硬件支持
如果出现OOM请在deepspeed_config_peft2.json配置中添加:
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
- Использование Script 2 Pretrain-Peft2.sh 2 предварительно-PEFT2.SH будет генерировать параметры LORA. Вы можете запустить скрипт merge_lora_low_mem.py, измененный из китайской лама-альпака-2, чтобы слияние
python merge_lora_low_mem.py
--base_model /root/LiteraryAlpaca2
--lora_model /root/autodl-tmp/LiteraryAlpaca2-lora
--output_type huggingface
--output_dir /root/autodl-tmp/LiteraryAlpaca2
Отображение персонализированных настройки к простым наборам данных:

Используйте скрипт преобразования в каталоге SFT, чтобы преобразовать набор данных в требуемый формат обучения. Первоначальные наборы данных, используемые в этом проекте, находятся в формате JSON. Пожалуйста, измените сценарий конверсии по мере необходимости:
Сгенерированный формат файла JSON:
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
Например:
{
"instruction": "下面是人类之间的对话与交流",
"input": "火锅 我 在 重庆 成都 吃 了 七八 顿 火锅",
"output": [
"哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !",
"不会 的 就是 好 油腻"
]
}
Преобразованный файл CSV содержит столбец «текста», каждое поведение является примером обучения, и каждый пример обучения организован на ввод модели в следующем формате:
"<s>Human: "+...+"n</s><s>Assistant: "+...
Например:
<s>Human: 镇海雅乐学校二年级的小朋友到一条小路的一边植树.小朋友们每隔2米种一棵树(马路两头都种了树),最后发现一共种了11棵,这条小路长多少米.</s><s>Assistant: 根据方程式x=(11-1)*2解得:
20</s>
Запустите sft/sft-peft.sh в каталоге SFT, чтобы начать обучение. Для конкретного кода реализации см. SFT/SFT-PEFT.PY


